

در درسِ قبلی یاد گرفتیم که چگونه میتوان دادههای غیرساختاریافتهی متنی را به دادههای ساختاریافتهی ماتریسی توسط BoW تبدیل کرد. در این درس میخواهیم به هر کلمه در متن یک وزن اختصاص دهیم. با این کار، میتوانیم اهمیتِ یک کلمه را در فرآیندِ مهندسیِ ویژگی (Feature Engineering) بهتر شناسایی کرده و در نهایت ویژگیهای بهتری را برای تزریق به الگوریتمهای بعدی مانند طبقهبندی یا خوشهبندی داشته باشیم.
مثال درسِ قبل را به خاطر بیاورید. سه جمله داشتیم که مجموعاً ۲۴کلمهی یکتا داشتند. جملات و شکلِ زیر را برای یادآوری از درس قبل میآوریم:
- جملهی ۱: من از غذای این رستوران خوشم آمد
- جملهی ۲: غذای رستوران خیلی خوب بود ولی رفتار پرسنل نه
- جملهی ۳: جای پارک پیدا نمیشد و غذا خیلی دیر به دستمان رسید
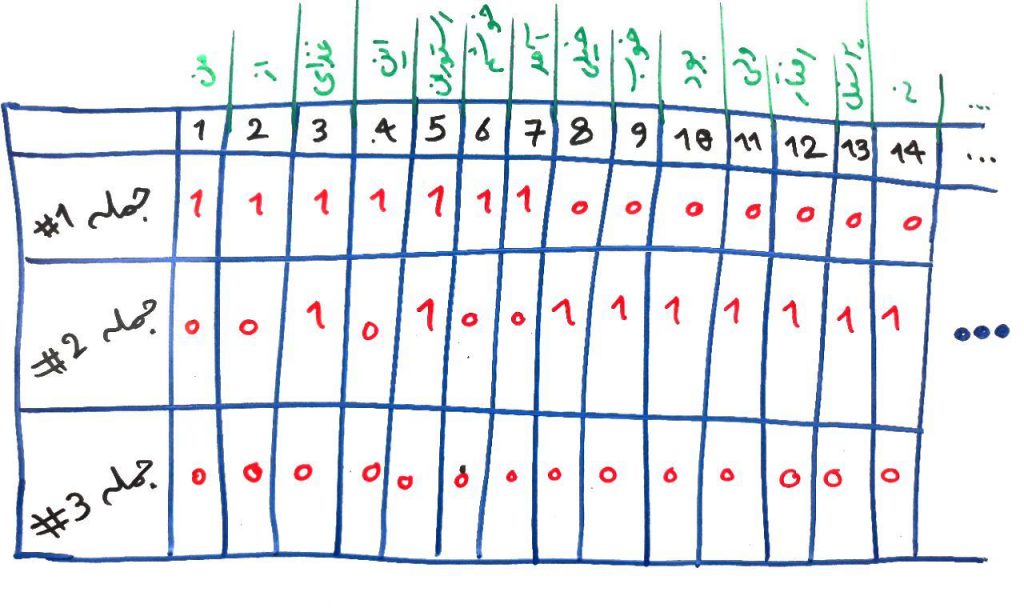
همانطور که قبلاً هم گفتیم، در ماتریسی که ایجاد شد، هر سطر یک جمله یا متن یا سند (یا Document) است و هر ستون یک کلمه و اگر یک کلمهی خاص در یک جمله قرار داشت مقدار ۱ را در سلولِ مربوطه قرار میدهیم و بقیهی سلولها ۰. ولی آیا این کارِ درستی هست؟ فرض کنید یک سری کلمه داریم که معنای خاصی ندارند. برای مثال کلمهی “میباشد” احتمالاً دارای معنای خاصی نیست و نمیتواند چیزی به جمله اضافه کند. یا کلماتی مانند “این”، “آن”، “من” و… به دلیلِ تکرارِ زیاد در جملاتِ مختلف، احتمالاً نمیتوانند بارِ معناییِ خاصی داشته باشند. پس بهتر است به هر کلمه یک وزن به نسبتِ اهمیتِ آن در جمله اختصاص دهیم و به جای ۰ و ۱ های موجود در ماتریسِ بالا آن وزن (که یک عددِ اعشاری هست) را قرار دهیم. این کار میتواند به الگوریتمهای طبقهبندی یا خوشهبندی و یا الگوریتمهای دیگر کمکِ بیشتری جهت تشخیص کلمات و اهمیتِ آنها کند.
