

در ریاضیات و محاسباتِ عددی، وقتی بخواهند اندازهی یک بردار (vector) یا ماتریس (matrix) را محاسبه کنند از عبارتِ نُرم یا همان norm استفاده میکنند. نُرمِ یک بردار یا ماتریس، کاربردِ فراوانی مخصوصاً در یادگیری ماشین و شبکههای عصبی عمیق (deep neural network) دارد. در این درس قصد داریم به بررسی چند روش محاسبهی نُرمها بپردازیم تا اگر در کتاب یا مقالهای به عبارتِ نُرم برخوردیم معنیِ آن را بدانیم.
نحوهی محاسبهی نرم (norm) متفاوت است، به همین دلیل normها اسامی مختلفی دارند. مثلا نُرمِ اُقلیدوسی یا L1 Norm و یا L2 Norm که ممکن است در بسیاری از مراجع دادهکاوی و یادگیری ماشین دیده باشید، از پرکاربردترین نُرمها هستند. برای آشنایی با آنها ابتدا به یکی از معروفترین نُرمها که همان نُرمِ اُقلیدوسی یا L2 norm است میپردازیم. شکل زیر را نگاه کنید:
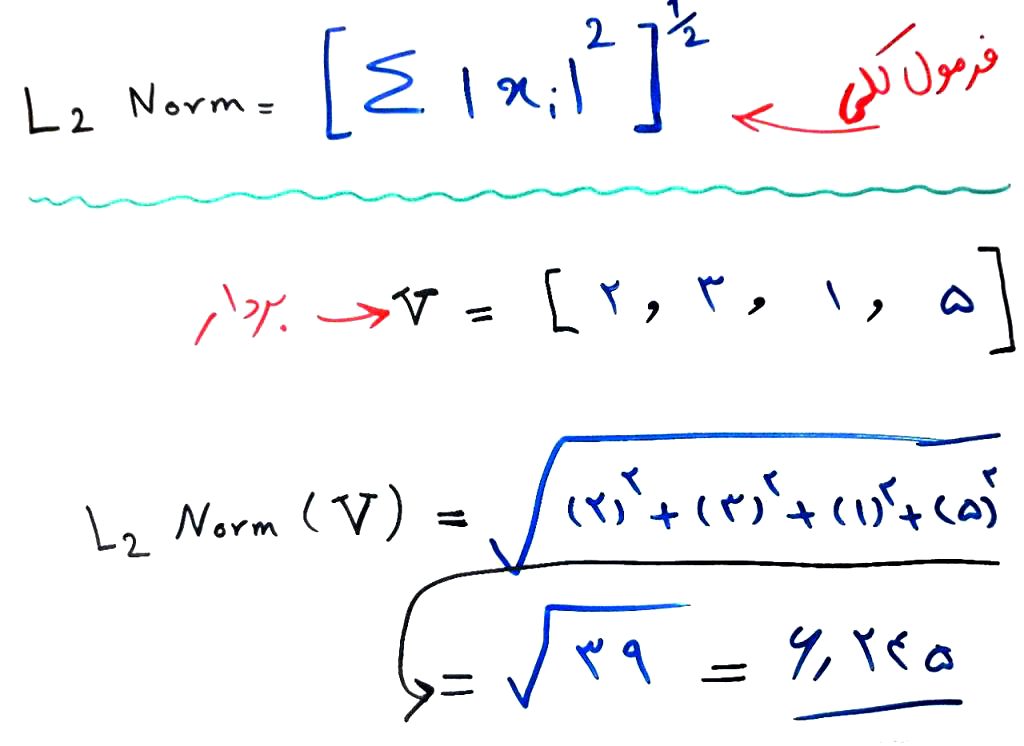
همانطور که در شکل میبینید ما یک بردار (vector) داریم و هر کدام از عناصرِ آن را به توان ۲ رساندیم و با هم جمع کردیم، سپس از مجموعِ آنها رادیکال گرفتیم و در نهایت به یک عدد (۶.۲۴۵) رسیدیم. این عدد در واقع نشان دهندهی بزرگیِ این بردار است. پس در واقع میتوان گفت نُرم، یک نوع تخمین برای به دست آوردن بزرگی بردار است.
اجازه بدهید یک نُرمِ معروفِ دیگر را با هم مشاهده کنیم. نُرمِ بیشنیه یا maximum norm که بزرگترین عنصرِ یک بردار را نمایش میدهد. مانند شکل زیر:

