

در درس قبلی با بحثِ پس انتشارِ خطا آشنا شدیم و متوجه شدیم که شبکههای عصبی برای به هنگامسازیِ وزنها و انحراف، باید عملیاتِ پس انتشار را در هر بار اجرای الگوریتم انجام دهند. هر تکرار از اجرای الگوریتم که یک iteration شناخته میشود، میتواند وزن و انحرفها را به گونهای به هنگام (update) کند که الگوریتمِ شبکهی عصبی بتواند ویژگیهای مختلف و طبقههای متفاوت را شناسایی کند. برای درکِ بهتر فرض کنید خودتان در مدرسه برای امتحانِ نهایی آماده میشوید و میخواهید چند مرتبه از روی کتاب روخوانی کنید. در واقع شما هم به نوعی iterate را انجام میدهید.
در این درس به بحثِ کاهش گرادیان (gradient descent) در شبکههای عصبی میپردازیم که در واقع پایهی عملیات پس انتشار خطا میباشد.
شکل زیر را از درس قبل به خاطر دارید:
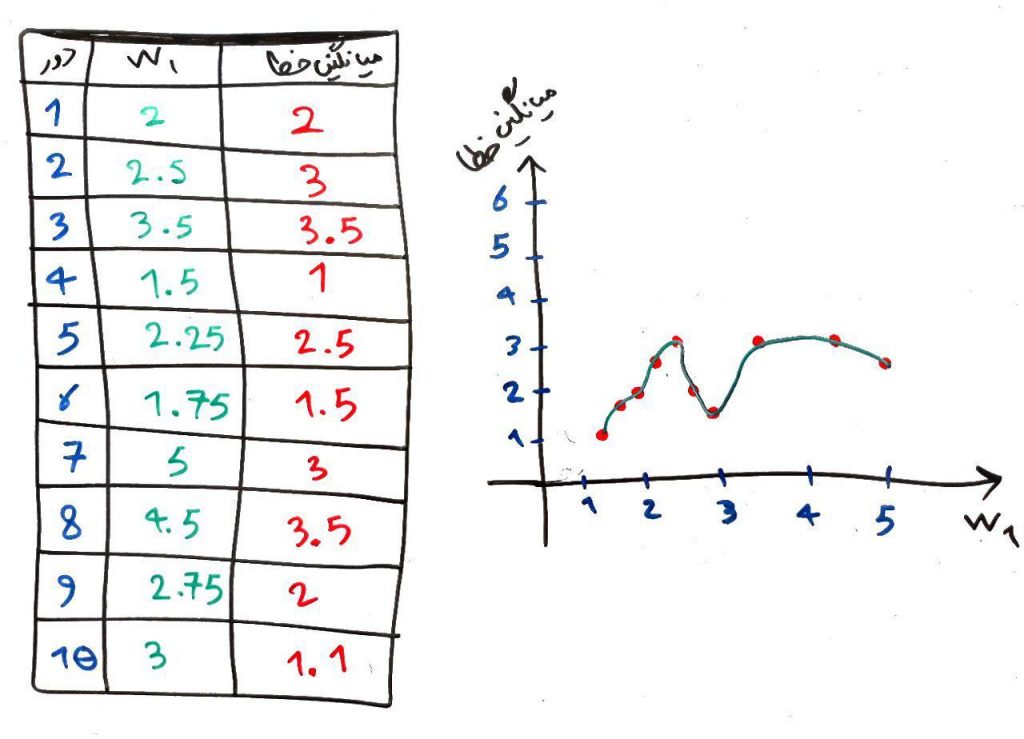
گفتیم که در این مثال به دنبال کمترین مقدارِ خطا میگردیم. که با توجه به وزنها کمترین میزانِ خطا در وزن ۱.۵ رخ داده است که مقدارِ آن برابر ۱ است. یعنی ما با کم و زیاد کردنِ مقدارِ وزن میخواهیم کمترین میزانِ خطا را مشخص کنیم. اما در شبکههای عصبی (همانطور که بعداً خواهیم دید) تعداد بسیار بیشتری وزن خواهیم داشت که بایستی بههنگام (update) شوند. مثلاً در یک شبکهی عصبی برای پردازش تصویر ممکن است تا ۱۰۰۰ یا بیشتر وزن داشته باشیم که در این صورت باید تابعِ خطا را با توجه به هر ۱۰۰۰ وزنِ مختلف ارزیابی کرده و سپس هر کدام از این وزنها را تغییر داده و دوباره تست کنیم تا میزان خطا به دست آید. همانطور که تصور میکنید این عملیات بسیار وقتگیر و پرهزینه است. برای غلبه بر این مشکل از روشی به اسم کاهش گرادیان استفاده میشود که در این درس به آن میپردازیم.
