

در درس قبلی با بحثِ پس انتشارِ خطا آشنا شدیم و متوجه شدیم که شبکههای عصبی برای به هنگامسازیِ وزنها و انحراف، باید عملیاتِ پس انتشار را در هر بار اجرای الگوریتم انجام دهند. هر تکرار از اجرای الگوریتم که یک iteration شناخته میشود، میتواند وزن و انحرفها را به گونهای به هنگام (update) کند که الگوریتمِ شبکهی عصبی بتواند ویژگیهای مختلف و طبقههای متفاوت را شناسایی کند. برای درکِ بهتر فرض کنید خودتان در مدرسه برای امتحانِ نهایی آماده میشوید و میخواهید چند مرتبه از روی کتاب روخوانی کنید. در واقع شما هم به نوعی iterate را انجام میدهید.
در این درس به بحثِ کاهش گرادیان (gradient descent) در شبکههای عصبی میپردازیم که در واقع پایهی عملیات پس انتشار خطا میباشد.
شکل زیر را از درس قبل به خاطر دارید:
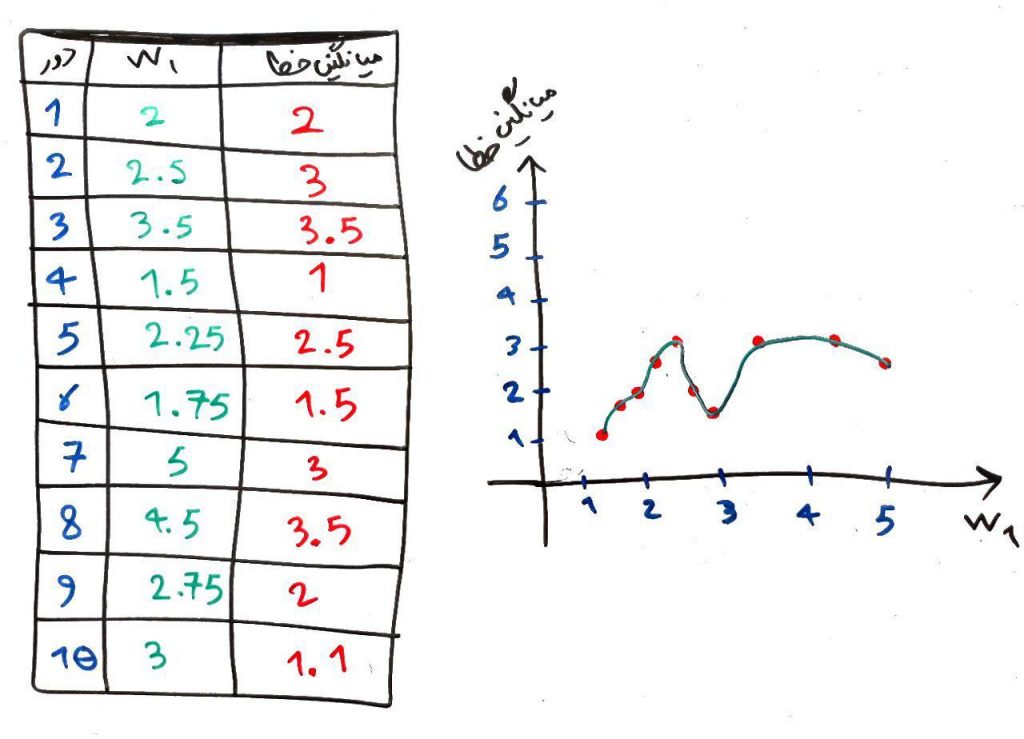
گفتیم که در این مثال به دنبال کمترین مقدارِ خطا میگردیم. که با توجه به وزنها کمترین میزانِ خطا در وزن ۱.۵ رخ داده است که مقدارِ آن برابر ۱ است. یعنی ما با کم و زیاد کردنِ مقدارِ وزن میخواهیم کمترین میزانِ خطا را مشخص کنیم. اما در شبکههای عصبی (همانطور که بعداً خواهیم دید) تعداد بسیار بیشتری وزن خواهیم داشت که بایستی بههنگام (update) شوند. مثلاً در یک شبکهی عصبی برای پردازش تصویر ممکن است تا ۱۰۰۰ یا بیشتر وزن داشته باشیم که در این صورت باید تابعِ خطا را با توجه به هر ۱۰۰۰ وزنِ مختلف ارزیابی کرده و سپس هر کدام از این وزنها را تغییر داده و دوباره تست کنیم تا میزان خطا به دست آید. همانطور که تصور میکنید این عملیات بسیار وقتگیر و پرهزینه است. برای غلبه بر این مشکل از روشی به اسم کاهش گرادیان استفاده میشود که در این درس به آن میپردازیم.
