

در درس گذشته، با دادههایی که از توزیع نرمال استفاده میکردند آشنا شدیم و یاد گرفتیم که چگونه میتوان از این توزیع، برای پیشبینی و پاسخ به سوالات مختلف در یک کسبوکار استفاده کرد. همچنین برخی از الگوریتمهای دادهکاوی، فرضشان این است که دادهها از یک توزیع نرمال پیروی میکنند. سوال اینجاست که چگونه بفهمیم دادههای ما از توزیع نرمال پیروی میکنند یا خیر؟ پاسخ به این سوال را در این درس با هم خواهیم دید.
اولین و شاید سادهترین راه که به ذهن هر کسی میرسد این است که دادهها را توسط ابزارهای مختلف به صورت هیستوگرام رسم کنیم (در درس قبلی یاد گرفتیم که چگونه هیستوگرام بسازیم). مثلاً این کار را میتوان توسط excel یا زبان پایتون و کتابخانهی matplotlib انجام داد. چیزی مانند شکل زیر که در درس قبلی هم به آن اشاره کردیم:
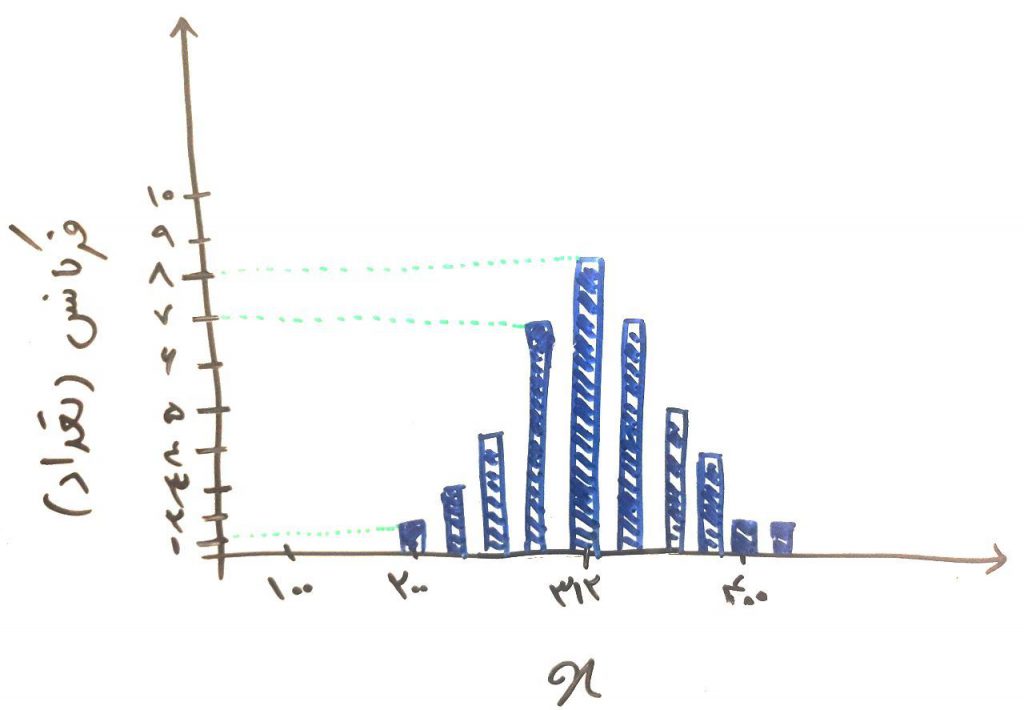
همانطور که مشاهده میکنید با تحلیلِ تصویر بالا، میتوان به این نتیجه رسید که در اینجا دادههای ما از توزیع نرمال پیروی میکنند. در واقع یکی از راههای اطمینان از اینکه دادهها از توزیع نرمال پیروی میکنند یا خیر، رسم هیستوگرامِ دادهها و نگاه به آن است.