فرض کنید به جای مثال بالا، نمودار (که در واقع بیانگر خطاها در وزنهای مختلف است) مقادیرِ خطا برای وزن w1 به صورت زیر باشد:
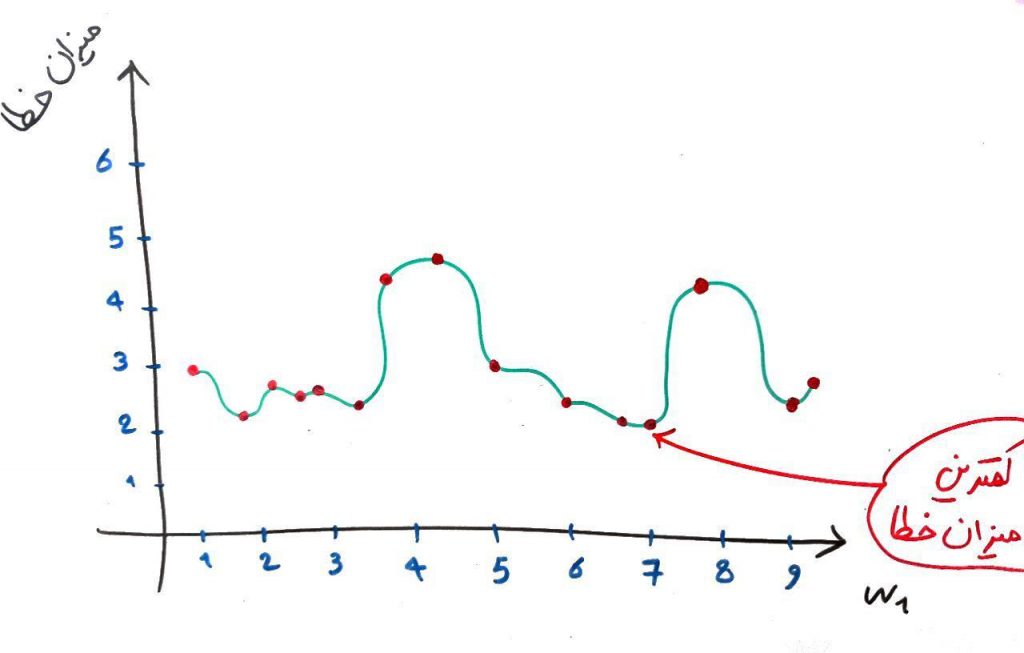
همان طور که مشاهده میکنید، کمترین میزان خطا در وزن ۷ اتفاق افتاده است. در روشِ کاهش گرادیان برای پیدا کردن این وزن از قوانین مشتق استفاده میشود. همانطور که میدانید مشتق، نشاندهندهی شیبِ خطِ مماس بر یک نقطه از یک تابع است. برای اینکه کمترین میزانِ خطا را به دست آوریم فرض میکنیم یک نقطهی دلخواه (یک وزن دلخواه) را در این تابع در نظر گرفتهایم. مثلاً نقطهی ۱ (یعنی وزن ۱). حال به تصویر زیر نگاه کنید:
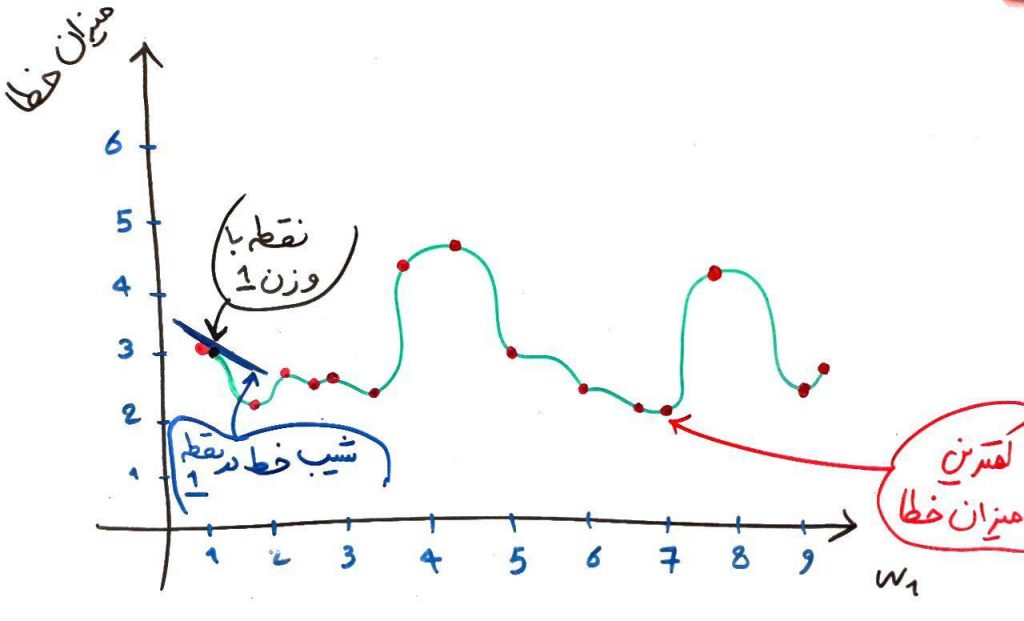
در این نقطه مشتق که همان شیب خطِ مماس بر یک نقطه است یک عدد منفی بوده، چون خط به سمت پایین است. الگوریتمِ پس انتشار میداند که اگر شیبِ خط در یک نقطه (با توجه به وزنها) منفی بود بایستی مقدار آن وزن را افزایش دهد تا شیب خط به صفر برسد. شیب صفر یعنی کمترین میزان خطای ممکن در آن محدوده (برای درکِ بهتر، در همان تصویر بالا، شیب در محدودهی وزنِ ۱.