

یکی از معروفترین و پرکاربردترین روشهای خوشهبندی که در اکثرِ مراجع و کتابهای خوشهبندی، یک پای ثابت هست، الگوریتمهای خوشهبندیِ سلسله مراتبی میباشند. این الگوریتمها به دو دوستهی agglomerative و partitioning تقسیمبندی میشوند. در روشِ agglomerative که به آن روش پایین به بالا نیز گفته میشود، هر نمونه ابتدا خود یک خوشه است و در هر مرحله نمونهها به هم دیگر میچسبند تا خوشههای بزرگتر را تولید کنند و در نهایت همهی نمونهها با هم یک خوشهی بزرگ را تشکیل میدهند. ولی در partitioning بر عکس است، یعنی ابتدا تمامیِ نمونهها با هم یک خوشهی بزرگ در نظر گرفته میشوند و بعد در هر مرحله به خوشههای کوچکتر تقسیم میشوند تا جایی که هر نمونه یک خوشه باشد.
برای درک روش agglomerative فرض کنید در دنیا، ابتدا هر فرد یک خوشه است. حال این فرد در مرحلهی بعد با اعضای خانواده خود یک خوشه را تشکیل میدهد. بعد از آن، خانودادهها با هم شهرها را تشکیل داده و شهرها با هم استانها و بعد از آن کشورها، قارهها و در نهایت کل جهان را تشکیل میدهند. واضح است که روش partitioning برعکسِ این عمل میکند و از کلِ جهان در هر مرحله به یک فرد میرسد.
شکل زیر یک دندوگرام (Dendogram) از مثال بالا است:
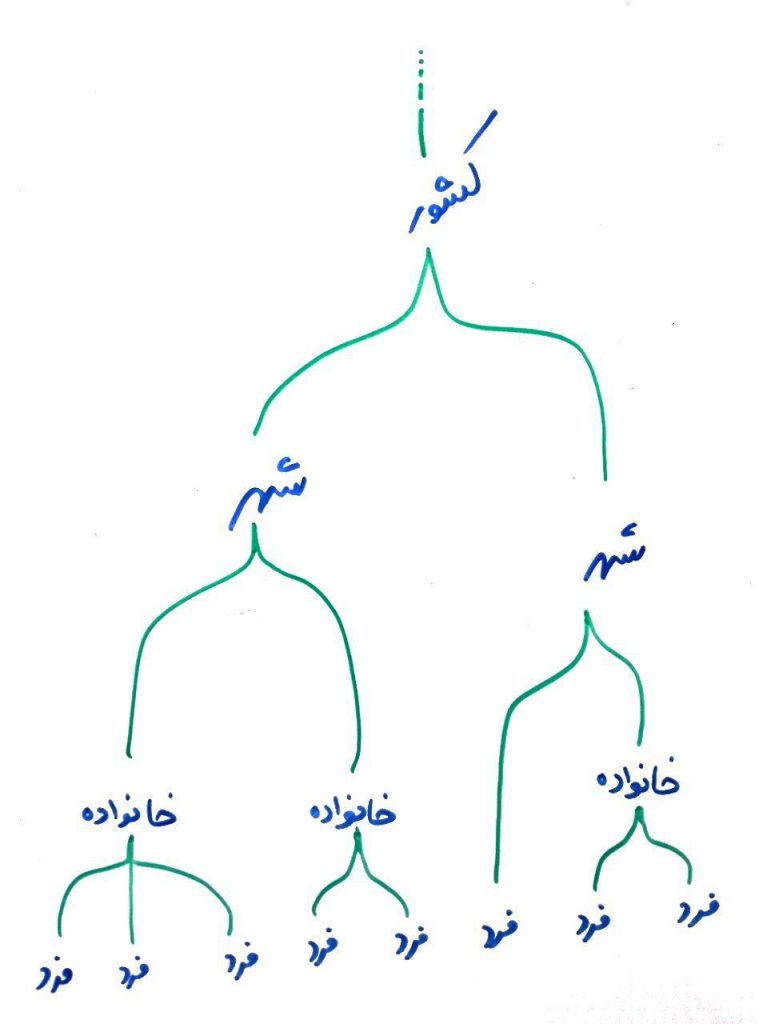
همان طور که میبینید خوشه ها از پایین به بالا بزرگتر ساخته میشوند و از بالا به پایین، بیشتر قسمتبندی میشوند. در این درس سعی داریم روش پایین به بالا (Bottom Up) یا همان Agglomerative را توضیح دهیم.
