

برای شناخت دقیقتر دادهها، روشهای مختلفی وجود دارد که برخی از آنها را (مانند میانگین، مد، واریانس و…) در جلسات گذشته مورد بحث قرار دادیم. در این جلسه میخواهیم به یکی دیگر از روشهای موثر و کاربردی جهت تحلیل و شناخت بهتر دادهها بپردازیم. این روش، چارک نام دارد و یکی از روشهای متداول در تحلیل و شناخت دادههاست.
چارک یا همان quartile دادهها را به چهار قسمت تقسیم میکند به گونهای که هر قسمت ۲۵درصد (یک چهارم) دادهها را در خود داشته باشد. فرض کنید دادههای زیر، امتیازاتی باشد که کاربران مختلف به یک راننده در تاکسی اینترنتی (بین صفر تا بیست) دادهاند:
۶ – ۳ – ۲ – ۶ – ۳ – ۷ – ۱۵ – ۳ – ۹ – ۱۰ – ۱۸
برای اینکه این دادهها را چارکبندی کنیم، ابتدا آنها را به ترتیب از کوچک به بزرگ مرتب کرده و دادهها به به بخشهای ۲۵ درصدی تقسیم میکنیم. چیزی مانند شکل زیر:
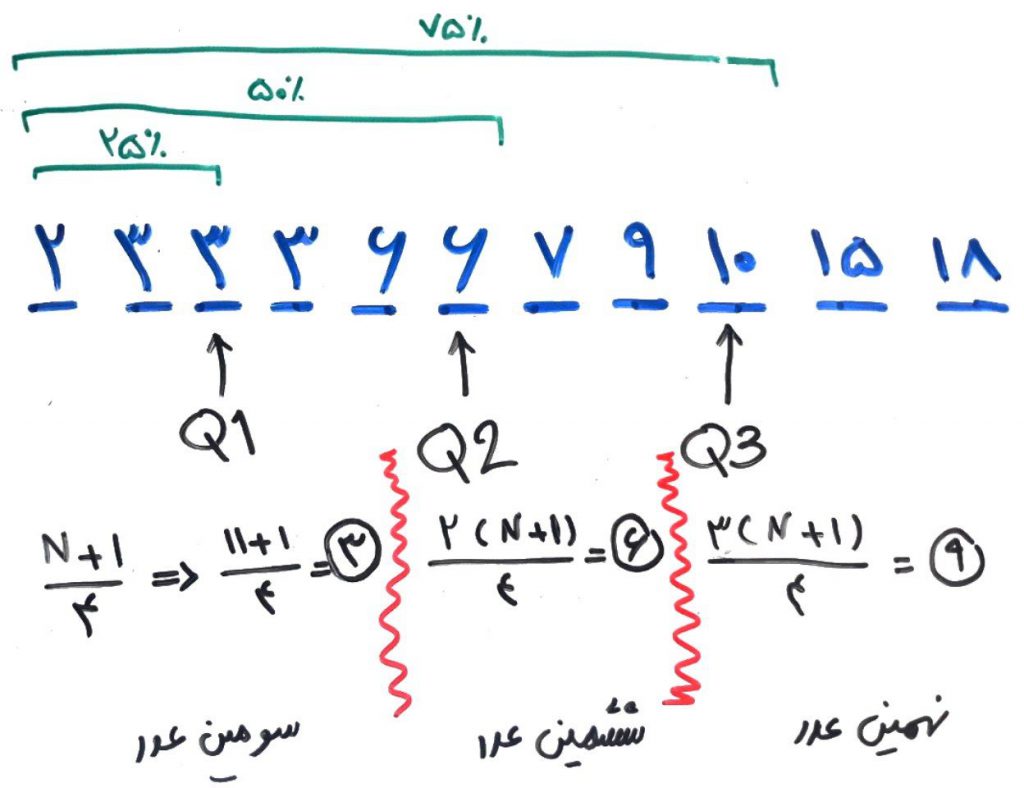
فرمول ساده است. دادهها را به علاوهی یک کرده و سپس تقسیم بر چهار میکنیم تا به چارک اول برسیم. مثلاً در این مثال ۱۱ + ۱ برابر ۱۲ میشود و سپس ۱۲ را تقسیم بر ۴ میکنیم که به عدد ۳ میرسیم. پس باید دادهها سه تا سه تا تقسیم شود.