۷۵ را نگاه کنید، یعنی جایی که خطِ سبز در کمترین میزانِ خود قرار دارد). همانطور که در شکلِ بالا مشخص است، کمترین میزانِ خطای ممکن در آن محدوده برای وزن ۱.۷۵ ثبت شده است که شیبِ خط در آنجا صفر است (موازی محور افقی است)، حال اگر کمی مقدار وزن را از ۱.۷۵ بیشتر کنیم شیب خط مثبت میشود، یعنی شیب به سمت بالا میرود. با مثبت بودنِ شیب خط، یعنی همان مشتق در آن نقطه، الگوریتمِ پس انتشار میفهمد که باید وزن را کم کند تا شیب به صفر برسد.
همان طور که در یک مثال بالا دیدید، الگوریتمِ پس انتشار میتواند با استفاده از این این تکنیک یک نقطهی کمینه برای خطا پیدا کند که البته کمترین مقدار در کل فضا نبود ولی به هر حال معقول به نظر میرسید. به این نقطهی معقول یک کمینهی محلی (local minimum) برای خطا میگویند. در شکل بالا وزن ۷ یک کمینهی سراسری، یعنی بهترین نقطه موجود در کل شکل (global minimum) است. البته رسیدن به این نقطهی سراسری برای الگوریتمِ پس انتشارِ خطا کار دشوار و زمانبری است.
