

یکی از کاربردهای متنکاوی که بسیار مورد توجهِ متخصصان و دانشمندان علومداده قرار گرفته است، تحلیل احساسات یا همان Sentiment Analysis میباشد. تحلیل احساسات میتواند به معنیِ پیدا کردنِ احساس یا حالت گفتار (مثبت، منفی یا خنثی و یا موارد دیگر) در متون باشد. فرض کنید قبل از انتخاباتِ ریاست جمهوری یک گروهِ سیاسی به شما پیشنهاد داده است که نظراتِ مختلفِ مردم در شبکههای اجتماعی را جمعآوری کنید و بگویید که مردم در این نظرات، حس خوبی به گروهِ سیاسی داشتهاند یا خیر؟ و یا نسبت یا درصدِ این نظرات را بگویید. این یک نوع مسئلهی تحلیل احساسات است که در این درس به آن میپردازیم.
اگر درس طبقهبندی را خوانده باشید حتماً متوجه میشوید که مسئلهی تحلیل احساسات یک مسئلهی طبقهبندی است. در واقع در طبقهبندی ما یک مجموعهی داده از نمونههای مختلف داریم که هر کدام از آن نمونهها را برچسب میزنیم (با توجه به طبقههای موجود) و بعد، این مجموعه را به الگوریتمِ طبقهبندی میدهیم تا الگوریتم از روی این مجموعه یادگیری را انجام دهد. بعد از اینکه الگوریتمِ طبقهبندی، یادگیری را انجام داد، میتوانیم دادههای جدیدتر را به این الگوریتم بدهیم و این الگوریتم میتواند برچسب مناسب برای دادههای جدید را شناسایی کند. مسئلهی تحلیل احساسات برای یک گروه سیاسی قبل از انتخابات را تصور کنید. فرض کنید شما ۱میلیون متن از سراسر وب دربارهی این گروه سیاسی جمعآوری کردهاید. حال میخواهید ببینید که هر متن، به کدام دستهی مثبت، منفی یا خنثی تعلق دارد. در واقع در اینجا ۱میلیون متن (نمونهها یا مجموعههای آموزشی) و ۳طبقه (Class) که بایستی هر کدام از این نمونهها را به یکی از این ۳طبقه برچسب بزنیم. طبیعتاً فرصت ندارید که تمامیِ این ۱میلیون متن را بخوانید و هر کدام را تحلیل کنید. پس میتوانید با خواندنِ یک قسمت از آن (مثلا ۱۰۰۰نمونه) و تحلیل این قسمت، یک مجموعهی دادهی آموزشی درست کنید. این مجموعهی دادهی آموزشی میتواند پایهی یادگیری برای تزریق به الگوریتمِ طبقهبندی باشد.
مثلاً فرض کنید ۵جملهی زیر، نمونههایی از مجموعهی دادهی آموزشیِ ما هستند که برچسبِ مناسب را برای آنها (توسط یک شخصِ ناظر) انتخاب کردهایم:
۱. من از آقای فلانی خوشم میآید. برنامههایش به نظر کاربردی میرسند (مثبت)
۲. آقای فلانی، سابقهی خوبی در مدیریتِ وزرات خانه داشته (مثبت)
۳. من کلا از فلانی خوشم نمیاد. فکر میکنم آدم خوبی نیست (منفی)
۴. اصلاً کاری به کارِ سیاست ندارم (خنثی)
