

در ادامه دورهی متنکاوی، در این درس میخواهیم کمی دقیقتر به بحثِ خوشهبندی در متون بپردازیم. حتماً درس خوشهبندی و همچنین دورهی الگوریتمهای خوشهبندی را خواندهاید. گفتیم که در خوشهبندی، به دنبالِ پیدا کردنِ اُلگوهای مشخص در دادهها میگردیم. این الگوها (Patterns) بدونِ ناظر مشخص میشوند و میتوانند اطلاعاتِ مفیدی را دربارهی دادهها به ما بدهند.
فرض کنید شما مسئول قسمت ارتباط با مشتریان در یک شرکت که در حوزهی فروش محصولاتِ غذایی کار میکند، هستید و واحدِ شما از طریق نرمافزار مدیریت ارتباط با مشتری (CRM) با مشتریان در ارتباط هست. مشتریان روزانه تقاضاهای مختلفی را از طریقِ نرمافزارِ CRM برای شرکت ارسال میکنند. تعداد این تقاضاها بسیار زیاد است و طبیعتاً تحلیل آنها دشوار. حال فرض کنید برای جلسهی آخرِ سالِ شرکت، میخواهید گزارشی تهیه کرده و در آن گزارش به بررسی موضوعات مهمی که مشتریان از طریق CRM تقاضا کردهاند بپردازید. مثلاً ممکن است مشتریان بیشتر از سیستم حملونقل شکایت داشته باشند و یا تعداد زیادی از تقاضاهای مشتریان، حاکی از لحنِ غیرمحترمانهی مامورانِ تحویل کالا از طرف شرکت شما به آنها باشد. تعداد تقاضاهای متنی (از طریق CRM) بسیار بالا است و برای تحلیل آن بایستی از روشهای پردازش متن و متنکاوی کمک گرفت. این مسئله را میتوان یک مسئلهی خلاصهسازیِ خودکار (automatic summarization) دانست زیرا میخواهیم از بین تمامیِ تقاضاها (که تعدادشان زیاد است)، به صورت خلاصه نمونهها یا کلیدواژههایی را انتخاب کنیم.
اگر بخواهیم به صورت سناریو و مرحله به مرحله عملیات خوشهبندی را بر روی متون (مانند مثال بالا در مورد متنِ تقاضاها) انجام دهیم، ابتدا بایستی متون را از نرمافزار CRM جمعآوری کرده و بعد به یک شکل قابل فهم برای الگوریتم تبدیل کنیم. این کار را در درس کولهی کلمات و TF-IDF یادگرفتیم. فرض کنید که ۱میلیون متن تقاضا داریم و در مجموع ۱۰۰هزار کلمهی یکتا (یعنی کلماتی که تکراری نیستند) در میان این ۱میلیون متن داریم. پس اگر بخواهیم این متون را به شکلِ قابل فهم برای الگوریتم تبدیل کنیم، میتوانیم با استفاده از کولهی کلمات (BoW) این ۱میلیون متن که دارای ۱۰۰هزار کلمهی یکتا هستند را در ماتریس با ۱میلیون سطر و ۱۰۰ستون (بُعد) قرار دهیم (اگر نمیدانید این ماتریس به چه شکلی ایجاد میشود، درسِ کولهی کلمات را بخوانید).
