
در درسِ گذشته در مورد تِستهای آماری و ایدهی کلیِ آنها در تشخیصِ دادههای پَرت سخن گفتیم. به صورت خلاصه گفتیم این تستهای آماری (Statistical Tests) فرض میکنند دادهها از یک توزیعِ احتمالی-مثلا یک الگوی مشخص مانند گوسی- پیروی کرده و سپس آن دادههایی را که از این الگو (توزیعِ احتمالی) پیروی نکنند به عنوانِ دادهی پَرت در نظر میگیرند. در این درس میخواهیم z-score که یکی از این روشها است-و به نظر معروفترین روش هم میرسد- را با یکدیگر یاد بگیریم.
تستهای آماری (Statistical Test) جهت تشخیص دادههای پرت
تستهای آماری، از سادهترین و در عین حال پرکاربردترین آزمایشات، جهت تشخیصِ یک دادهی پَرت میباشد. فرض کنید شما معلم هستید و معمولاً انتظار دارید ۵۰درصد دانشجویان در یکی از کلاسهایتان نمرهی بالای ۱۵ بگیرند، ۴۰درصد از آنها نمرهای بین ۱۲ تا ۱۵ گرفته و ۱۰درصد آنها هم نمرهای بین ۱۰ تا ۱۲ بگیرند. پس در واقع شما انتظار ندارید که دانشآموزی، مثلاً نمرهی ۳از شما گرفته باشد. اگر چنین باشد، انتظارِ شما برآورده نشده و این دانشآموز یک نمرهی غیر طبیعی به دست آورده است و بایستی بررسی شود که چرا این نمره را آورده است. در واقع این دانشآموز اینجا یک دادهی پَرت بوده است زیرا انتظار شما را برآورده نکرده است.
ادامه خواندن “تستهای آماری (Statistical Test) جهت تشخیص دادههای پرت”
کاربرد یافتن دادههای پرت (Outlier Detection) در دادهکاوی
در درسِ دادههای پرت از دورهی آنالیزِ اکتشافی داده و درسِ دادههای نویزدار از دورهی پیشپردازش دادهها، با این مفهوم آشنا شدیم و دیدیم که یک سری از دادهها وجود دارند که با توجه به ویژگیهای مختلفِ مجموعهی داده، با بقیهی دادهها تفاوت میکنند. شکل زیر را به یاد بیاورید:
ادامه خواندن “کاربرد یافتن دادههای پرت (Outlier Detection) در دادهکاوی”
انتخاب نمونه (Instance Selection) در پیش پردازش دادهها
معمولاً در بحثِ پردازش دادهها و دادهکاوی، یکی از محدودیتها، محدودیت در منابع سخت افزاری است. برای مثال فرض کنید، ۵۰ گیگابایت داده در اختیار داریم ولی مقدار حافظهی موقتِ (RAM) موجود، ۴ گیگابایت است. یکی از راهکارها، برای حل این دست مسائل، کاهش دادن دادهها است. در درسِ قبل دیدیم که چگونه با حذفِ یک ویژگی (یک بُعد)، حجمِ دادهها کاهش پیدا میکند. در این درس میخواهیم ببینیم که چگونه به جای حذفِ یک ویژگی، نمونههای مختلف رامیتوان از بین دادهها کنار گذاشت.