۵. فلانی فکر کرده با چهار تا حرف میتونه رای مردم رو بخره (منفی)
این یک نمونه از مجموعهی دادهای بود که برای تزریق به الگوریتمِ دادهکاوی آماده کردهایم. الگوریتمِ طبقهبندی در اینجا میتواند یکی از الگوریتمهای ارائه شده در دورهی طبقهبندی یا هر الگوریتم دیگری باشد. شکل زیر میتواند یک شِما از نحوهی یادگیری برای این متون باشد:
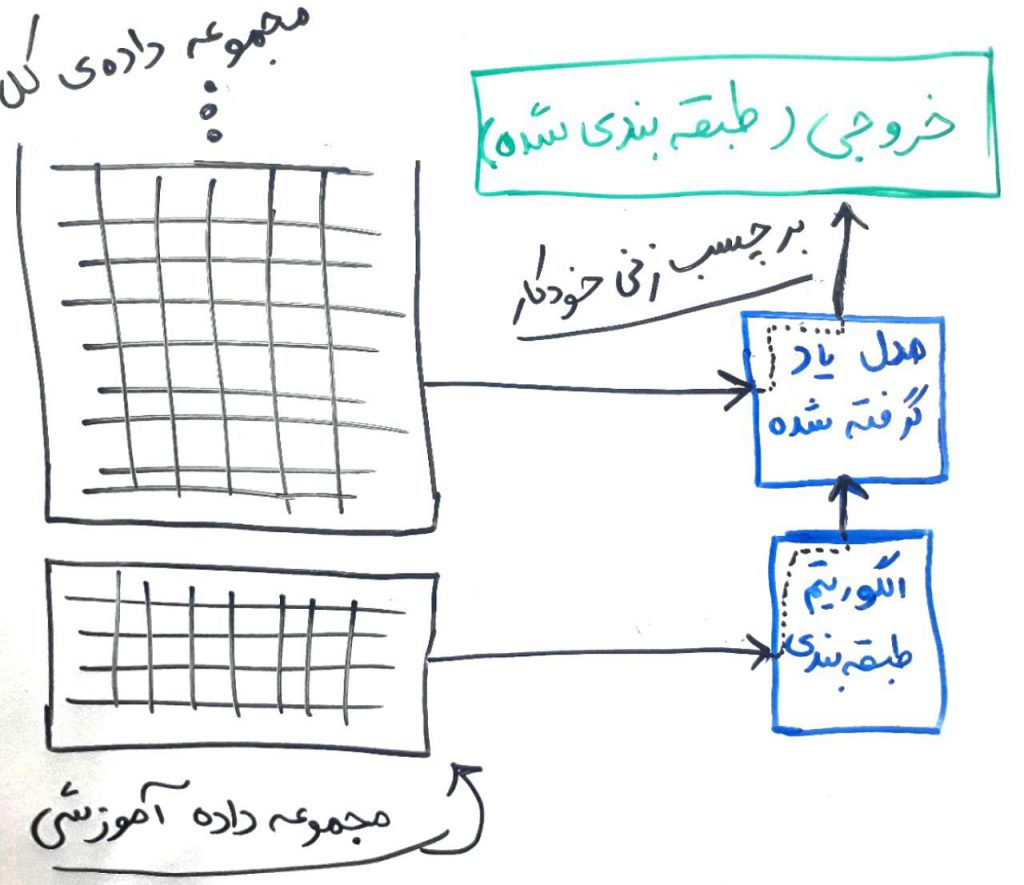
همانطور که میبینید مجموعهی دادهای را که به صورت ماتریس درآوردیم (مهندسی ویژگی کردیم) به الگوریتمِ طبقهبندی دادیم و این الگوریتم یادگیری را انجام داد. توجه کنید که مجموعهی آموزشی توسطِ یک شخص (ناظر) برچسب زده شده است و در واقع دارای برچسب است. بعد از آن، این الگوریتم میتواند با استفاده از مدلی که از روی مجموعهی آموزشی یادگرفته است، طبقهبندی (تحلیل احساس) را بر روی بقیهی دادهها (که برچسب ندارند) انجام دهد و هر کدام از متون را به طبقهی درست، برچسبزنی کند.
حتماً درسهای قبلیِ دورهی جاری را خواندهاید. الگوریتمِ طبقهبندی، نمیتواند دادههای غیرساختاریافتهی متنی را متوجه شود. پس بایستی با یک پیشپردازش مانند BoW، متون را برای این الگوریتم به حالتِ ماتریسی تبدیل کرد. در واقع الگوریتم از روی کلمات و تکرار آنها، میتواند تشخیص دهد که یک متنِ جدید به کدام دسته (مثبت، منفی یا خنثی) تعلق دارد. مثلاً الگوریتم آرام آرام با دیدن نمونههای موجود در مجموعهی آموزشی (همان مجموعهای که توسط ناظر برچسب زده شده است)، میتواند بفهمید که وجود کلمهای مانند “خوب”، به مثبت بودن احساس در متن کمک میکند و یا کلمهای مانند “بد” میتواند به منفی شدن متن کمک کند. در اینجا متوجه میشویم که هر چقدر مجموعهی آموزشی بهتر و بزرگتر باشد، یادگیریِ الگوریتم بهتر خواهد بود. مانند دانشآموزی که تمرینهای بیشتری را قبل از امتحان حل کرده است و در موقع امتحان، یا اطمینانِ بیشتر میتواند به سوالات پاسخ دهد.

- ۱ » متن کاوی (Text Mining) و پردازش زبان طبیعی (NLP) چیست؟
- ۲ » ساخت کولهی کلمات (Bag of Words) در پیشپردازش متون
- ۳ » روش TF-IDF برای ساختاردهی به دادههای متنی
- ۴ » تحلیل احساسات (Sentiment Analysis) در متنکاوی
- ۵ » n-gram و کاربرد آن در متنکاوی
- ۶ » مدلسازی موضوعات (Topic Modeling) و کاربرد آن در متنکاوی
- ۷ » یافتن ریشه کلمات با Stemming و Lemmatization
- ۸ » تشخیص شباهت متون (Text Similarity) با استفاده از الگوریتم Jaccard
- ۹ » خوشهبندی متون (Text Clustering) و کاربردهای آن