فرض کنید به جای مثال بالا، نمودار (که در واقع بیانگر خطاها در وزنهای مختلف است) مقادیرِ خطا برای وزن w1 به صورت زیر باشد:
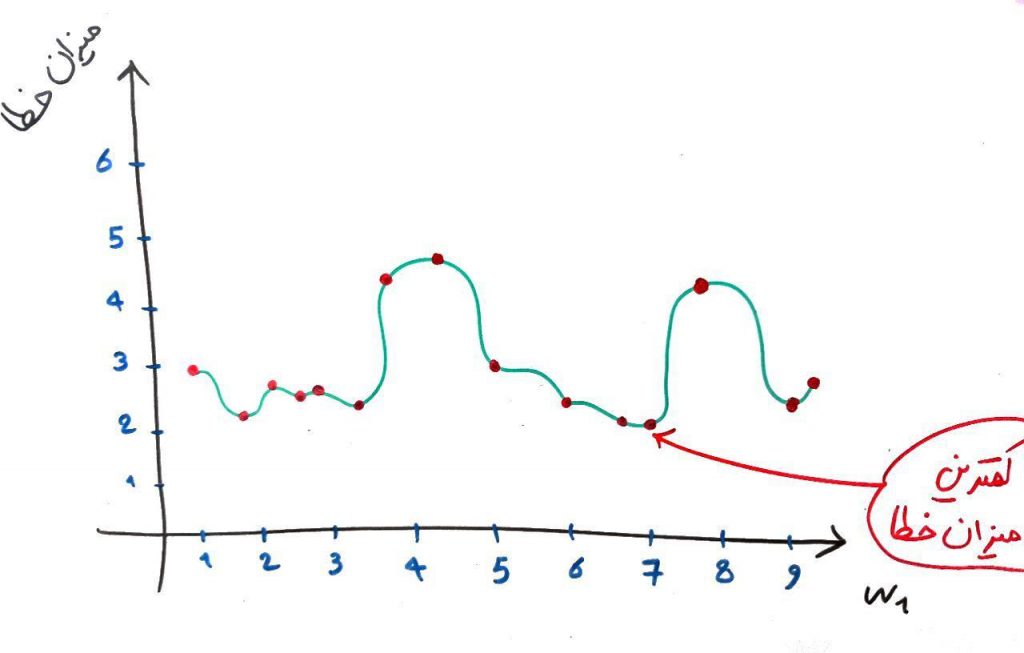
همان طور که مشاهده میکنید، کمترین میزان خطا در وزن ۷ اتفاق افتاده است. در روشِ کاهش گرادیان برای پیدا کردن این وزن از قوانین مشتق استفاده میشود. همانطور که میدانید مشتق، نشاندهندهی شیبِ خطِ مماس بر یک نقطه از یک تابع است. برای اینکه کمترین میزانِ خطا را به دست آوریم فرض میکنیم یک نقطهی دلخواه (یک وزن دلخواه) را در این تابع در نظر گرفتهایم. مثلاً نقطهی ۱ (یعنی وزن ۱). حال به تصویر زیر نگاه کنید:
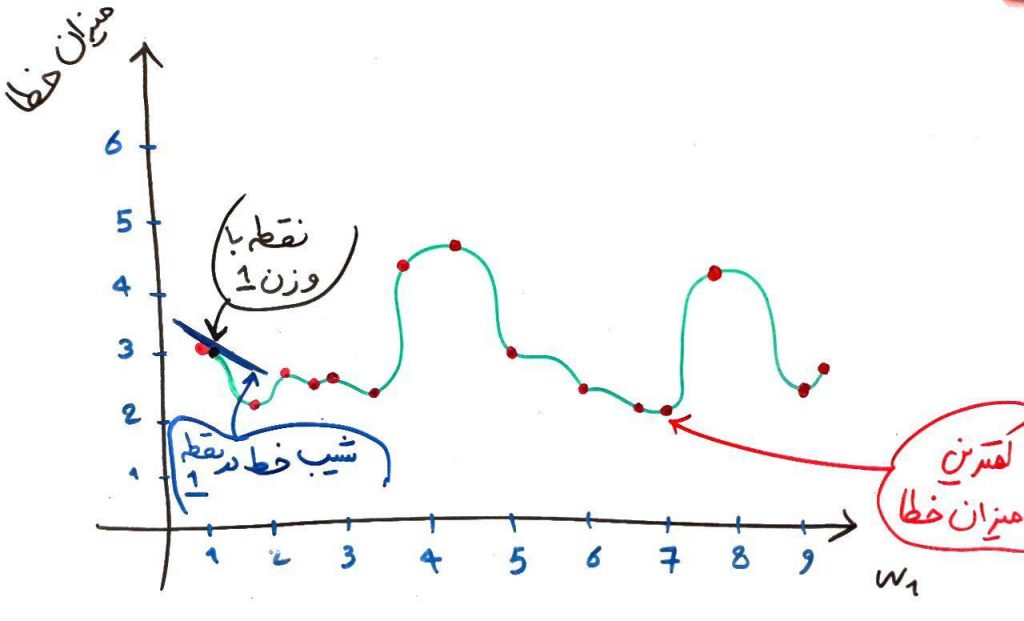
در این نقطه مشتق که همان شیب خطِ مماس بر یک نقطه است یک عدد منفی بوده، چون خط به سمت پایین است. الگوریتمِ پس انتشار میداند که اگر شیبِ خط در یک نقطه (با توجه به وزنها) منفی بود بایستی مقدار آن وزن را افزایش دهد تا شیب خط به صفر برسد. شیب صفر یعنی کمترین میزان خطای ممکن در آن محدوده (برای درکِ بهتر، در همان تصویر بالا، شیب در محدودهی وزنِ ۱.