همانطور که مشاهده کردید، بزرگترین مقدار برای بردارِ موجود در شکل، عدد ۵ است که این همان max norm برای این بردار میشود.
یک نُرمِ معروف دیگر L1 norm است. برای محاسبهی این نُرم، ابتدا از تمامیِ اعدادْ قدرِ مطلق میگیریم (تمامیِ آنها را مثبت میکنیم) و سپس آنها را با هم جمع میکنیم. مثلا در بردارهای شکلِ بالا، مقدار L1 norm برابر ۱۱ میشود.
در مثالهای بالا، ما نُرمِ بردار (vector) را محاسبه میکردیم. میتوان مقدارِ نُرم را برای ماتریس هم محاسبه کرد. یکی از معروفترین نُرمها برای ماتریس، نُرم فروبنیوس (frobenius norm) است که چیزی شبیه به L2 norm برای بردارهاست. به شکل زیر نگاه کنید:
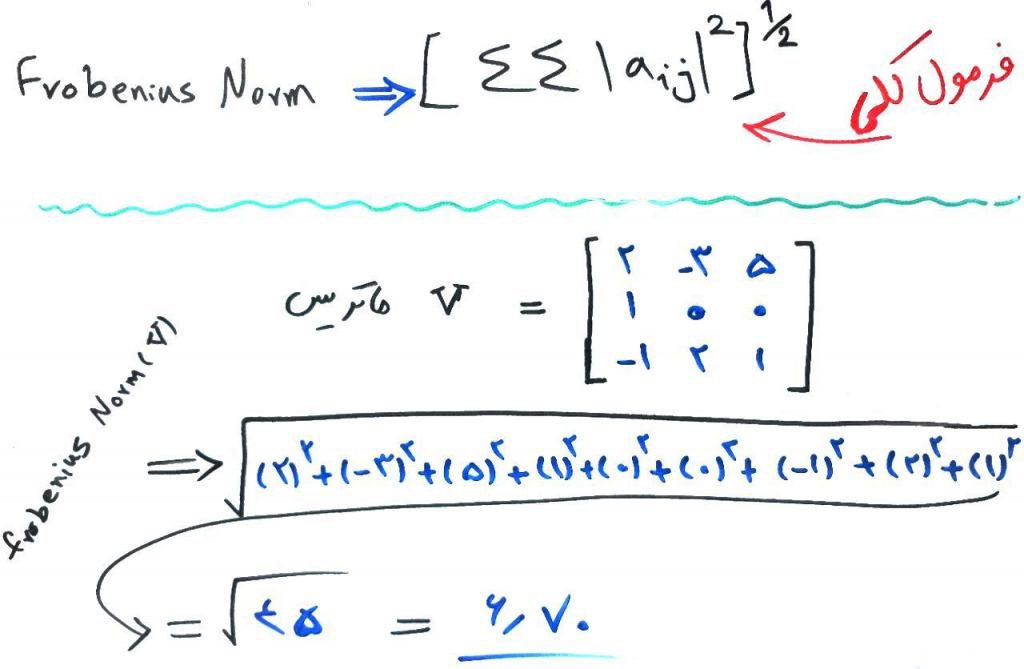
فرمول ساده است، تمامی اعداد داخل ماتریس (هر سطر به ازای هر ستون) را به توان ۲ میرسانیم و با یکدیگر جمع میکنیم. سپس از آنها رادیکال میگیریم. در واقع اینجا هم یک ماتریس را به یک عدد تبدیل کردیم. با این کار به صورت تخمینی میتوانیم متوجه شویم که اندازهی یک ماتریس چقدر بزرگ است و یا اینکه ماتریسها را با هم مقایسه کنیم.
دو نُرمِ دیگر برای ماتریسها نیز از اهمیت ویژهای برخوردار هستند. نُرم بیشنیهی جمعِ مطلقِ سطرها (max absolute row sum)! و نرم بیشنیهی جمعِ مطلقِ ستونها (max absolute column sum)! که محاسبهی آنها بسیار ساده است. برای مثال برای اولی (یعنی بیشینهی جمع مطلق سطرها)، جمعِ قدر مطلقِ مقادیرِ هر کدام از سطرها را محاسبه میکنیم (برای شکل بالا میشود: ۱۰، ۱، ۴) و سپس بیشترین مقدار آنها را به عنوان max absolute row sum norm به دست میآوریم (که برای شکل بالا برابر ۱۰ میشود)
همانطور که مشاهده کردید، نُرم (norm)های مختلفی داریم که هر کدام میتوانند برای مسئلهای به کار گرفته شوند. اگرچه که همهی آنها یک هدف دارند و آن هدف به دست آوردن تخمینی از بزرگیِ ماتریس یا بردار است. نرمها کاربرد مختلفی در جبرخطی و در نتیجه در یادگیری ماشین، داده کاوی و یادگیری عمیق دارند.

- ۱ » عدد (Scalar)، بردار (Vectors)، ماتریس (Matrix) و تنسور (Tensor) چیست؟
- ۲ » ماتریسها و کاربرد آنها در دادهکاوی و یادگیری ماشین
- ۳ » نرم (Norm) بردار یا ماتریس چیست؟
- ۴ » انواع ماتریس و ویژگیهای مختلف آنها
- ۵ » چرا ماتریسها در علوم داده مهم هستند؟
- ۶ » معیارهای فاصله (Distance Measures) در یادگیری ماشین
- ۷ » بردار ویژه (Eigen Vector) و مقدار ویژه (Eigen Value) برای یک ماتریس
- ۸ » Singular Value Decomposition یا همان SVD در ماتریس چیست؟
- ۹ » ماتریس کواریانس (Covariance) و ماتریس همبستگی (Correlation) چیست؟
- ۱۰ » آنالیز مولفه اصلی (Principal Component Analysis) یا همان PCA چیست؟
- ۱۱ » دستگاه معادلات خطی (System of Linear Equations) در ماتریسها
بسیار عالی خدا خیرتون بده
دستتون درد نکنه. ممنون و متشکر
ممنونم؛ چقدر واضح و قابل فهم توضیح دادید. عالی بود. سپاسگزارم
مرسی واقعا مفید بود
مفید بود