

بسیاری از افراد (حتی افراد متخصص در حوزهی هوش مصنوعی یا علوم داده) ممکن است تفاوت دقیق واژههای مورد استفاده در حوزهی هوش مصنوعی و علوم داده را ندانند. دلیل آن هم شاید این باشد که واقعاً مرز روشنی بین این تعاریف وجود ندارد و در بسیار از مواقع این حوزهها با یکدیگر ترکیب میشوند. با این حال در این درس قصد داریم تا حد ممکن تفاوت این عبارات را با یکدیگر بیاموزیم و کاربرد هر یک را ببینیم.
طبق تحقیقی که توسط گروهی از علاقهمندان به این حوزه در سال ۲۰۱۸ انجام شد، نزدیک به ۴۰ درصد شرکتهای استارتاپی در اروپا که ادعا کرده بودند از هوش مصنوعی در کارهای خود استفاده میکنند، واقعاً این کار را انجام نمیدادند و این خود نشان میدهد که شاید بسیاری از افراد (حتی افراد شاغل در حوزهی آیتی) تفاوت مفاهیم را در این زیر حوزهها درک نکرده باشند.
برای شروع به شکل زیر نگاه کنید:
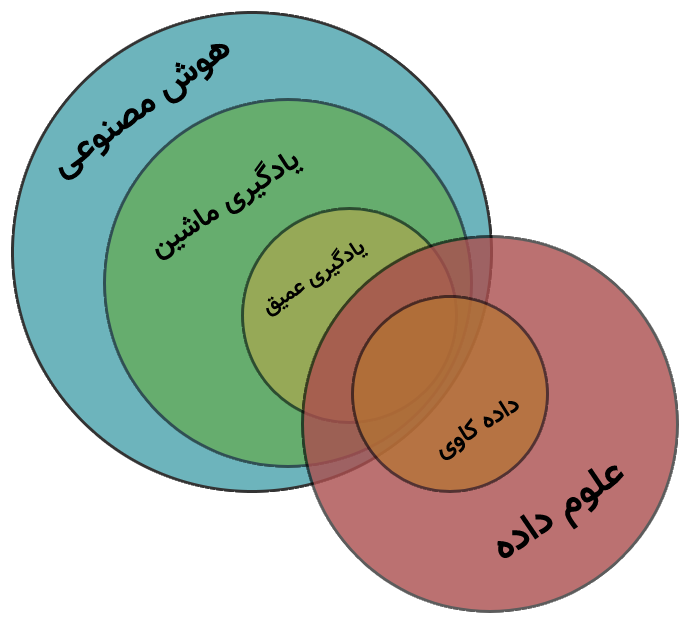
ابتدا از هوش مصنوعی (artificial intelligence) شروع میکنیم. طبق یک تعریف معروف، هوش مصنوعی یک مفهوم کلی است که به کامپیوتر این ویژگی را میدهد تا بتواند مانند انسان فکر کرده و عمل کند. پس هوش مصنوعی یک ایدهی کلی است که در برگیرندهی بسیاری از مفاهیم دیگر شده است.
حال یادگیری ماشین (machine learning)، قسمت کاربردی هوش مصنوعی است که با کمک آن میتوان به کامپیوتر از روی دادهها، الگوها (patterns) را یاد داد. در واقع کامپیوتر با یادگیری ماشین میتواند یادگیری را از روی دادهها انجام دهد و مسئلهای که برایش تعریف کردهایم را حل کند.
یادگیری عمیق (deep learning)، به مجموعهای از الگوریتمهای یادگیری ماشین گفته میشود که غالباً میتوانند الگوهای پیچیدهتری را از میان دادهها کشف کنند. در واقع این دسته از الگوریتمها مسائلِ سختتری را در حوزهی یادگیری ماشین و دادهکاوی میتوانند حل کنند. همانطور که در شکل بالا مشاهده میکنید، زیر مجموعهی یادگیری ماشین بوده و اشتراکهایی با دادهکاوی دارند.
علوم داده (data science) به مجموعهی روشها و فعالیتهایی گفته میشود که بر روی دادهها انجام میدهیم. در علوم داده، تحلیل اولیه دادهها، پیشپردازش دادهها و تفسیر و نمایش دادهها وجود دارد. واکشی دادهها و ذخیرهسازی آنها نیز جزو فعالیتهای علوم داده قرار میگیرد.
اما شاید سختترین بخش، بیان تفاوت دادهکاوی (data mining) و یادگیری ماشین (machine learning) باشد. همانطور که در شکل مشاهده میکنید این دو نقاط مشترک زیادی با یکدیگر دارند ولی شاید اساسیترین تفاوت بین آنها این باشد که در دادهکاوی، دخالت انسان معمولاً بیشتر است. یعنی دادهکاوی بدون تحلیل و کمک یک انسان معمولاً انجام ناپذیر است. این در حالیست که یادگیری ماشین میتواند به صورت خودکار (self-learning) نیز کارها را انجام دهد.
البته بخشهای دیگر مانند بهینهسازیها (optimizations)، یادگیری تقویتی (reinforcement learning) و کلان داده (big data) نیز وجود دارد که هر کدام میتوانند زیر مجموعهی یک قسمت از شکل بالا باشند. برای مثال الگوریتمهای بهینهسازی و یادگیری تقویتی را میتوان داخل قسمت هوش مصنوعی قرار داد و کلان داده را نیز میتوان جزو زیر دستههای علم داده گذاشت.
در کل توانایی تفکیک مباحث و زیر حوزههای مباحث مرتبط با علوم داده و هوش مصنوعی، میتواند دید بهتری از بخشهای مختلف این حوزه به ما بدهد که در این درس سعی کردیم به بیان ساده این تفاوتها را درک کنیم.

- ۱ » دادهکاوی (Data mining) چیست؟
- ۲ » یادگیری ماشین (Machine Learning) چیست؟
- ۳ » تفاوت هوش مصنوعی، یادگیری ماشین، دادهکاوی، یادگیری عمیق و علم داده
- ۴ » طبقهبندی (Classification) چیست؟
- ۵ » خوشهبندی (Clustering) چیست؟
- ۶ » تفاوت طبقهبندی (Classification) و خوشهبندی (Clustering)
- ۷ » منظور از دادههای آموزشی (Training Sets) در طبقهبندی چیست؟
- ۸ » سیستم توصیه گر (Recommendation System) چیست؟
- ۹ » کاربرد دادهکاوی و یادگیری ماشین در پردازش متن (Text Processing)
- ۱۰ » معرفی چند نرم افزار کاربردی برای عملیات دادهکاوی
- ۱۱ » ویژگی (Feature) یا همان بُعد (Dimension) در دادهکاوی چیست؟
- ۱۲ » بررسی چند الگوریتم یادگیری ماشین (Machine Learning)
- ۱۳ » یادگیری دستهای (Batch Learning) و یادگیری برخط (Online Learning)
- ۱۴ » یادگیری فعال (Active Learning) در یادگیری ماشین
- ۱۵ » انتخاب ویژگی (Feature Selection) چیست؟
- ۱۶ » تفاوت داده ساختاریافته (Structured) با غیرساختاریافته (Unstructured) چیست؟
- ۱۷ » منظور از متغیر وابسته (Dependent) و مستقل (Independent)
- ۱۸ » مجموعه دادههایی با ابعاد زیاد (High Dimensional)
- ۱۹ » مجموعه دادهی نامتوازن (Imbalance) چیست؟
- ۲۰ » فرآیند کریسپ (CRISP) جهت انجام پروژههای دادهکاوی
- ۲۱ » رانش یا گذار در دادهها (Data Drift)
عالی