برای این کار، در فضای نمونه (درس ابعاد را خوانده باشید)، ابتدا دو نقطهای که بیشتر از همه به هم نزدیک هستند را پیدا میکنیم. بعد از اینکه این دو نقطه را با هم یک خوشه در نظر گرفتیم، دوباره میانگین این دو نقطه را یک نقطه در مرکز خوشه در نظر میگیریم و دوباره به دنبال دو خوشه نزدیک به هم میگردیم تا آنها را تبدیل به یک خوشه کنیم. این کار را آنقدر انجام میدهیم تا تمامیِ نقاط در نهایت یک خوشه واحد شوند. برای درک بهتر شکل زیر را نگاه کنید:
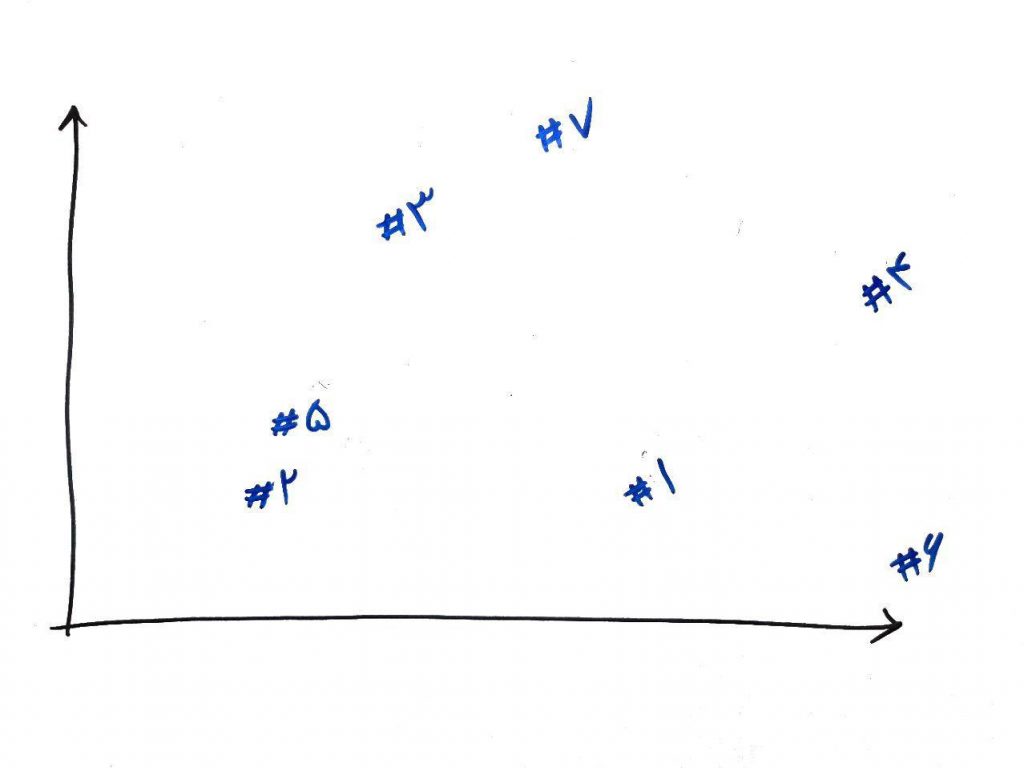