بعد از آن با استفاده از این ماتریس (که ماتریس بزرگی هم هست) میتوانید عملیات خوشهبندی را با یکی از الگوریتمهایی که در دورهی خوشهبندی مطرح شد انجام دهید. شکل زیر میتواند این فرآیند را بهتر نمایش دهد:
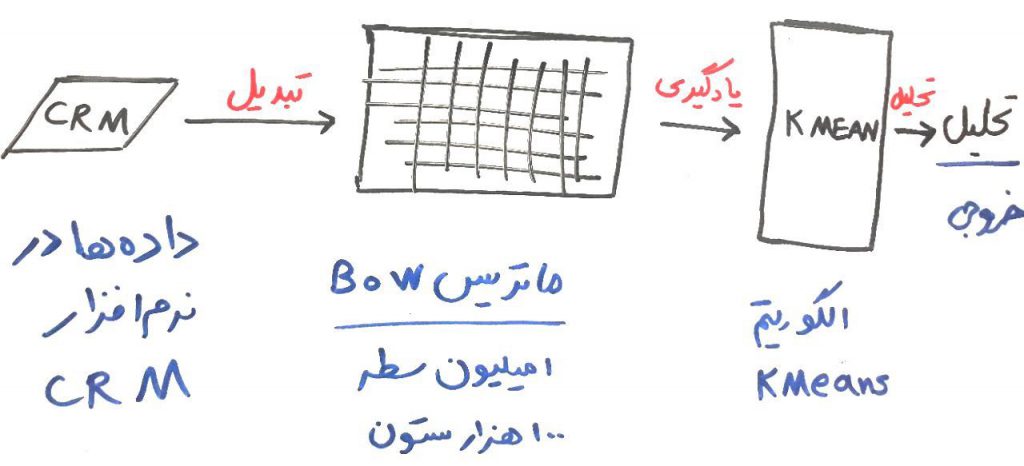
برای مثال فرض کنید، میخواهید با استفاده از الگوریتم KMeans به ۵گروه (خوشه) دست پیدا کنید (الگوریتمِ KMeans احتیاج داشت تا تعدادِ خوشهها توسط کاربر تعیین شود) و از میان هر کدام از این خوشهها، کلمات و عباراتی را که بیشتر در هر خوشه استفاده شده است، به عنوانِ نمایندهی آن خوشه در نظر بگیرید. مثلاً فرض کنید به جای ۱۰۰هزار ویژگی (بُعد) ما برای سادگی و قابل رسم بودن، ۲بُعد داشتیم (که در درس ویژگی و بُعد یاد گرفتیم چطور این ابعاد را رسم کنیم). آن وقت ممکن بود چیزی شبیه به شکل زیر به وجود آید (هر کدام از نقطههای سیاه یک متنِ تقاضا است):
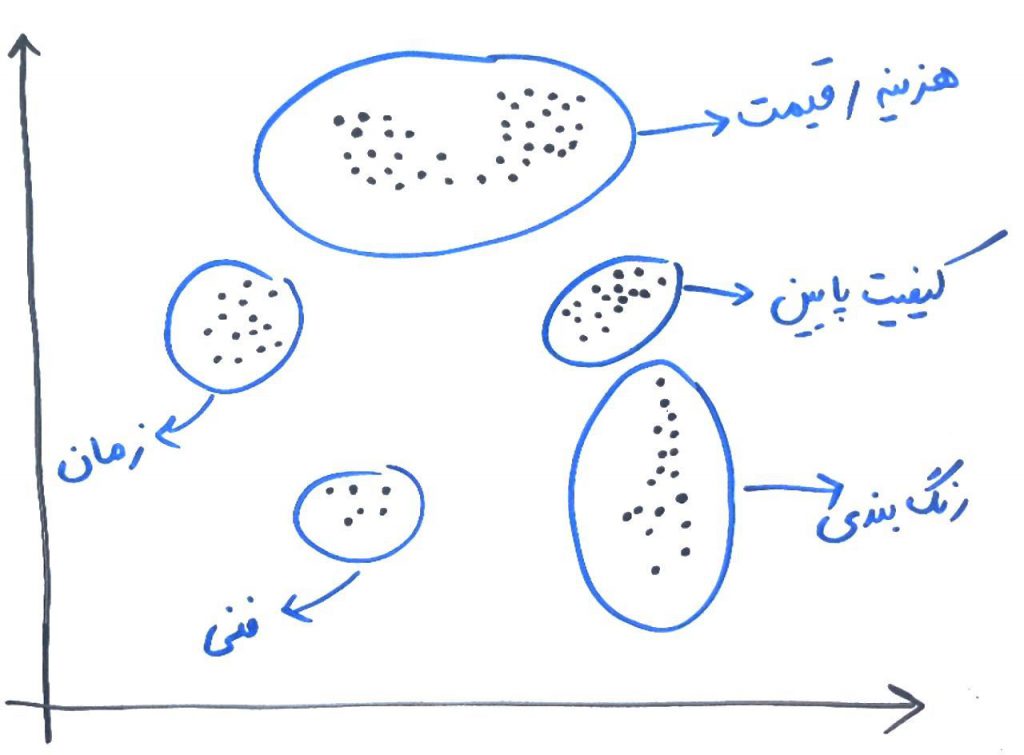
همانطور که میبینید، با اعمال الگوریتمِ KMeans از میان متونِ مختلف به ۵خوشه رسیدیم که هر کدام نمایانگر یک یا چند موضوع هستند. مثلا یکی از خوشهها شامل متونی است که بیشتر در مورد هزینه و قیمت صحبت کرده است و دیگری بیشتر در مورد کیفیت پایین حرف زده است. اگر دقت کنید، در خوشهی بالایی (هزینه و قیمت)، باز هم قابلیتِ تفکیک وجود دارد. برای مثال ممکن است از الگوریتم بخواهیم به جای ۵خوشه، ۷خوشه را به دست ما بدهد، آنگاه ممکن است خوشهی بالایی باز هم شکسته شود. برای مثال از الگوریتم KMean میخواهیم به جای ۵خوشه، این بار ۷خوشه به ما بدهد و ممکن است خروجی چیزی شبیه به شکل زیر باشد:
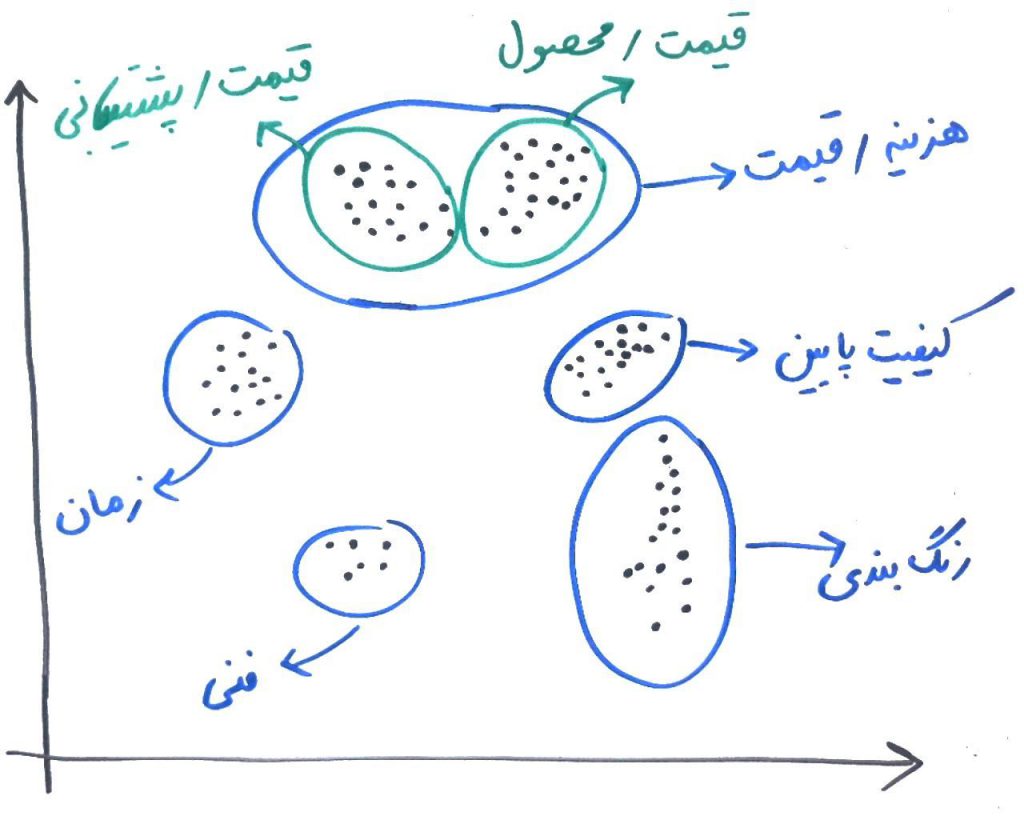
