

فرض کنید شما مسئول مرور پایاننامههای دانشجویی هستید و یک پروژه به شما سپرده شده است. در این پروژه بایستی میزان شباهتِ یک پایاننامهی جدید را با پایاننامههای موجود در دانشگاه مقایسه کنید تا دانشگاه بتواند اطمینان حاصل کند که این پایاننامه یک پایاننامهی تقلبی و کپی نیست. قطعاً شما نمیتوانید این کار را در زمان معقول و با کیفیت معقول انجام دهید، پس احتمالاً نیاز به طراحی یک الگوریتم برای انجام این کار دارید.
برای مثال میخواهیم جملهی شمارهی ۱ را با جملههای شمارهی ۲ و ۳ مقایسه کنیم:
۱. بهترین غذا در ایران، قرمه سبزی است
۲. غذاهای ایرانی، بسیار خوشمزه و البته مانند انواع قرمهها بعضاً چرب هستند
۳. در مکزیک غذا و خوراکیها معمولاً تند هستند
برای مقایسهی میزانِ شباهت جملهی ۱ با جملههای ۲ و ۳، ابتدا میتوانیم کلمات را به ریشهی آنها تبدیل کنیم. در درسِ گذشته با ساخت و کاربرد ریشهی کلمات آشنا شدیم. اجازه بدهید (به صورت نادقیق) کلمات را در جملاتِ بالا، به ریشهی آنها برگردانیم:
۱. به غذا در ایران قرمه سبزی است
۲. غذا ایران بسیار خوشمزه و البته مانند انواع قرمه بعضاً چرب است
۳. در مکزیک غذا و خوراکی معمولاً تند است
برای مقایسهی میزان شباهت، میتوان از معیاری به اسم معیار Jaccard استفاده کرد. فرمول محاسبهی میزان شباهت Jaccard به صورت زیر تعیین میشود:

اجازه بدهید برای همین مثالِ بالا، شباهت جملات ۱ و ۲ را با هم طبق معیار Jaccard محاسبه کنیم. ابتدا باید محاسبه کنیم که جملاتِ ۱ و ۲ چند کلمه مشترک با هم دارند. کلمات: غذا، ایران، قرمه، است (شامل ۴کلمه) با هم مشترک هستند. سپس بایستی تعداد کل کلمات (یکتا) را حساب کنیم. کلمات: به، غذا، در، ایران، قرمه، سبزی، است، بسیار، خوشمزه، و، البته، مانند، انواع، بعضاً، چرب (شامل ۱۵ کلمه) است. پس عدد ۴ را بر ۱۵ تقسیم میکنیم تا در واقع تعداد کلماتِ مشترک را بر تعدادِ کلِ کلمات یکتا تقسیم کرده باشیم. عدد ۰.۲۶۶ معیار شباهت Jaccard برای جملات ۱ و ۲ بود. تصویر زیر گویای کلمات مشترک و غیر مشترکِ این دو جمله است:
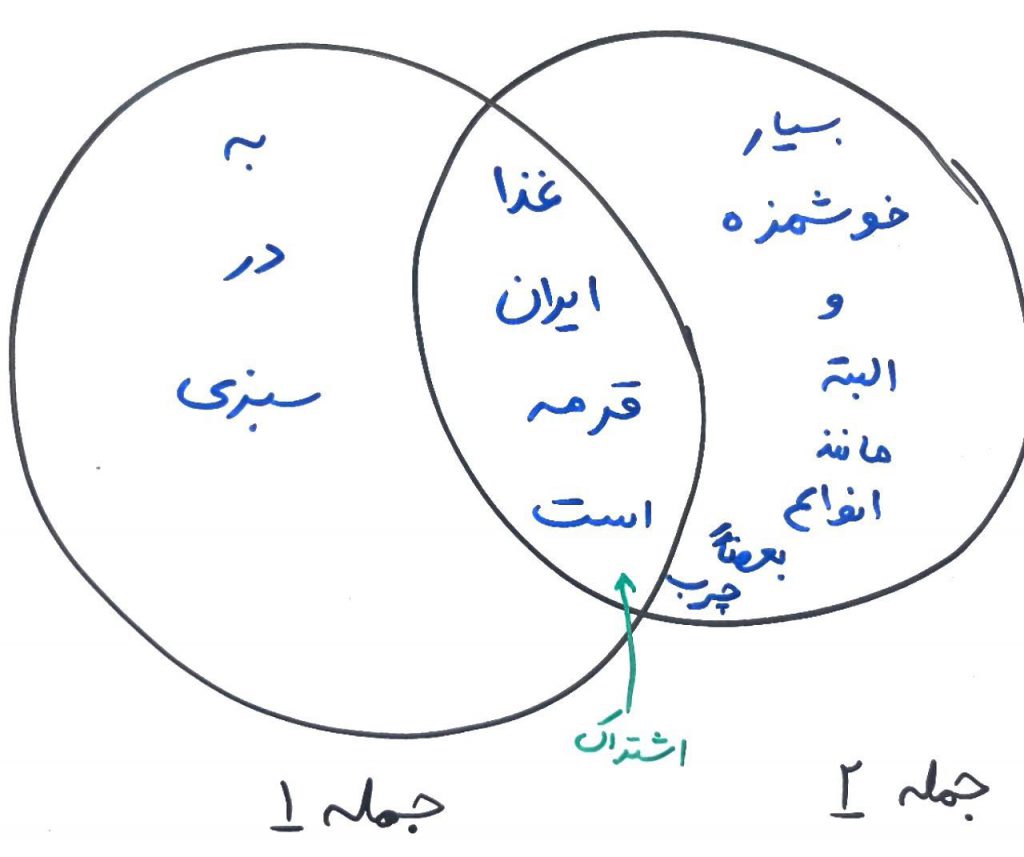
همینکار را برای جملهی ۱ و ۳ انجام میدهیم. جملات ۱ و ۳ در دو کلمه، مشترک هستند و کلِ کلمات یکتای آنها برابر ۱۳ عدد است. پس با تقسیم عدد ۲ بر ۱۳ مقدار ۰.۱۵۳ به دست میآید که این، معیارِ شباهت Jaccard برای جملات ۱ و ۳ است.
همانطور که به صورتِ شهودی هم مشخص هست، جملهی ۱ با جملهی ۲ بسیار نزدیکتر است تا با جملهی ۳. برای همین هست که مقدارِ معیار جاکارد (Jaccard) برای جملهی ۱ و ۲ بیشتر از جملهی ۱ و ۳ شده است.
معیارهای دیگری نیز مانند Cosine Similarity جهت تشخیصِ شباهت بین دو جمله، موجود هستند که هر کدام کاربردها و مزایای خود را دارند.

- ۱ » متن کاوی (Text Mining) و پردازش زبان طبیعی (NLP) چیست؟
- ۲ » ساخت کولهی کلمات (Bag of Words) در پیشپردازش متون
- ۳ » روش TF-IDF برای ساختاردهی به دادههای متنی
- ۴ » تحلیل احساسات (Sentiment Analysis) در متنکاوی
- ۵ » n-gram و کاربرد آن در متنکاوی
- ۶ » مدلسازی موضوعات (Topic Modeling) و کاربرد آن در متنکاوی
- ۷ » یافتن ریشه کلمات با Stemming و Lemmatization
- ۸ » تشخیص شباهت متون (Text Similarity) با استفاده از الگوریتم Jaccard
- ۹ » خوشهبندی متون (Text Clustering) و کاربردهای آن
برای مقایسه پایان نامه اگه بخوایم از این روش استفاده کنیم که شباهت ها خیلی زیاد میشه. چون یک موضوعی رو به هر شکلی که بنویسن شباهت بسیار زیادی داره.
اگه بخوایم دقیقا خود پاراگراف رو بسنجیم که مثلا دقیقا فلان پاراگراف با پاراگراف دیگه یکی هست یا نه، باید هر پاراگراف رو جدا جدا بررسی کنیم؟
بله
سلام وقتتون بخیر
ممنون بابت توضیحات خوبتون یک سوال داشتم اگر یک متن را برای اموزش به مدل ساخته شده ی خود بدهیم و سپس یک جمله ی غلط به مدل خود بدهیم تا ان را اصلاح کند(مثلا جمله علی به درخت رفت….) این از چه پردازشی ( یعنی n-gram یا test similarity یا correction text یا…..) ؟ از کدوم پردازش باید استفاده کنه؟