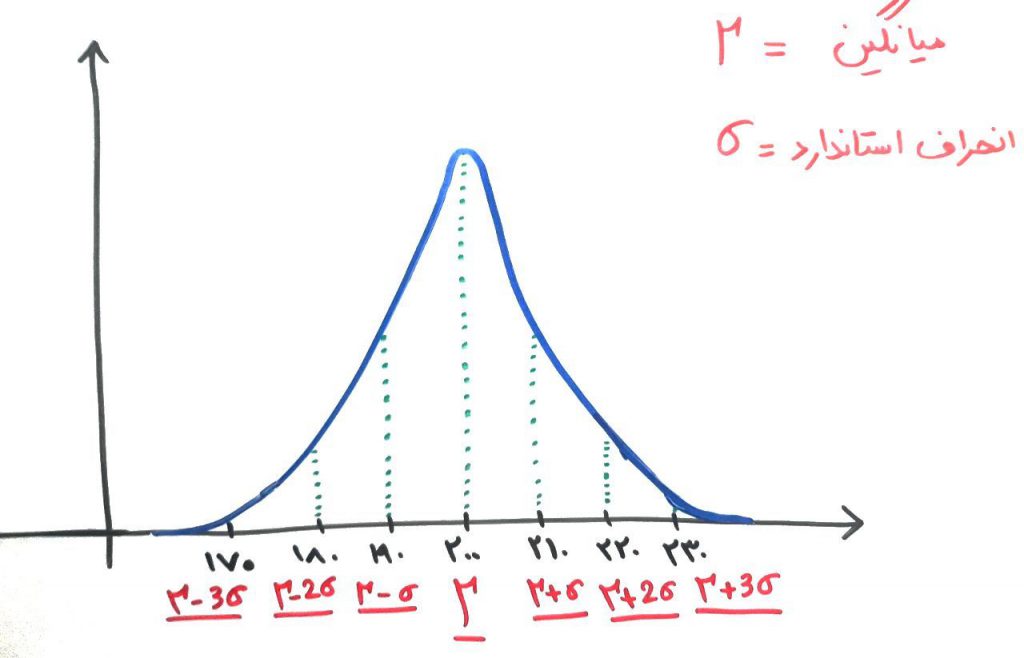
اما روش دیگری نیز وجود دارد که به قانون ۶۸-۹۵-۹۹.۷ معروف است. اگر درس قبل را دقیق خوانده باشید، این اعداد برایتان آشناست. این قانون به صورت تجربی میگوید: در یک توزیع نرمال، ۶۸ درصد از دادهها در فاصلهی ۱ برابریِ انحراف استاندارد نسبت به میانگین قرار دارند، ۹۵ درصد از دادهها در فاصلهی ۲ برابریِ انحراف استاندارد نسبت به میانگین قرار دارند و ۹۹.۷ درصد از دادهها در فاصلهی ۳ برابریِ انحراف استاندارد نسبت به میانگین قرار گرفتهاند. به سادگی میتوان از این قانون بهره گرفت، به این صورت که ابتدا میانگین و انحراف استاندارد را برای دادههایمان محاسبه کرده و با مرتب کردنِ دادهها از کم به زیاد، مشاهده میکنیم که آیا برای مثال ۶۸ درصد از دادهها در بازهی ۱ برابریِ انحراف استاندارد نسبت به میانگین قرار گرفتهاند یا خیر؟ برای ۹۵ و ۹۹.۷ هم با ضرایب ۲ و ۳ برابریِ انحراف استاندارد نسبت به میانگین، همین کار را انجام میدهیم و در نهایت متوجه میشویم که دادهها تا چه حدی به توزیع نرمال شباهت دارند.
برای روشنتر شدنِ قانون ۶۸-۹۵-۹۹.۷، فرض کنید ۱۰۰ عدد داده دارید که میانگین آنها برابر ۲۰۰ با انحراف استاندارد ۱۰ شده است (مثال فلافل فروش را از درس قبل به خاطر بیاورید). اگر دادهها را مرتب کنیم، بایستی حدوداً ۶۸ نمونه از دادهها در بازهی ۱۹۰ تا ۲۱۰ قرار گرفته باشند. تقریباً ۹۵ نمونه از دادهها در بازهی ۱۸۰ تا ۲۲۰ و تقریباً همهی دادهها در بازهی ۱۷۰ تا ۲۳۰ قرار بگیرند. اگر این اتفاق افتاد، یعنی دادههای ما از توزیع نرمال پیروی میکنند. چیزی که در شکل زیر هم مشخص است:
اگر چه که در بسیاری از مواقع همین آزمایشها و آزمونهای گفته شده در بالا، برای تعیینِ نرمال بودنِ توزیعِ مجموعه داده کفایت میکند ولی این روشها نمیتوانند دقت بسیار بالایی داشته باشند. ممکن است در دادهها چولگی به سمت راست یا چپ وجود داشته باشد و یا دادهها دارای نویز بوده و خطا ایجاد کند. برای همین میتوان از روشهای دیگری نیز استفاده کرد. یکی از این روشها بررسی نمودار Q-Q است. این نمودار مقایسهای است بین دادههای واقعیِ ما و دادههای ایدهآل برای یک نمودار توزیع نرمال. در واقع دادههای ما با دادههایی که در یک توزیع کاملاً نرمال شده باشند، مقایسه میشوند و نموداری مانند نمودار زیر پدید میآید (دو مجموعه دادهی مختلف داریم که هر کدام را با دادههای ایدهآل برای توزیع نرمال مقایسه کرده و نمودار Q-Q را برای آنها رسم کردهایم):