۷۵ را نگاه کنید، یعنی جایی که خطِ سبز در کمترین میزانِ خود قرار دارد). همانطور که در شکلِ بالا مشخص است، کمترین میزانِ خطای ممکن در آن محدوده برای وزن ۱.۷۵ ثبت شده است که شیبِ خط در آنجا صفر است (موازی محور افقی است)، حال اگر کمی مقدار وزن را از ۱.۷۵ بیشتر کنیم شیب خط مثبت میشود، یعنی شیب به سمت بالا میرود. با مثبت بودنِ شیب خط، یعنی همان مشتق در آن نقطه، الگوریتمِ پس انتشار میفهمد که باید وزن را کم کند تا شیب به صفر برسد.
همان طور که در یک مثال بالا دیدید، الگوریتمِ پس انتشار میتواند با استفاده از این این تکنیک یک نقطهی کمینه برای خطا پیدا کند که البته کمترین مقدار در کل فضا نبود ولی به هر حال معقول به نظر میرسید. به این نقطهی معقول یک کمینهی محلی (local minimum) برای خطا میگویند. در شکل بالا وزن ۷ یک کمینهی سراسری، یعنی بهترین نقطه موجود در کل شکل (global minimum) است. البته رسیدن به این نقطهی سراسری برای الگوریتمِ پس انتشارِ خطا کار دشوار و زمانبری است.