ادامه خواندن “انتخاب نمونه (Instance Selection) در پیش پردازش دادهها”
انتخاب ویژگی (Feature Section) و کاهش ابعاد
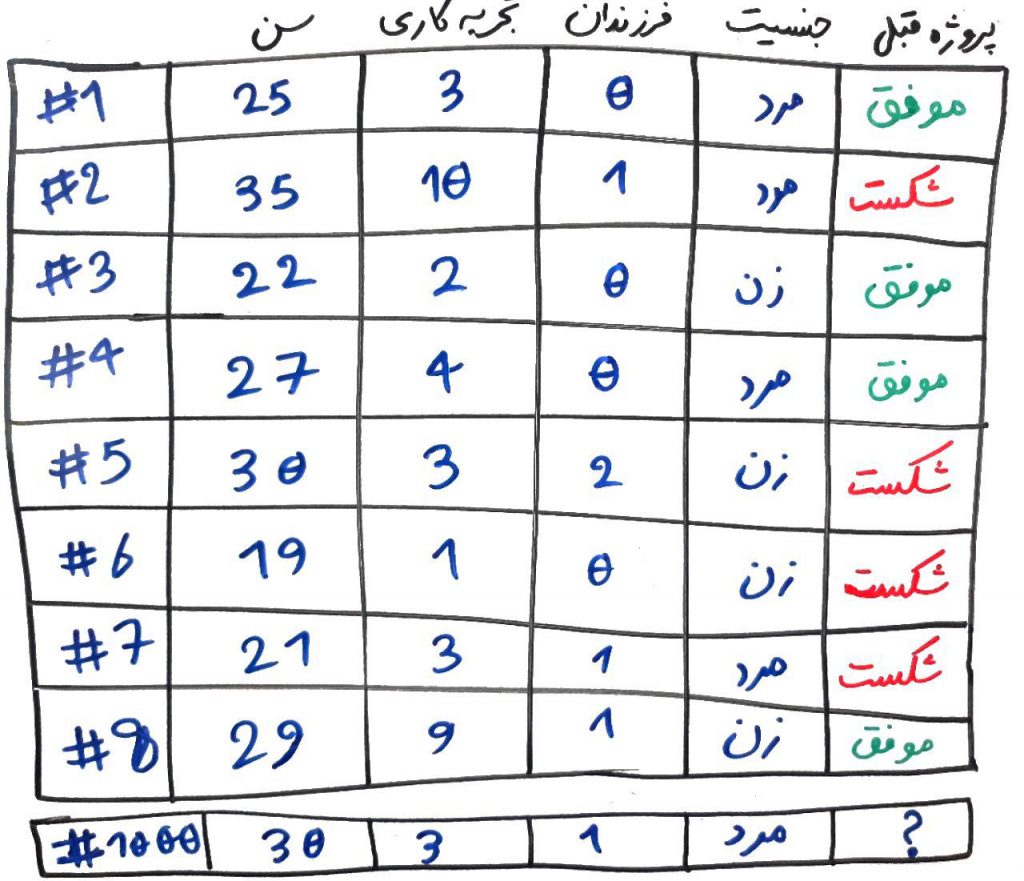
فرض کنید مدیرِ یک مجموعه هستید و میخواهید با توجه به ویژگیهای یکی از کارکنانِ خود، وظیفهای را به او محول کنید (مثلاً او را مدیرِ یک پروژه کنید). ولی این شخص تا به حال پروژهای برای شما انجام نداده است. برای اینکار ویژگیهای مختلفی از کارکنانِ قبلیِ خود را جمعآوری کرده و آنها را در جدولی مانندِ جدول زیر رسم میکنید:
تشخیص دادههای پرت و دارای نویز (Noise) و راهکار مقابله با آنها
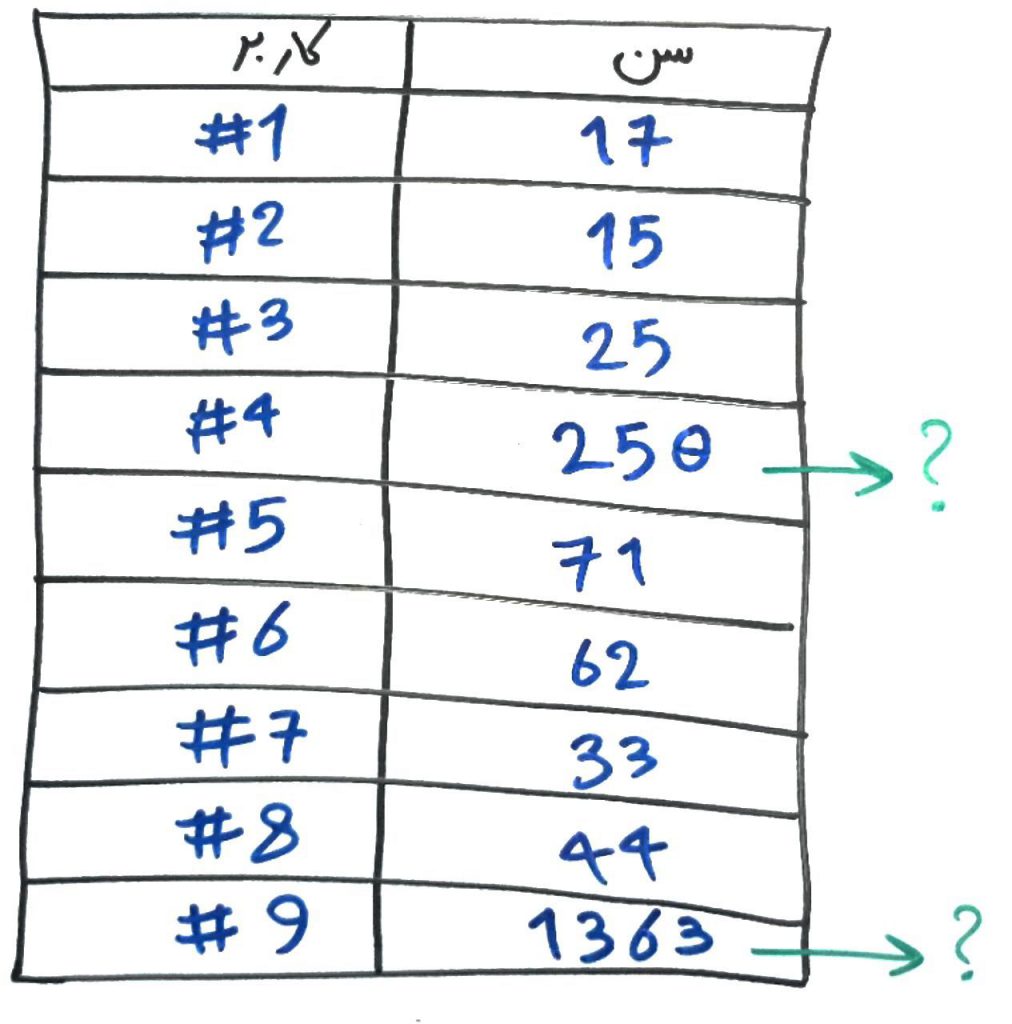
دادههای پرت و دادههایی که دارای نویز (noise) هستند، در بسیاری از مجموعهها، دیده میشوند. فرض کنید شما مدیرِ یک وبسایتِ فروشگاهی هستید و میخواهید سنِ کاربران خود را تحلیل کنید. مثلاً اینکه افراد در بازهی سنیِ مختلف، بیشتر به کدام محصولات تمایل نشان میدهند. برای اینکار در هنگام خرید، سنِ خریدار را از او دریافت میکنید. آیا مطمئن هستید که افراد معمولاً سنِ خود را در بازهی ۰ تا ۱۰۰ سال وارد میکنند؟ برای مثال شخصی ممکن است سهواً سنِ خود را به جای ۲۵ سال، ۲۵۰ سال درج کند و یا شخصی به جای اینکه سن خود را درج کند، سهواً سالِ تولد خود را وارد نماید! به این دست از دادهها که معمولاً با بقیهی دادهها ناسازگار هستند دادههای پرت (outliers) میگویند و مجموعهی داده را دارای نویز (noise) میدانند. در این درس میخواهیم ببینیم چه راهکارهایی برای مقابله با این دست از دادهها وجود دارد.