مقدارِ TF-IDF مخفف دو کلمه است: TF به معنیِ Term Frequency یعنی تعداد تکرار یک کلمه در یک متن و عبارت IDF به معنیِ Inverse Document Frequency که میتوان آن را به برعکسِ تعداد تکرار در متون ترجمه کرد. اجازه بدهید با یک مثال بحث را ادامه دهیم. فرض کنید میخواهیم بر روی نظراتِ یک وبسایت فروشگاهی که دربارهی محصولاتِ دیجیتال هست عملیات متنکاوی را انجام دهیم. چندین هزار متن داریم که سه نمونه از آنها در زیر آمده است:
- واقعا لپتاپ خوبیه. من کلی تحقیق کردم تا تونستم این لپتاپ رو پیدا کنم. قیمت مناسبه و کارآییش هم خوبه. بیشتر برای کارهایی مثل فتوشاپ ازش استفاده میکنم و در مقایسه با لپتاپهای قبلی به نظر با کیفیتتر میاد.
- یکی از ویژگیهای لپتاپهای سونی اینه که قیمت اونها بالاست ولی انصافا کیفیت بالاتری از هم نوعهاش داره
- من از این مدل سونی اصلاً راضی نیستم. نمیدونستم کارت گرافیکش این قدر بیخوده. حتی یه نرم افزار مثل فتوشاپ رو هم نمیتونه راحت رندر کنه.
این نمونههای بالا، چند نظر در مورد بعضی از محصولاتِ فروشگاه اینتنرتی بود. از این نظرات میتوان در کاربردهای متنکاویِ مختلف، مانند نظرکاوی (Opinion Mining) استفاده کرد. ولی برای این درس ما میخواهیم ببینیم که چگونه میتوان TF-IDF را برای کلمات موجود در این متون محاسبه کنیم تا بتوانیم خانههای ماتریس بالا را به جای ۰ و ۱ با استفاده از مقدار TF-IDF پر کنیم.
گفتیم که TF-IDF از دو قسمت TF و IDF تشکیل شده است. اجازه بدهید هر کدام را جداگانه با یک مثال محاسبه کنیم. جملهی اول را نگاه کنید. کلمهی لپتاپ ۳ بار در خلال این متن تکرار شده است. این متن دارای ۳۹ کلمه است. اگر بخواهیم TF را برای این کلمه در این جمله محاسبه کنیم، بایستی تعداد تکرارِ این کلمه در این متن را محاسبه کنیم و آن را تقسیم بر تعداد کل کلمات در همین متن بکنیم. تعداد تکرار کلمهی لپتاپ در این متن (جملهی اول) که ۳ است، و تعداد کل کلمات در این متن (جملهی اول) هم که ۳۹ است. پس با تقسیم عدد ۳ بر ۳۹ عدد ۰.۰۷۹ به دست میآید که مقدار TF برای کلمهی لپتاپ در جملهی اول است. به صورت شهودی هر چقدر تعداد تکرارِ یک کلمه در یک متن نسبت به تعداد کلماتِ آن متن بیشتر باشد، مقدار TF بیشتر میشود. در واقع مقدار TF نشان دهندهی غلظتِ یک کلمه در متن هست. حالا به IDF برسیم. برای محاسبهی IDF بایستی تعداد کل متون را داشته باشیم. که اینجا ۳ است چون در کل ۳ متن یا جمله (یا Document) داریم. این مقدار را بایستی تقسیم بر تعداد متونی بکنیم که کلمهی لپتاپ در آنها موجود است. همانطور که میبینید کلمهی