برای همین معمولاً الگوریتم در شبکههای عصبی اینگونه آموزش میبیند که به تعداد تکرار مشخص یا تا رسیدن به یک خطای کمِ مشخص الگوریتم را ادامه بدهد و بعد از آن توقف کند. یعنی شبکه عصبی آنقدر تکرار را انجام میدهد تا به یک خطای معقول مشخصِ کم برسد . مثلاً در مثالِ بالا میگوییم اگر خطا زیر ۲/۵ شد دیگر کافی است. اگر این طور نشد یعنی خطا به اندازهی دلخواهِ ما کم نشده است و حالا میتوانیم برای تکرار محدودیت بگذاریم. مثلاً میگوییم تا ۱۰ هزار مرتبه تکرار را انجام بده (یعنی ۱۰ هزار مرتبه وزنها و انحراف را آپدیت کن) و بعد از آن دیگر یادگیری را ادامه نده.
حال که یادگیری انجام شد، شبکه دارای وزنها و انحرافِ مشخص است. از این به بعد شبکه میتواند یک سری ویژگی (مثلاً ویژگیهای یک پراید یا اتوبوس) را بگیرد و تشخیص دهد که این یک پراید است یا خیر. که البته همان طور که واضح است، این پیشبینی دارای خطایی نیز هست.
مثال بالا یک حالت بسیار بسیار ساده فقط با یک وزن بود. در شبکههای عصبی که وزنهای بسیار زیاد، تا ۱۰۰۰ یا بیشتر – با توجه به تعداد ویژگیها یا همان ابعاد، برای بههنگامسازی وجود دارد سرعتِ روش کاهش گرادیان به خوبی نمایان میشود چرا که روشِ پس انتشارِ خطا همراه با کاهشِ گرادیان میتواند