

اگر دورهی خوشهبندی و الگوریتمهای متخلفِ آن را دنبال کرده باشید، احتمالاً الگوریتم DBSCAN برایتان آشنا باشد. این الگوریتم قادر بود که غلظت و تجمّع را در نقاطِ مختلف شناسایی کرده و به این ترتیب گروههای متفاوت را در بینِ دادهها کشف کند. اگر با این الگوریتم آشنایی بیشتری داشته باشید، متوجه میشوید که DBSCAN علاوه بر پیدا کردنِ خوشهها، میتواند دادههایی را که در هیچ خوشهای قرار نمیگیرند نیز کشف کند. میتوانید دوباره نگاهی به درسِ خوشهبندی DBSCAN در دورهی خوشهبندی بیندازید.
البته این درس بیشتر برای تکمیل سرفصلهای بحثِ دادههای پَرت قرار داده شده و میخواهیم مروری بر درسِ الگوریتمِ DBSCAN این بار با نگاهِ دادههای پَرت داشته باشیم.
شکل زیر را از درسِ DBSCAN به یاد بیاوید (درس ویژگی چیست را نیز خوانده باشید):
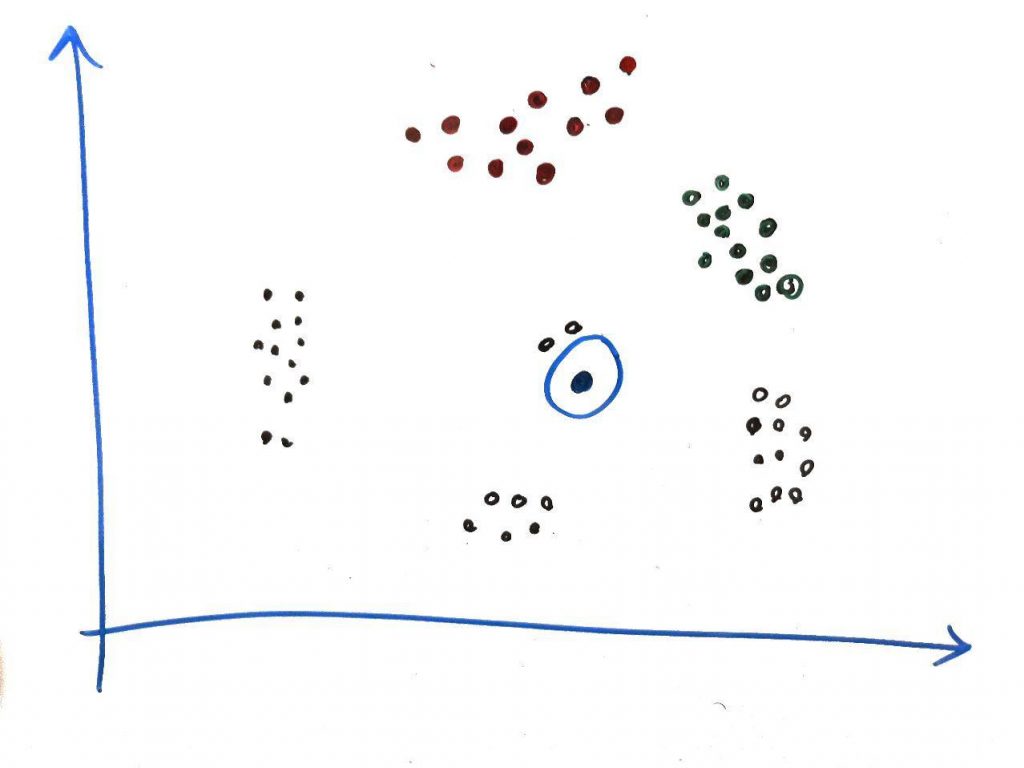
گفتیم که الگوریتمِ خوشهبندیِ DBSCAN میتواند گروهها را بر اساسِ غلظت دستهبندی کند و این دستهها در کنارِ هم خوشهها را تشکیل میدهند. اما نگاهی به نقطهی مشخص شده در بالا بیندازید. الگوریتمی مانندِ DBSCAN این نقطه را به عنوان دادهای که به هیچ گروهی (بر اساس غلظت و تراکم) متصل نیست، یعنی یک دادهی پَرت (outlier) میشناسد. همانطور که نگاه میکنید این نقطه در یک منطقهی خلوت قرار دارد که تراکمِ دادهها در آنجا کم است. پس به صورتِ شهودی نیز میتوان دید که این نقطه یک دادهی پَرت است.

- ۱ » کاربرد یافتن دادههای پرت (Outlier Detection) در دادهکاوی
- ۲ » تستهای آماری (Statistical Test) جهت تشخیص دادههای پرت
- ۳ » محاسبهی دادههای پَرت با استفاده از z-score
- ۴ » الگوریتم جنگل ایزوله (Isolation Forest) جهت تشخیص دادههای پرت
- ۵ » کاربرد الگوریتم DBSCAN در تشخیص دادههای پَرت (Outliers)
- ۶ » الگوریتم ABOD جهت تشخیص دادههای پرت از طریق زاویه