لپتاپ در جملاتِ ۱ و ۲ (یعنی ۲بار) تکرار شده است. پس بایستی عددِ ۳ (تعداد کل متون) را بر عددِ ۲ (تعداد متونی که کلمهی لپتاپ در آنها آمده است) تقسیم کنیم. البته که یک لگاریتم بر روی حاصل این تقسیم میگیریم (لگاریم باعث میشود که نتیجهی حاصل خیلی زیاد نشود و به نوعی نرمال شود). در نهایت حاصلِ TF را در IDF ضرب میکنیم تا مقدار TF-IDF برای کلمهی لپتاپ در جملهی اول محاسبه شود. در شکلِ زیر خلاصهی چیزی که گفتیم نشان داده شده است:
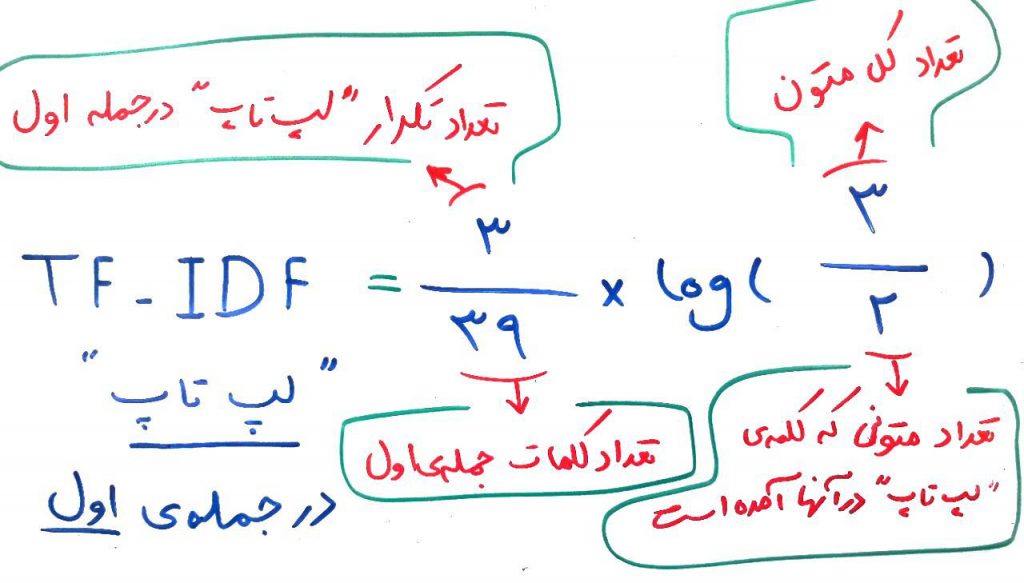
نتیجهی حاصل عددی است که بایستی در ماتریسِ شکل اول برای جملهی ۱ در ستونِ لپتاپ درج شود.
به صورتِ خلاصه هر چه یک کلمه بیشتر در یک متن تکرار شده باشد (TF) ولی در سایرِ متون کمتر تکرار شود (IDF)، مقدار TF-IDF آن بیشتر میشود و این میتواند معیار خوبی جهت تشخیص وزنِ یک کلمه در یک جمله باشد. در واقع نشان میدهد که یک کلمه چقدر میتواند یکتا و مهم باشد. به این صورت ماتریسِ ویژگی برای متون (مانند ماتریس شکل اول) با کیفیت بهتری تشکیل میشود و معمولاً نتایج بهتری در الگوریتمهای طبقهبندی یا خوشهبندی حاصل میشود.

- ۱ » متن کاوی (Text Mining) و پردازش زبان طبیعی (NLP) چیست؟
- ۲ » ساخت کولهی کلمات (Bag of Words) در پیشپردازش متون
- ۳ » روش TF-IDF برای ساختاردهی به دادههای متنی
- ۴ » تحلیل احساسات (Sentiment Analysis) در متنکاوی
- ۵ » n-gram و کاربرد آن در متنکاوی
- ۶ » مدلسازی موضوعات (Topic Modeling) و کاربرد آن در متنکاوی
- ۷ » یافتن ریشه کلمات با Stemming و Lemmatization
- ۸ » تشخیص شباهت متون (Text Similarity) با استفاده از الگوریتم Jaccard
- ۹ » خوشهبندی متون (Text Clustering) و کاربردهای آن
خیلی مفید بود. ممنون
من برای پایان نامم به سایتتون مراجعه کردم مطالب واقعا مفیده خسته نباشید
عزیز جان عالی توضیح داده بودی، خدا قوت
مثل تمامی مطالبی که آموزش میدهید عالی بود لذت بردم از توضیحات جامع شما.
مطلبتون عالی بود. اگه امکانش هست از روشlsa هم مطلب بزارید
آموزش ها عالی و کاربردی ست سپاس
مثل همه مطالب سایت تون عالی توضیح دادین .بینظیر هستین ممنونم
عالی توضیح داده بودید . سپاااااااااااااااااااااااس
میشه لطف کنید در مورد واگرایی کولبک لیبلر هم توضیح بدید توی بعضی مقالات گفتن از tf-IDF بهتره
عالی و مختصر
درود بر شما استاد عزیز
مطالب بسیار روان و خوب در همه آموزش ها توضیح داده شده است بعلاوه اینکه مطالب مرتبط به خوبی لینک شده اند
تشکر خدا قوت
این درس زیاد مفهوم نبود. شاید مثالهای بیشتر یا بهتر میتونست کمک کننده باشه