برای همین معمولاً الگوریتم در شبکههای عصبی اینگونه آموزش میبیند که به تعداد تکرار مشخص یا تا رسیدن به یک خطای کمِ مشخص الگوریتم را ادامه بدهد و بعد از آن توقف کند. یعنی شبکه عصبی آنقدر تکرار را انجام میدهد تا به یک خطای معقول مشخصِ کم برسد . مثلاً در مثالِ بالا میگوییم اگر خطا زیر ۲/۵ شد دیگر کافی است. اگر این طور نشد یعنی خطا به اندازهی دلخواهِ ما کم نشده است و حالا میتوانیم برای تکرار محدودیت بگذاریم. مثلاً میگوییم تا ۱۰ هزار مرتبه تکرار را انجام بده (یعنی ۱۰ هزار مرتبه وزنها و انحراف را آپدیت کن) و بعد از آن دیگر یادگیری را ادامه نده.
حال که یادگیری انجام شد، شبکه دارای وزنها و انحرافِ مشخص است. از این به بعد شبکه میتواند یک سری ویژگی (مثلاً ویژگیهای یک پراید یا اتوبوس) را بگیرد و تشخیص دهد که این یک پراید است یا خیر. که البته همان طور که واضح است، این پیشبینی دارای خطایی نیز هست.
مثال بالا یک حالت بسیار بسیار ساده فقط با یک وزن بود. در شبکههای عصبی که وزنهای بسیار زیاد، تا ۱۰۰۰ یا بیشتر – با توجه به تعداد ویژگیها یا همان ابعاد، برای بههنگامسازی وجود دارد سرعتِ روش کاهش گرادیان به خوبی نمایان میشود چرا که روشِ پس انتشارِ خطا همراه با کاهشِ گرادیان میتواند بسیار سریع نقطهی کمینهی معقولی برای خطا را پیدا کند. البته که انواع مختلفی از روشهای کاهشِ گرادیان (یا همان صفر کردنِ مشتق) وجود دارد که در درسی جدا به آنها خواهیم پرداخت.