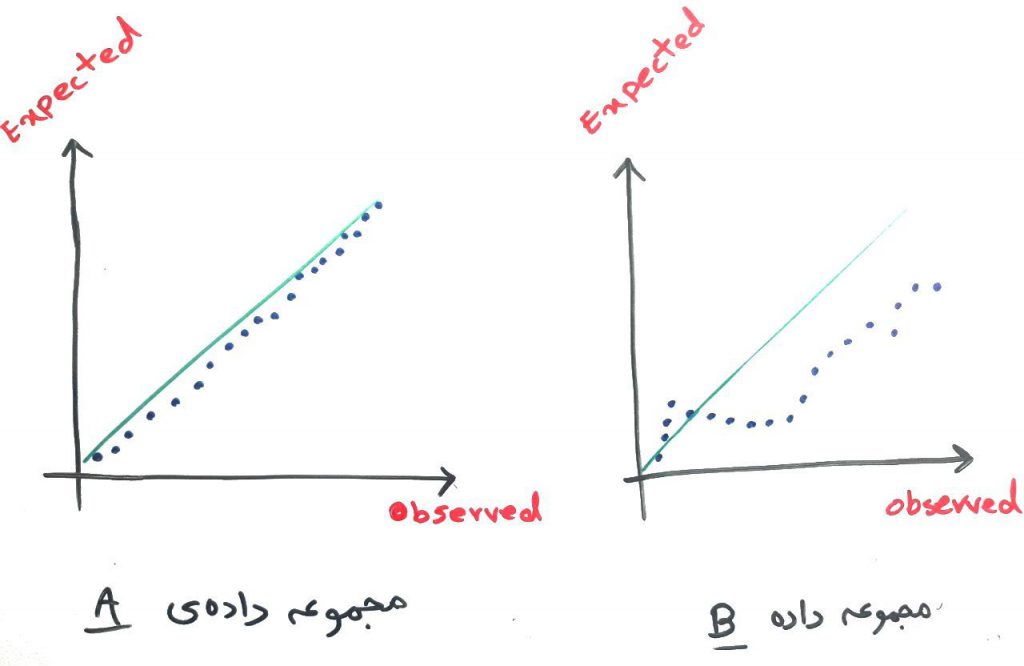
محور عمودی مقداری است که انتظارش را داریم و محور افقی مقادیر موجود در دادههای ماست. هر چقدر که نقاطِ درج شده در این نمودار در یک خط راست به صورت ۴۵ درجه قرار گرفته باشند، نشاندهندهی این است که دادههای ما بیشتر به توزیع نرمال شباهت دارد. برای مثال در شکل بالا، نمودار سمت چپ نشان میدهد که مجموعه دادهی A به صورت نرمال توزیع شده ولی نمودار سمت راست نشان میدهد که مجموعه دادهی B از یک توزیع نرمال پیروی نمیکند. البته توجه داشته باشید که نمودار Q-Q همهی دادهها را با هم مقایسه نکرده و روش خاص خود را در محاسبه دارد. برای اطلاعات بیشتر قسمت منابع این درس را مطالعه کنید. سعی میکنیم در دروس آینده هم، نحوهی ساخت این نمودار را آموزش بدهیم.
روشهای متفاوتِ دیگری نیز برای تشخیص نرمال بودنِ دادهها وجود دارد که در درسهای بعدی به آنها خواهیم پرداخت ولی در اکثر موارد، مخصوصاً برای مسائلِ عمومی، روشهای گفته شده در بالا کارا خواهند بود.

- ۱ » متغیر تصادفی (Random Variable)، تابع توزیع احتمال (PDF) و تابع توزیع تجمعی (CDF)
- ۲ » توزیع نرمال (Normal Distribution) یا توزیع گوسی (Gaussian Distribution)
- ۳ » چگونه بفهمیم دادههای ما از توزیع نرمال پیروی میکند یا خیر؟
- ۴ » توزیع یکنواخت (Uniform Distribution) و کاربردهای آن
- ۵ » توزیع برنولی (Bernoulli Distribution) و توزیع دو جملهای (Binomial Distribution)
- ۶ » توزیع پواسون (Poisson Distribution)
- ۷ » توزیع نمایی (Exponential Distribution)
- ۸ » آزمون برازش Chi-Square برای توزیعهای احتمال
- ۹ » توزیع گاما (Gamma Distribution)
سلام ممنون از زحماتتو خیلی جالب بود برام
ممنون میشم اگر این مبحث رو ادامه بدین و لینکی هم برای آشنایی بیشتر با این مورد هم در اختیار من قرار بدید
خیلی خوب و ساده و قابل فهم توضیح دادی…
بسیار بسیار ممنون
با سلام و تشکر از زحمات شما. عالی بود.