

در دوره دادهکاوی درسی با عنوانِ پیشپردازش دادهها داشتیم. همچنین دورهای جداگانه به پیشپردازش دادهها اختصاص دادیم و این خود اهمیتِ این موضوع را در دادهکاوی و یادگیری ماشین نشان میدهد. در بحثِ تحلیلِ متون و متنکاوی نیز، قبل از انجام عملیاتِ مختلف مانندِ طبقهبندی بر روی متن و یا خوشهبندی، نیاز هست تا متون به یک فُرمتِ قابل فهم برای کامپیوتر برای محاسباتِ بعدی تبدیل شوند.
اگر درسِ دادههای غیرساختار یافته خوانده باشید، با کمی تفکر متوجه میشوید که متن و اسناد (Documents) متنی از نوع غیرساختار یافته هستند و به همین دلیل نیاز است تا این نوع دادهها با عملیاتِ مختلف (که در دستهی عملیاتِ پیش پردازش قرار دارد) به دادههای ساختاریافته و قابل محاسبات برای کامپیوتر تبدیل شوند. یکی از این روشها مدل کولهای از کلمات یا Bag of Words است که میخواهیم در این درس به آن بپردازیم.
اجازه بدهید یک مثال ساده بزنیم. فرض کنید ۳جمله داریم، که میخواهیم مدلِ BoW یا همان Bag of Words را برای آن بسازیم.
- جملهی ۱: من از غذای این رستوران خوشم آمد
- جملهی ۲: غذای رستوران خیلی خوب بود ولی رفتار پرسنل نه
- جملهی ۳: جای پارک پیدا نمیشد و غذا خیلی دیر به دستمان رسید
به مجموعهی جملات در اصطلاح Corpus نیز میگویند. برای اینکه بتوانید مدل BoW را برای این جملات بسازید، ابتدا بایستی به هر کدام از کلمات، یک عددِ یکتا نسبت دهید. این کار را در زیر انجام میدهیم:
من (۱)، از (۲)، غذای (۳)، این (۴)، رستوران (۵)، خوشم (۶)، آمد (۷)، خیلی (۸)، خوب (۹)، بود (۱۰)، ولی (۱۱)، رفتار (۱۲)، پرسنل (۱۳)، نه (۱۴)، جای (۱۵)، پارک (۱۶)، پیدا (۱۷)، نمیشد (۱۸)، و (۱۹)، غذا (۲۰)، دیر (۲۱)، به (۲۲)، دستمان (۲۳)، رسید (۲۴)
اگر توجه کرده باشید، به هر کلمه یک عددِ یکتا نسبت دادیم. مثلاً ممکن بود کلمهی “غذای” دوبار تکرار شود، ولی ما عددِ ۳ را به آن اختصاص دادیم.
حتما درسِ ویژگی یا بُعد چیست را خواندهاید. ما برای عملیاتِ دادهکاوی نیاز داریم که ویژگیهای مختلف را بسازیم. به این کار به اصطلاح مهندسیِ ویژگی (Feature Engineering) میگویند. حال به تصویر زیر نگاه کنید. ما سه جمله (سه Document) داشتیم که هر کدام کلماتی داشتند.در واقع در کل ۳جمله و ۲۴کلمه داشتیم. پس یک ماتریس نیاز داریم که ۳سطر و ۲۴ستون داشته باشد:
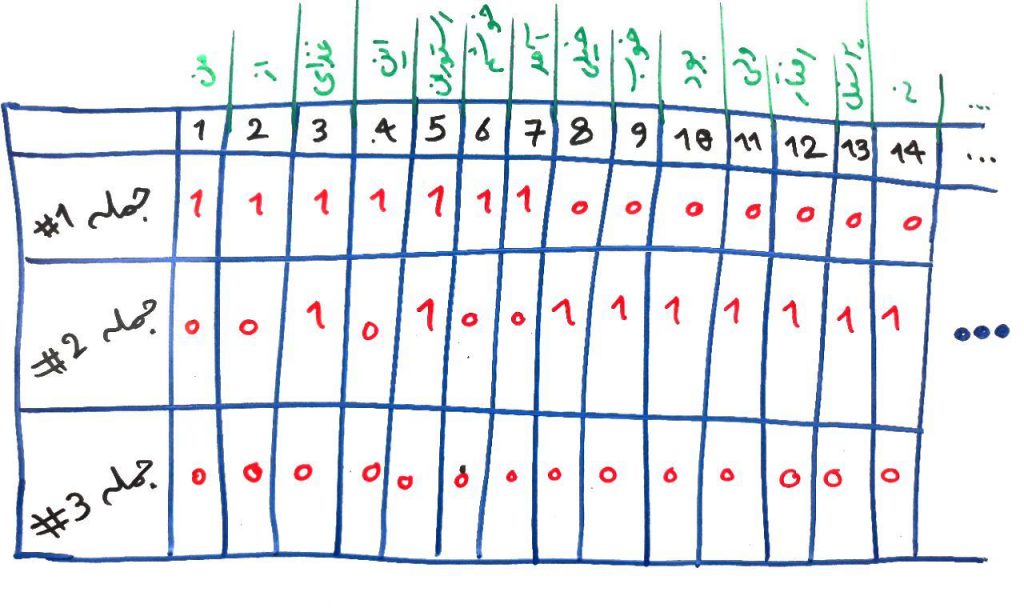
در تصویرِ بالا قسمتی از ماتریس را نمایش دادیم. همانطور که میبینید بعضی خانههای ماتریس با ۱ پر شده اند و بقیه ۰ هستند. هر سطر یک جمله است و هر ستون یک کلمه. اگر یک کلمهی خاص در یک جمله وجود داشته باشد، آن خانه ۱ میشود و اگر وجود نداشته باشد آن خانه عدد ۰ را میگیرد. برای مثال در سطرِ دوم خانهی شمارهی ۵، مقدار ۱ را دارد. زیرا جملهی دوم (سطر دوم) کلمهی شماره ۵ (کلمهی “رستوران”) را در خود دارد.
به این صورت کولهای از کلمات در ماتریس ساخته میشود و این ماتریس میتواند به الگوریتمهای بعدی برای عملیاتی مانند طبقهبندی یا خوشهبندی تزریق شود. در واقع ما در مثالِ بالا توانستیم یک سری دادههای غیرساختار یافته را به یک دادههای عددی (به صورت ماتریس) تبدیل کنیم و میدانیم که برای کامپیوتر، محاسبات بر روی ماتریس بسیار سادهتر صورت میگیرد.

- ۱ » متن کاوی (Text Mining) و پردازش زبان طبیعی (NLP) چیست؟
- ۲ » ساخت کولهی کلمات (Bag of Words) در پیشپردازش متون
- ۳ » روش TF-IDF برای ساختاردهی به دادههای متنی
- ۴ » تحلیل احساسات (Sentiment Analysis) در متنکاوی
- ۵ » n-gram و کاربرد آن در متنکاوی
- ۶ » مدلسازی موضوعات (Topic Modeling) و کاربرد آن در متنکاوی
- ۷ » یافتن ریشه کلمات با Stemming و Lemmatization
- ۸ » تشخیص شباهت متون (Text Similarity) با استفاده از الگوریتم Jaccard
- ۹ » خوشهبندی متون (Text Clustering) و کاربردهای آن
سلام خسته نباشید من در حال حاضر text mining با خواندن مطالب شما آغاز کردم ممکنه کتابی در این رابطه معرفی کنید که دانلود کنم و رایگان باشه و بقیه مطالب والگوریتم ها در این زمینه رو به من یاد بده لینک خای کتاب هوایی که گفتید رایگان نیست
بسیار خوب و مفید
ممنونم
نموداری سراغ دارید که n-gram رو به خوبی نمایش بده؟؟؟
عالی بود ممنونم
سلام
مسعود جان نوشته هات برای من نوستالژی بود! یادش بخیر!
اگه خاطرتون باشه بخش پیش پردازش رو من ارائه دادم!
امیدوارم همیشه موفق و نزدیک تر به خدا باشی
سلام
بله علی جان
یادش بخیر 🙂