

در درسِ دادههای پرت از دورهی آنالیزِ اکتشافی داده و درسِ دادههای نویزدار از دورهی پیشپردازش دادهها، با این مفهوم آشنا شدیم و دیدیم که یک سری از دادهها وجود دارند که با توجه به ویژگیهای مختلفِ مجموعهی داده، با بقیهی دادهها تفاوت میکنند. شکل زیر را به یاد بیاورید:
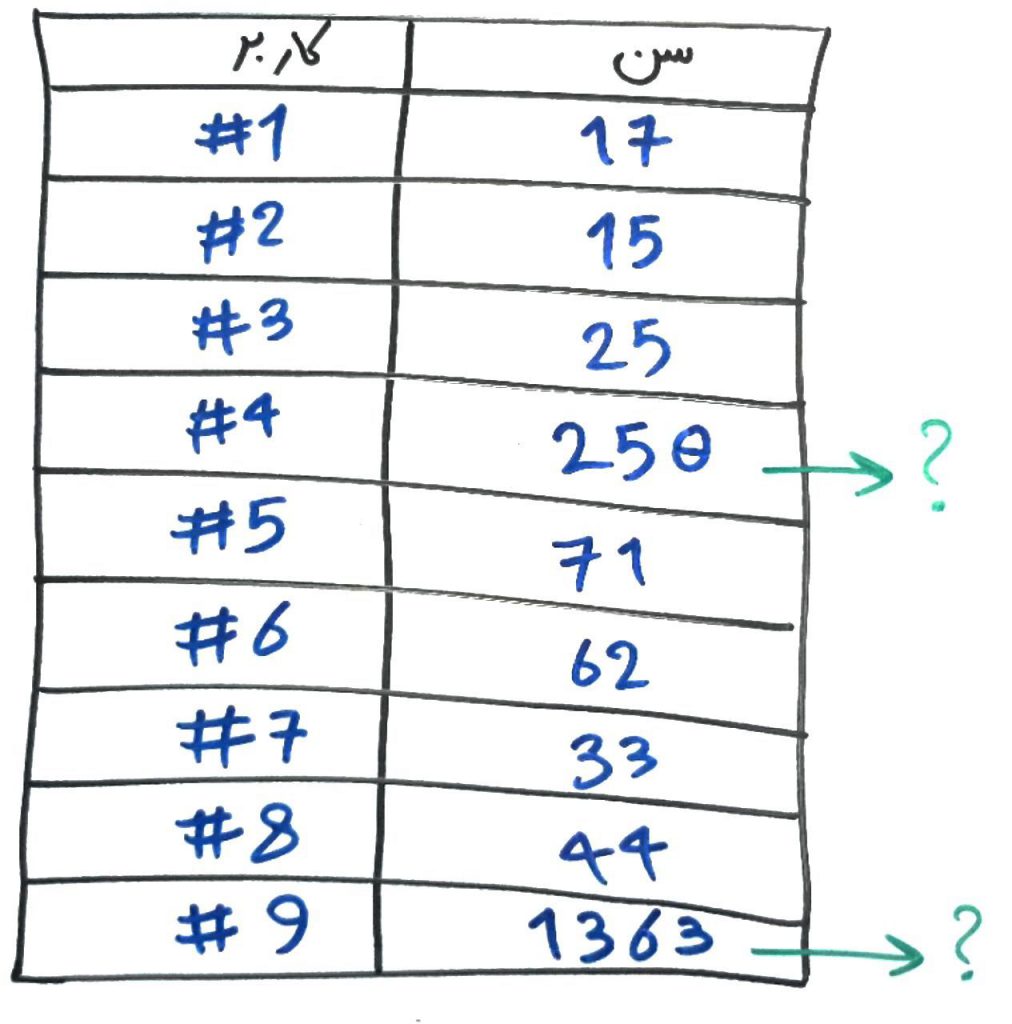
در این تصویر، سنِ ۹نفر از مراجعهکنندگان را از آنها دریافت کردهایم. ولی برای اشخاصِ شمارهی ۴ و ۹ این اعداد به درستی وارد نشده است. همانطور که میبینید شخصِ شمارهی ۴ به نظر یک صفر اضافی برای عددِ سن خود وارد کردهاست و شخصِ شمارهی ۹، به اشتباه، سالِ تولد خود را درج کرده است. پس به جای اینکه سنها بینِ بازهای مانندِ ۱۰ تا ۱۰۰ باشند، بعضی از سنها از این بازه خارج شدهاند. به دست از دادهها دادههای پَرت یا همان Outliers میگویند. میتوان با حذفِ این دادههای پَرت، دادههای مناسبتری را برای تزریق به الگوریتمهای بعدی (مانند طبقهبندی یا خوشهبندی) داشته باشیم. البته که همیشه به دنبال حذفِ دادههای پَرت نیستیم.
اما چرا بایستی دادههای پرت را مورد بررسی قرار دهیم؟ در این درس میخواهیم چند نمونهی کاربردی از تشخیص دادههای پَرت را مورد نظر قرار داده تا بتوانیم یک نگاهِ بازتر به موضوعِ دادههای پَرت داشته باشیم.