ادامه خواندن “تشخیص دادههای پرت و دارای نویز (Noise) و راهکار مقابله با آنها”
دادههای گمشده (Missing Values) و راهکارهای مقابله با آنها
فرض کنید مدیرِ یک اداره هستید و در روز عدهی کثیری از مراجعهکنندگان به ادارهی شما مراجعه میکنند. در این مراجعه به هر فرد یک فُرمِ دریافت مشخصات داده میشود و از او خواسته میشود تا اطلاعاتی مانند نام، جنسیت، سن، کدپستی، نامِ پدر، شمارهی شناسنامه، آدرس منزل، تعداد دفعات مراجعهی قبلی، و دلیلِ مراجعهی خود را در آن فُرم بنویسد تا بعداً عملیاتِ پردازشی بر روی دادهها انجام شود (مثلاً با عملیات متنکاوی-text mining- متوجه شوید که معمولاً مراجعهکنندگان به چه دلایلی به اداره مراجعه میکنند یا اینکه معمولاً این مراجعهکنندگان ساکن کدام محدودهی شهر-با توجه به کدپستی- هستند). با این تفاسیر آیا تضمین میکنید که تمامِ مراجعهکنندگان، اطلاعاتِ خود را کامل وارد کنند؟ مثلاً اگر شخصی کدپستیِ خود را فراموش کرده باشد چه؟ در اینجا طبیعتاً دادهها ناقص است و در واقع بعضی از دادهها وجود ندارند. به این دست از دادهها، missing values یا دادههای گم شده یا دادههای مفقود میگویند که موردِ بحثِ این درس است.
ادامه خواندن “دادههای گمشده (Missing Values) و راهکارهای مقابله با آنها”
منظور از متغیر وابسته (Dependent) و مستقل (Independent)
در بسیاری از مراجعِ دادهکاوی، مخصوصاً آنهایی که پایهی آماریِ بیشتری داشته باشند، از عباراتی مانندِ متغیر وابسته و متغیرِ غیر وابسته استفاده میکنند. در این درس میخواهیم به این دو مفهوم بپردازیم، کاربرد و تفاوتِ این دو دسته متغیر را در حوزهی علوم داده و یادگیری ماشین درک کنیم.
ادامه خواندن “منظور از متغیر وابسته (Dependent) و مستقل (Independent)”
تبدیل دادهها (Data Transformation) به فُرمت قالب فهم برای الگوریتم دادهکاوی
اکثرِ الگوریتمهای دادهکاوی، نیاز دارند تا دادههای عددی را دریافت کنند و ساختارِ یادگیریِ آنها بر اساسِ یادگیری از ماتریسهای عددی است. در درسِ طبقهبندی دیدید که چگونه میتوان یک سری ویژگی را به صورت ماتریس ساخت و به الگوریتمِ طبقهبندی داد. اما یادمان باشد که همیشه دادهها به صورتِ عددی آماده نیستند و بعضاً نیاز دارند تا به فرمتِ دلخواهِ الگوریتم (یعنی همان فرمتِ ماتریسِ عددی) تبدیل شوند. این دست از دادهها بایستی قبل از تزریق به الگوریتم، به فُرمتِ مناسب تبدیل (transform) شوند. روشهای تبدیل داده بسیار گسترده و متنوع است و در این درس، یکی از آنها را با هم مرور میکنیم.
ادامه خواندن “تبدیل دادهها (Data Transformation) به فُرمت قالب فهم برای الگوریتم دادهکاوی”
نرمال کردن دادهها (Data Normalization) و انواع آن
مسابقاتِ کشتی را تماشا کردهاید؟ در مسابقات کشتی هیچگاه یک فرد با وزن ۹۰ کیلوگرم را با فردی با وزن ۱۲۰ کیلوگرم رو در رو نمیکنند. در واقع هر شخص باید در محدودهی وزنِ خود کشتی بگیرد. در دادهها نیز شما نمیتوانید یک مجموعهی داده که مثلاً در بازهی بین ۰ تا ۲۰ متغیر هستند را با مجموعهی دادهای که در بازهی بین ۰ تا ۱۰۰۰۰ قرار دارد، مقایسه کنید. در واقع این دو مجموعهی داده بایستی ابتدا هم وزن شوند تا تاثیرِ یکی بیشتر از دیگر نباشد و به اصطلاح fair و منصف باشند.
ادامه خواندن “نرمال کردن دادهها (Data Normalization) و انواع آن”