همان طور که میبینید در این شکل دو نمونه ۲ و ۵ به همدیگر نزدیکتر هستند. پس این دو را یک خوشه در نظر میگیریم و یک نقطه در میان این خوشه به عنوان مرکز خوشه (جهت مقایسه های بَعدی) میسازیم. مانند شکل زیر:
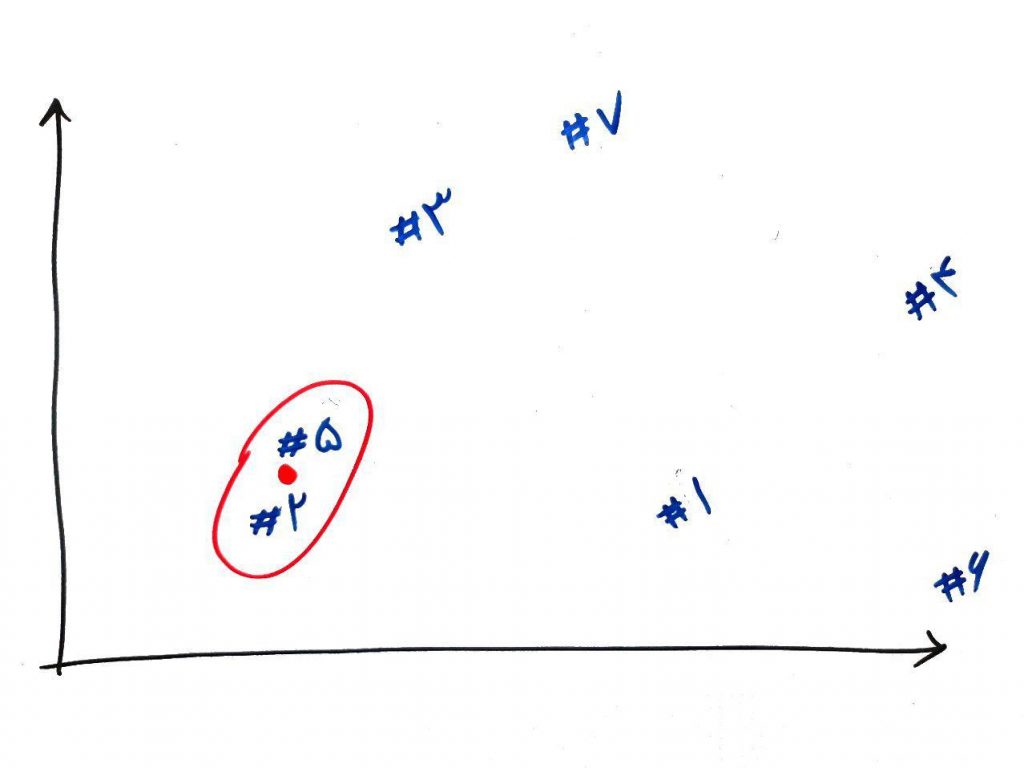
حال این نقطه جدید (مرکز خوشهای که از دو نمونه ۲ و ۵ ساخته شده بود) را با نقاط دیگر مقایسه میکنیم. دوباره به دنبال نقاط نزدیک به هم (با توجه به خوشه جدید ایجاد شده) میگردیم. مشاهده میکنید که نقاط ۳ و ۷ به یکدیگر نزدیکتر هستند. این دو نقطه را با هم به یک خوشه تبدیل کرده و نقطهی مرکزیِ آنها را محاسبه میکنیم. مانند شکل زیر:
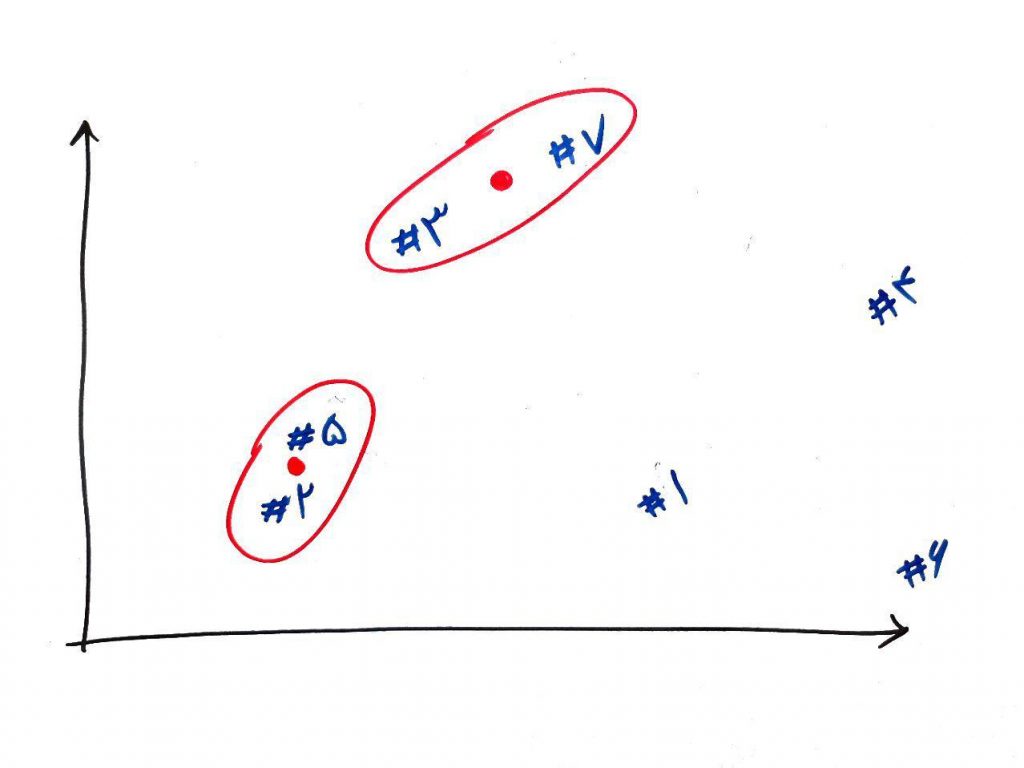