بسیار سریع نقطهی کمینهی معقولی برای خطا را پیدا کند. البته که انواع مختلفی از روشهای کاهشِ گرادیان (یا همان صفر کردنِ مشتق) وجود دارد که در درسی جدا به آنها خواهیم پرداخت.
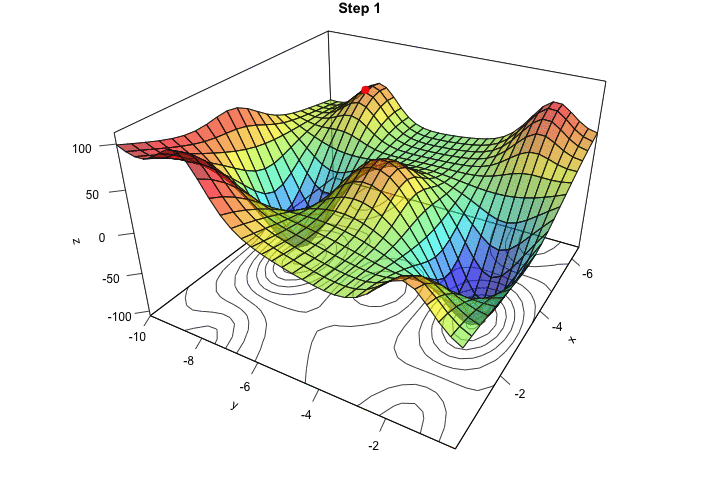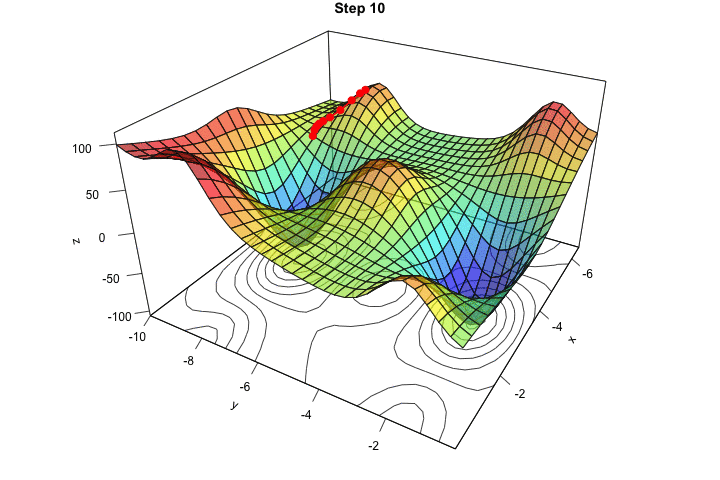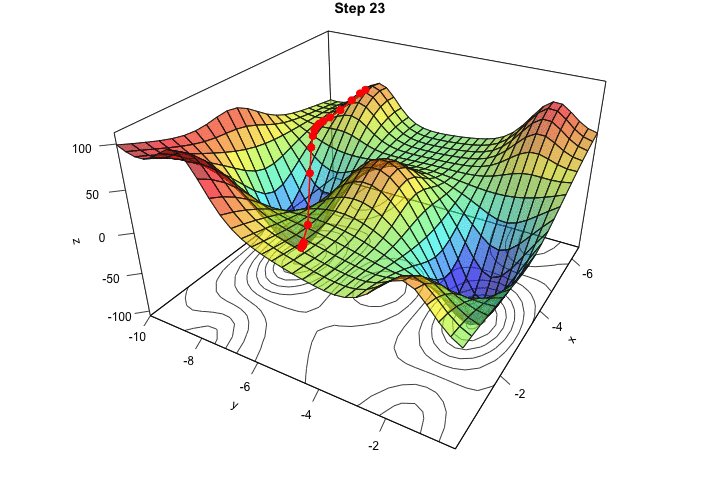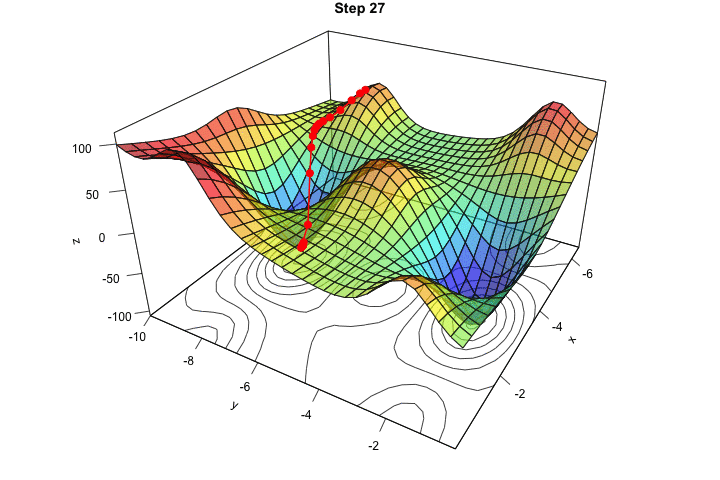
در شکل زیر هم در یک انیمیشن میتوانید ببینید که کاهش گرادیان چگونه در یک فضای ۲ بُعدی (با ۲ متغیر) کار میکند:

- ۱ » شبکه عصبی (Neural Network) چیست؟
- ۲ » تعریف پرسپترون (Perceptron) در شبکه های عصبی
- ۳ » پرسپترون در شبکه عصبی چگونه یاد میگیرد؟
- ۴ » پرسپترون چند لایه (Multi Layer Perceptron) چیست؟
- ۵ » درباره توابع فعال سازی پرسپترون و Sigmoid
- ۶ » تابع ضرر (Loss Function) در شبکه عصبی چیست و چه کاربردی دارد؟
- ۷ » نحوه یادگیری پس انتشار خطا (Back Propagation) در شبکه های عصبی
- ۸ » کاهش گرادیان (Gradient Descent) در شبکه های عصبی
- ۹ » حل یک مثال عددی یادگیری ماشین با شبکههای عصبی
سلام
خیلی عالی و مفهومی
خداخیرتون بده
سلام
ساده سازی در آموزشِ مقوله های علمی سنگین، نشان از نبوغ و مناعت طبعِ آموزش دهنده دارد. بسیار بسیار سپاسگزارم.