همانطور که دیدید، خوشهی بالا که در مورد هزینه و قیمت بود، خود به دو قسمتِ قیمت خرید و قیمت پشتیبانی تقسیم شد و این نشان میدهد که یکی از دغدغههای مشتریان قیمتِ بالای خرید و یا قیمت بالای پشتیبانی توسط شرکت شما میباشد.
مثال بالا، یک نمونه از کاربردهای خوشهبندی در متنکاوی بود. الان مسئول بخشِ ارتباط با مشتریان، میتواند با این خلاصهسازی به نکات ارزشمندی پیببرد. مثلا اینکه فاکتور قیمتِ بالا، تعداد زیادی از مشتریان را ناراضی کرده است (به خاطر خوشهی بزرگی که تشکیل داده است) و باید در این زمینه، تدابیری اندیشیده شود.

- ۱ » متن کاوی (Text Mining) و پردازش زبان طبیعی (NLP) چیست؟
- ۲ » ساخت کولهی کلمات (Bag of Words) در پیشپردازش متون
- ۳ » روش TF-IDF برای ساختاردهی به دادههای متنی
- ۴ » تحلیل احساسات (Sentiment Analysis) در متنکاوی
- ۵ » n-gram و کاربرد آن در متنکاوی
- ۶ » مدلسازی موضوعات (Topic Modeling) و کاربرد آن در متنکاوی
- ۷ » یافتن ریشه کلمات با Stemming و Lemmatization
- ۸ » تشخیص شباهت متون (Text Similarity) با استفاده از الگوریتم Jaccard
- ۹ » خوشهبندی متون (Text Clustering) و کاربردهای آن
با سلام خدمت شما استاد کاویانی عزیز
شما برای متن کاوی متون فارسی از چه پکیج هایی استفاده می کنید؟
سلام احسانجان
خیلی بستگی به مسئله داره، ولی عموما Gensim، Tensorflow و NLTK پیشنهاد میشوند
با سلام خدمت شما جناب آقای کاویانی بزرگوار، یک سوالی راجع به الگوریتمهای خوشه بندی داشتم، از بین الگوریتم های خوشه بندی، چه نوع الگوریتمهایی برای متن کاوی مناسب هستند؟ ممنون میشم معروفترین آنها را که کاربرد بیشتری دارند، نام ببرید.
عالیه عالی.
ممنونم.
ای کاش در مورد کلاس بندی هم توضیح داده بودید
سلام
ممنون ، من دانشجوی ارشد تجارت الکترونیک از دانشگاه اصفهان هستم.
از مطالب عالی و روان شما برای ارائه متن کاویم خیلی استفاده کردم و کل مطالب بخش را مطالعه کردم همچنین pdf داده کاویتون را ( با ذکر منبع ) توی مطالب ارائه ام ، ازشون خیلی استفاده کردم .
سپاس
سلام خواستم تشکر کنم از متن به سادگی و البته کاربردی توضیح داده شد.