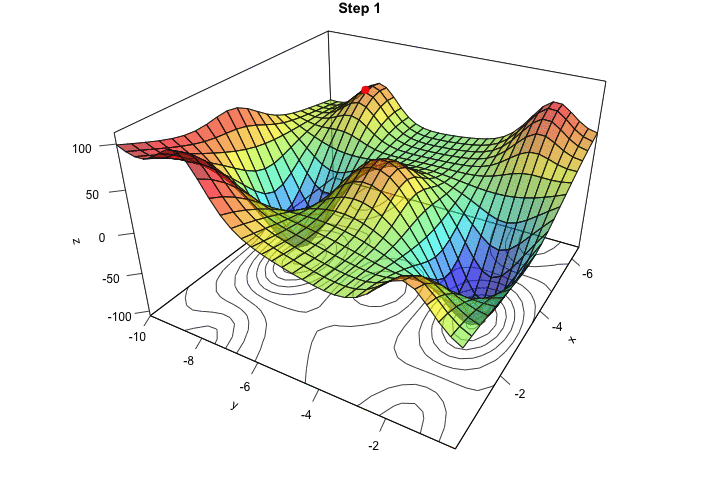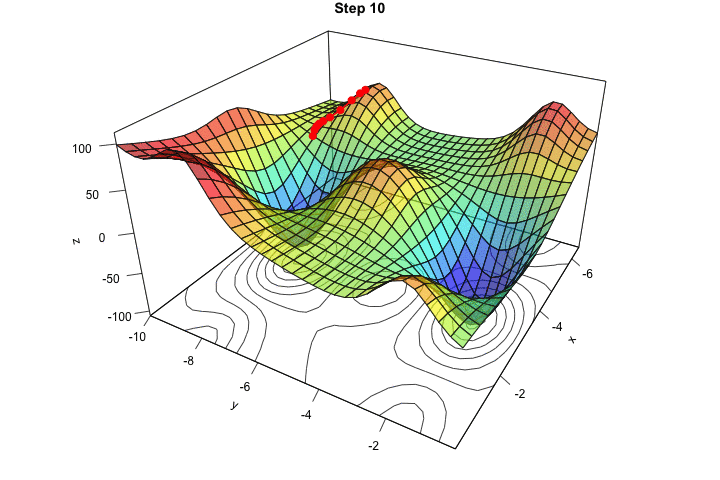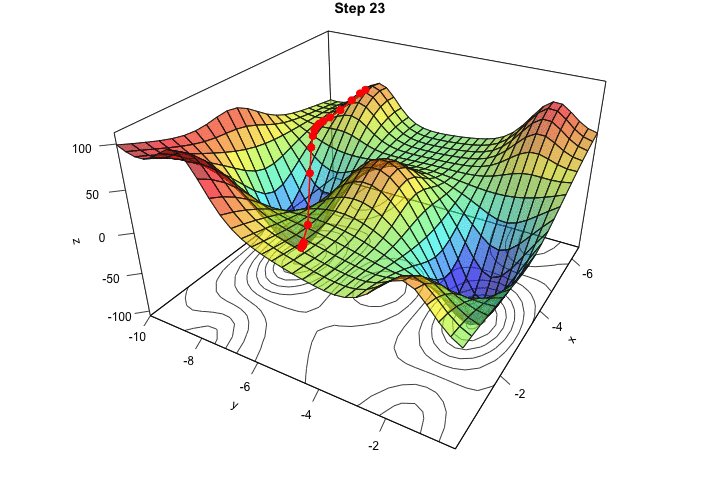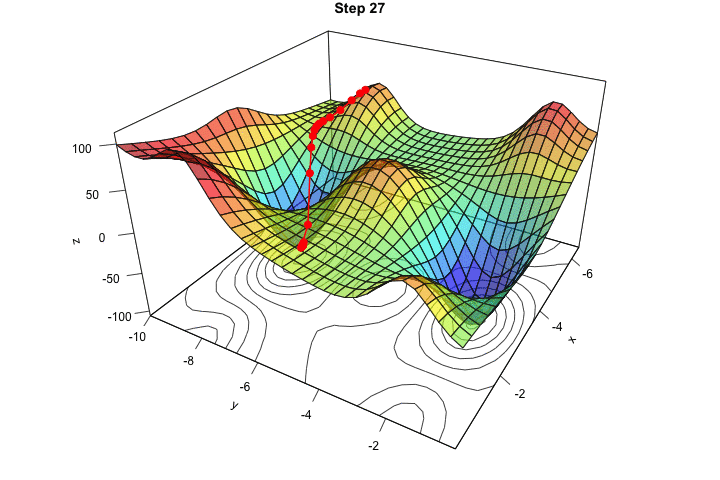
در شکل زیر هم در یک انیمیشن میتوانید ببینید که کاهش گرادیان چگونه در یک فضای ۲ بُعدی (با ۲ متغیر) کار میکند:

- ۱ » شبکه عصبی (Neural Network) چیست؟
- ۲ » تعریف پرسپترون (Perceptron) در شبکه های عصبی
- ۳ » پرسپترون در شبکه عصبی چگونه یاد میگیرد؟
- ۴ » پرسپترون چند لایه (Multi Layer Perceptron) چیست؟
- ۵ » درباره توابع فعال سازی پرسپترون و Sigmoid
- ۶ » تابع ضرر (Loss Function) در شبکه عصبی چیست و چه کاربردی دارد؟
- ۷ » نحوه یادگیری پس انتشار خطا (Back Propagation) در شبکه های عصبی
- ۸ » کاهش گرادیان (Gradient Descent) در شبکه های عصبی
- ۹ » حل یک مثال عددی یادگیری ماشین با شبکههای عصبی
با سلام
لطفا دوره را کامل نمایید چون بسیار عالی است
با سلام
آموزش بسیار ساده و روان بود. بسیار متشکرم. با توجه به اینکه بسیاری از الگوریتم های مهم در زمینه یادگیری ماشین و داده کاوی در سایر منابع بسیار پیچیده توضیح داده شده اند، خواهش می کنم درباره آنها هم توضیح دهید. از جمله مواردی که شخصا با آن مشکل دارم، تجزیه تنسور است که از تابع کاهش گرادیان نیز استفاده می کند
سلام.