سلام
وقتتون بخیر
واقعا کارتون خیلی عالی و با ارزش هست تعدادی آموزش دیگر را هم دنبال کردم اما برای شما میشه گفت ساده و در عین حال بسیار قابل فهم بود.
با این اوضاع موجود در بین عده ای استاد بی سواد اگر این آموزش را ادامه بدید کمک بزرگی به کسانی میکنید که هدف یادگیری دارند و تعداد این اساتید بی سواد در آینده کم میشه…
لطفا ادامه بدید
خیلی خیلی ممنون
خدا خیرتون بده
بسیار عالی باید ممنون بود از شما و موسس وبسایت ک همچین بستری فراهم کرده سپاس
بسیار عالی، ممنون از مطالب خوبتون خیلی ساده و قابل فهم بیان شده.
با سلام جناب کاویانی عزیز و عرض دست مریزادی به حضورتون که چنین مطالب را روان و قابل فهم ارائه کردین ،مشتاق پیگیری بیشتری هستیم خوشحال میشیم راهنمایی فرمایید
آقا خیلی مرسی و دمتون گرم . امیدوارم همیشه موفق باشید . آموزش عالی بود. و به نظرم این نوع تدریس درست ترین تدریس هست . همراه با مثال و با بیانی ساده . ( به قول اینشتین اگه یکی تونست یه مفهوم (فیزیکی) رو به ساده ترین وجه توضیح بده که قابل فهم برای هرکسی( چ مادر بزرگتون! چ یه بچه ۶ ساله ) اون موقع کاربزرگی انجام داده
زبان ساده و مثال های ساده ی که زده شده مطالب رو واقعا در حد خیلی خوبی برای آشنایی و جا افتادن مفاهیم اولیه انجام داده
خسته نباشید میگم کارتون فوق العاده ارزشمنده
واقعا عالی بود، خیلی کارم رو راه انداخت.
ادامه بدید لطفا.
سلام ،خیلی عالی بود.ممنون
مرسی از مطالبتون. خوب بودن. فقظ سوال اینکه گرادیان کاهشی برای ۱۰۰۰ ویژگی چطور عمل میکند و به نتیجه میرساند مسله رو…
عالی عالی دمتون گرم
تشکر نمیتونه جوابگوی زحمات شما باشه. دست مریزاد، عالی آموزش دادید
واقعا عالی بود سلیس و روان
عالی بود. خدا خیر بده به شما و همکاراتون. فقط کاش بیشتر و کامل تر بود.
در یک کلام
عالی
سلام. خدا قوت. لذت بردم. بسیار روان و ساده، مبانی شبکه های عصبی رو آموزش دادید.
سلام جناب استاد کاویانی. مطالبتون عالی بود. انشاله همیشه شاد و سلامت باشید. خواهش میکنم ادامه مطالب را هم بزارید.
یکی از بهترین آموزش های شبکه عصبی بود که من خوندم تازه فهمیدم اساس شبکه عصبی چیه….واقعا خسته نباشید
واقعا ممنون، من چقدر خوشبختم تو همین مرحله اول با سایتتون اشنا شدم چون ازکامنتها فهمیدم خیلیها بعد منابع زیاد با شما اشکالاتشون رفع شد. درسهاتون تاریخ ندارن و یا حداقل من زمان بروز رسانیشون رو ندیدم. لطفا میفرمایید درس رو کامل میکنید یا خیر؟ اگه مبحثش کامل شده امکان خریداریش هست تا برای من که عجله دارم با مبحث شبکه های عصبی اشنا شم بهش دسترسی کامل داشته باشم