فرض کنید مجموعهی دادهای از بیمارانِ مختلف دارید. این مجموعهی داده میتواند شاملِ ویژگیها (ابعاد) مختلف باشد. مثلا سنِ شخص، تعداد دفعات مراجعه به بیمارستان در سال گذشته، سابقهی بیماری مشابه در والدین و… (که اینها ابعاد مسئله را تشریح میکنند-درسِ ویژگی یا همان بُعد چیست را خوانده باشید). حال فرض کنید تعداد ۱۰۰هزار بیمار دارید که برای هر کدام از آنها این اطلاعات را جمعآوری کردهاید. یک متخصص با کمک این اطلاعات احتمالاً میتواند روند بیماریها و الگوهای مشخص را تشخیص دهد. اما ممکن است برخی از افراد، از الگوها و یا گروههای خاصی تبعیت نکنند. برای مثال، ممکن است برخی از افرادْ بیماریهای خاصی داشته باشند که هنوز توسط متخصص به عنوان یک الگو درک نشده باشد. حتی ممکن است برخی افراد در بعضی از ویژگیها به عنوان دادهی پَرت در نظر گرفته شوند. برای مثال یک شخص در بین مجموعهی کلیِ داده عادی باشد ولی در بینِ هم سن و سالهای خود به عنوان نمونهای پَرت در نظر گرفته شود. مثلاً ممکن است فردی که ۱۲ سال دارد با میزان قندِ خونِ ۱۰۰، در میانِ تمامِ افرادِ مجموعه، طبیعی به نظر برسد ولی در میانِ افرادی در بازهی سنیِ ۱۰ تا ۱۵ سال (هم سن و سالهای خودش)، به عنوانِ یک دادهی پَرت و غیرعادی باشد (البته این صرفاً یک مثال بود و پایهی پزشکی نداشت). پس به دست آوردنِ دادههای پَرت در حوزهای مانندِ پزشکی نیز به این صورت میتواند کمک کننده باشد.
مثالِ دیگری که میتواند به خوبی بیانگرِ کاربرد این حوزه باشد، تشخیص دزدیده شدنِ کارتهای بانکی است. فرض کنید یک کارتِ بانکی دارید و به صورت معمول و عادی از این کارت استفادههایی میکنید. مثلاً حقوقِ ماهیانهی شما به این کارت واریز میشود و شما در طولِ ماه آرام آرام آن مبالغ را توسط دستگاههای POS دریافت کرده و یا به صورت اینترنتی از فروشگاههای مشخص خرید میکنید. حال کارتِ شما دزدیده میشود و این شخص سریعاً به محلِ دیگری رفته و با دانستن رمزِ کارت، سریعاً درخواست دریافتِ مبلغی نامتعارف را از یک دستگاهِ POS در یک زمان نامتعارف انجام میدهد. این کار یک عملِ غیر طبیعی (برای کارتِ شما) است، و اگر یک الگوریتمِ تشخیص دادههای (یا همان فرآیندهای) پَرت در شبکهی شتاب موجود باشد، احتمالاً میتواند این عملیات را شناسایی کرده و کارتِ بانکی را به عنوان دزدیده شده ضبط نماید (و یا درخواست رمزی مانند رمزِ دوم انجام شود).
در حوزههایی مانندِ ورزشِ فوتبال نیز میتوان از دادهکاوی و فرآیندهای تشخیصِ دادههای پَرت استفاده کرد. برای مثال از طریقِ سنسورهایی که به بازیکنان متصل است و با کمکِ تحلیلِ آنها در شرایطِ مختلف، میتوان بازیکنانی که تواناییهای بالاتری (با توجه به شرایط) دارند را کشف کرد. برای مثال، برخی از بازیکنان در شرایطِ جویِ بارانی، عملکردِ بهتری از خود به نمایش میگذارند و در واقع به عنوان یک دادهی پَرت، از سایر بازیکنان جدا شده و شناسایی میشوند.
اینها نمونههایی از کاربردهای مختلفِ تشخیصِ دادههای پَرت بود. همانطور که متوجه شدید، دادههای پَرت لزوماً یک عنصر نامطلوب نیستند و در بسیاری از مواقع ما به دنبال دادههای پَرت میگردیم تا از آنها استفاده کنیم.

- ۱ » کاربرد یافتن دادههای پرت (Outlier Detection) در دادهکاوی
- ۲ » تستهای آماری (Statistical Test) جهت تشخیص دادههای پرت
- ۳ » محاسبهی دادههای پَرت با استفاده از z-score
- ۴ » الگوریتم جنگل ایزوله (Isolation Forest) جهت تشخیص دادههای پرت
- ۵ » کاربرد الگوریتم DBSCAN در تشخیص دادههای پَرت (Outliers)
- ۶ » الگوریتم ABOD جهت تشخیص دادههای پرت از طریق زاویه