حال مشاهده میکنید که برای دور بعد میتوانیم مرکزهای خوشه های ایجاد شده را با هم ترکیب کنیم و یک خوشه جدیدتر بسازیم. شکل زیر تجمیع شدهی دو خوشه قبلی (خوشه های ۲ – ۵ و ۳ – ۷) برای خوشه جدید است:
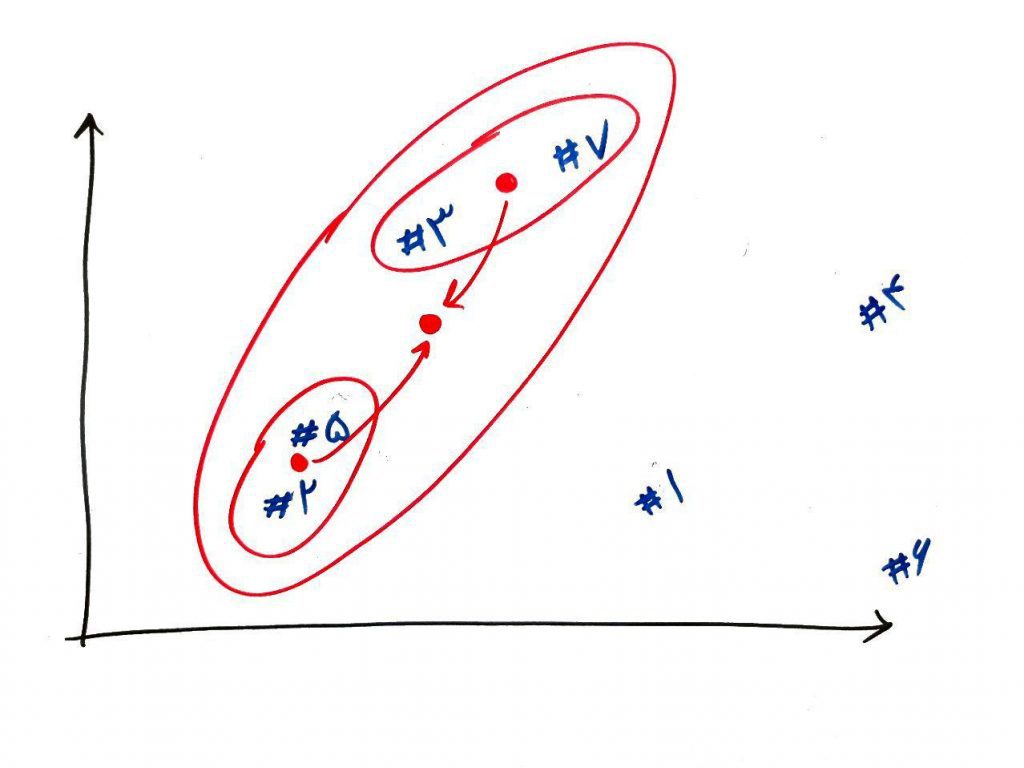
البته آنطور که در نوشتهها آمده است، برای ساخت میانگین نمونههای ۲-۵-۳-۷ میانگین همهی آنها را با هم در نظر میگیریم و نه میانگین خوشههای قبلیِ آنها را. همان طور که میبینید خوشهها به همین صورت ساخته می شوند و بعد از ادغام نقطههای ۱ و ۴ و بعد از آن ۶، خوشهها همه با هم، تشکیل یک خوشه نهایی و بزرگ را میدهند (که از رسمِ مراحلِ آن صرف نظر میکنیم).