من بتازگی آموزش این الگوریتم رو شروع کردم و توضیحات شما بسیار در درک این موضوع به من کمک کرد.
بسیار ممنون میشم اگر با یک دیتاست و کدهای پایتون با کمک Keras این الگوریتم رو بیشتر تشریح کنید تا بطور عملی هم این موضوع بیان بشه.
ممنونم و امیدوام پرقدرت ادامه بدید.
عالی احسنت
اینقد درگیر جمله ها شدم و تشنه فهمیدن گام بعد اثلا نفهمیدم من از دیروز دارم تابع و صفر مشتق،تکرار مثال ها کمینه هاش،واقعان تبریک به این قدرت تکلم ،بازاریاب
هرمزی ،از هرمزگان ☝👏👏👏👏🙏
سلام جناب کاویانی
بی نهایت ممنون بابت آموزش های خوبت
سلام خیلی ممنون بابت سادگی بیان و شیوه تدریستون، خیلی آموزنده بود. خدا خیرتون بده
سلام
بیان عالی،ساده، روان و گیرایی دارید.
ان شاء الله همواره موفق و پیروز باشید.
با سلام
بسیار زیبا و ظریف و با بیانی ساده مفهوم را بیان میکنید
که بسیار ارزشمند است
خیلی عالی ، واقعا به تمام سوالای توی ذهنم جواب داده شد..
باتشکر از زحمات شما
خیلی خیلی… عالی بود….مطالب بسیار ساده و قابل فهم بیان شده ،از صمیم قلبم آرزوی موفقیت روزافزون براتون دارم
واقعا عالی و ساده
بسیار عالی بود تشکر
واقعا عالی هستین
سلام
ممنون از زحمتتون
خیلی روون توضیح داده شده. عاااااالی بود!!!
عالی بود تشکر فراوان
سلام،واقعا عالی درس دادین من مطالب زیادی در رابطه با شبکه عصبی و طبقه بندی خوندم اما به این خوبی نتونسته بودم یاد بگیرم،ممنون که پولکی نیستین و علمتون و به رایگان در اختیار دیگران میزارید،واقعا انگار ادم سر کلاس نشسته اینقدر که خوب توضیح دادین
واقعا عالی بود. خیلی واضح و دقیق و قابل فهم توضیح دادین. مشتاقانه منتظر مطالب بعدیتون هستیم.
واقعا قابل تحسین و تشکر بود…
خیلی خیلی عالی بود به نظر من شما نوشته هاتون رو به صورت کتاب در بیاورید و ان را معرفی کنید که پول زحماتتون رو هم بدست بیارید
اولین مشتریشم من
واقعا برام مهم بود در این حوضه چیزی یاد بگیرم اما هر سایتی رفتم خیلی پیچیده توضیح میداد
شما خیلی روون با مثال های ساده بیس کار رو یاد دادید
در اخر هم بگم ممنون از زحماتتون ممنون از اینکه این مطالبو رایگان در اختیار ما گذاشتید و اینکه حتما ادامه بدید
خیلی عالیه من هر مطلبی تو شبکه عصبی متوجه نمیشم میام و از سایت شما یادش میگیریم..امیدوارم همیشه موفق باشید و مرسی از زحماتتون