شکل زیر دندوگرامِ کامل برای مراحل خوشهبندیِ سلسله مراتبی از پایین به بالا را نشان میدهد:
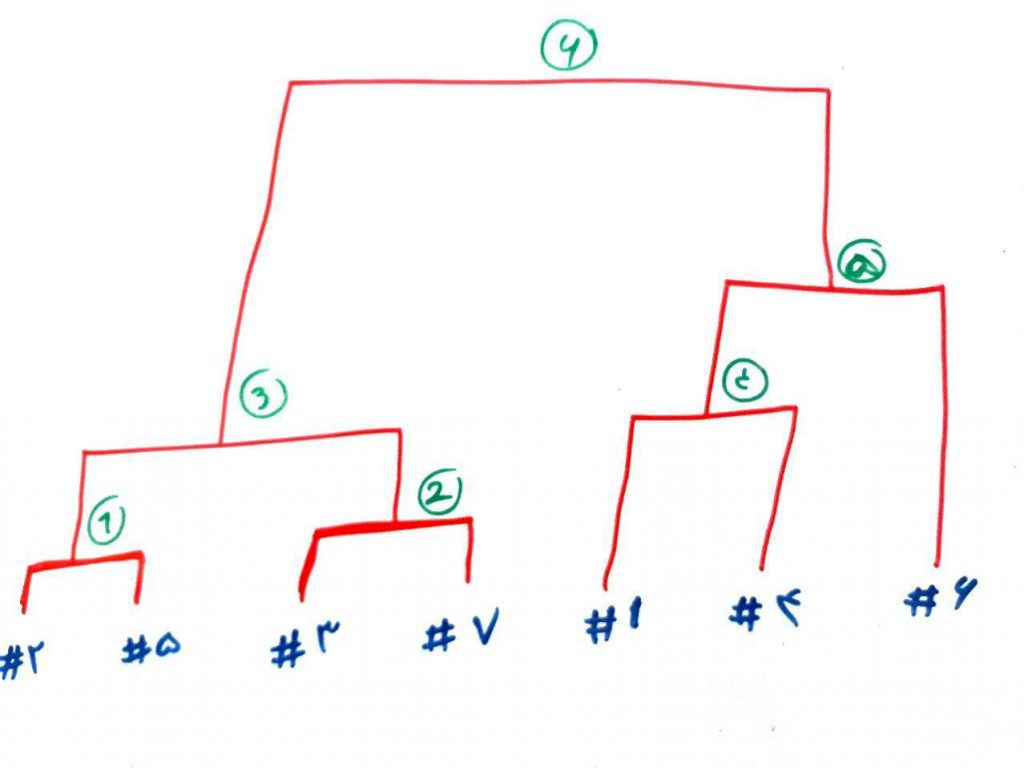
همانطور که میبینید، در ابتدا ۷خوشه داریم (از پایین به بالا ببینید). در مرحلهی اول نمونههای ۲ و ۵ با هم تجمیع میشوند و در مرحله دوم نمونههای ۳ و ۷. به همین ترتیب جلو میرویم تا در مرحله ۶ تمامیِ خوشهها با یکدیگر تجمیع شده و یک خوشهی واحد را میسازند.
معمولاً در خوشهبندیِ سلسله مراتبی شرط پایان (یعنی شرطی که میگذاریم تا دیگر الگوریتم ادامه پیدا نکند) میتواند این باشد که الگوریتم به یک تعداد مشخص خوشه برسد. در مثال بالا، برای شروع، ۷ خوشه داریم (۷ نمونه در فضا) و در مرحلهی ۴، به سه خوشه میرسیم (خوشه اول شامل: ۲-۵-۳-۷، خوشه دوم شامل: ۱-۴ و خوشه سوم شامل ۶). میتوانیم این شرط را بگذاریم که اگر مثلاً به سه خوشه رسیدیم دیگر الگوریتم، مراحلِ خود را ادامه ندهد و این خوشهها به عنوان خوشهی نهایی شناخته شوند.

با سلام و سپاس فراوان از مطالب جذاب البته با طرز بیان شما…
امکانش هست درباره روش های ارزیابی زیرمجموعه ویژگی مانند راهکارهای فیلتر، wrapper، ترکیبی و embedded هم و بخصوص سازوکار embedded توضیحاتی بدهید…
سلام
با تشکر از توضیحاتتون
خیلی عالی بود
زیاد دنبال همچین موضوعی گشتم و اینجا جوابمو کامل گرفتم
اگه امکانش هست دسته بندی مولفه اصلی یا pcaرو هم توضیح بدین
با تشکر
سلام
ممنون از شما. PCA رو هم اینجا میتونید مطالعه کنید
سلام
ممنون از توضیحات روان و مفیدتون
من یه سری داده دارم که مربوط به فروش هست، می خوام خوشه بندی کنم
روش های مختلف رو امتحان کردم (K_means,Hierarchical,…)
وقتی silhouette ها رو با هم مقایسه می کنم یکی از این روش ها از همه بهتره اما وقتی نمودار دو به دوی متغیرها رو می کشم اصلا نقاط خوب از هم تفکیک نشده طبق هیچ کدام از متغیرهام
مثل همیشه عالی.
تشکر
عالی بود ممنون
عاااالی
بسیار عالی بود
با سلام میشه یک نمونه کد هم از این درس در زبان پایتون مثال بزنید ؟
سلام
خسته نباشید توضیحات خیلی عالی بود می شه لطفا مقالات به روز که کلا انواع روش خوشه بندی را به همین سادگی توضیح بدهد چون موضوع پایان نامه بنده در حوزه داده کاوی می باشدراهنمایی بفرمایید .
سلام
عالی بود