در کل سه چارک داریم، Q1، Q2 و Q3. چارک اول یا همان Q1، عددی است که ۲۵ درصد دادهها کمتر از آن هستند و ۷۵ درصد دادهها بیشتر از آن هستند. Q2 که چارک دوم است، میانهی (median) دادهها را نشان میدهد. میانه که در دروس قبلی به آن اشاره کردیم همان عددی است که ۵۰ درصد دادهها کمتر از آن هستند و ۵۰ درصد دادهها بیشتر از آن. Q3 هم که همانطور که حدس میزنید، دادهای است که ۷۵ درصد دادهها کمتر از آن و ۲۵ درصد دادهها بیشتر از آن هستند.
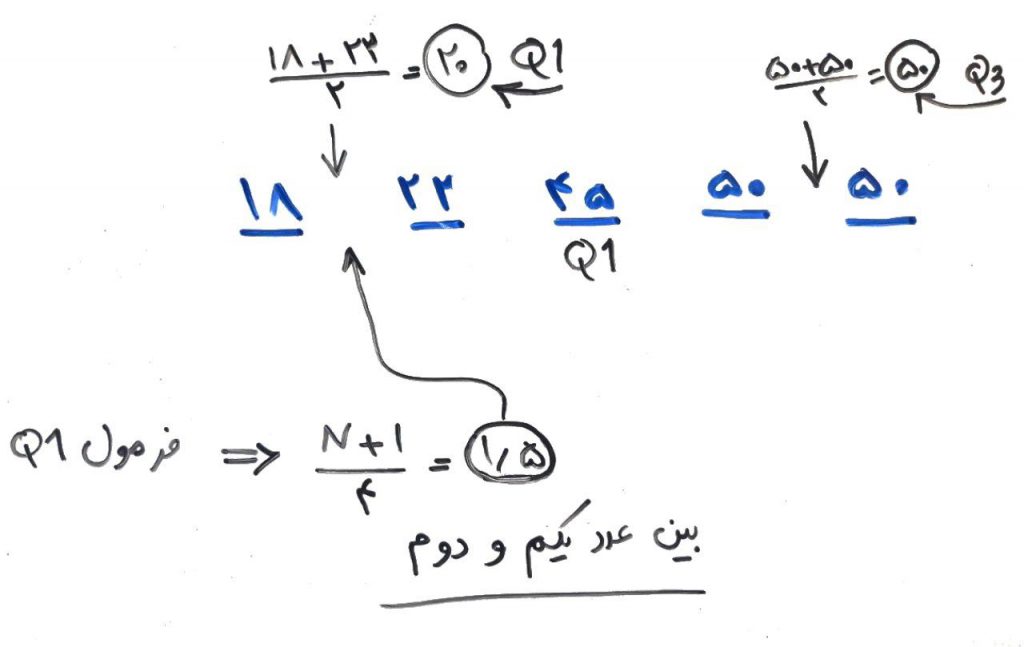
البته نکته اینجاست که اگر دادهها به صورتی باشند که با استفاده از فرمولِ N+1)/4) به عدد صحیح نرسند، بایستی میانگین آن دو عددی که به آن میرسیم را به عنوان چارکها انتخاب کنیم. برای مثال شکل زیر را نگاه کنید که در آن چارک اول عددی بین ۱۸ و ۲۲ شده است که بایستی میانگین ۱۸ و ۲۲ را محاسبه کرده و آن را به عنوان چارک اول (Q1) در نظر گرفت:
چارکها به شما اجازه میدهد که بتوانید با استفاده از چند عدد، به سادگی دادهها را شناسایی کنید. مثلا با استفاده از کمینه، چارک اول، میانه، چارک سوم و بیشینه در یک نگاه میتوان به توزیع و شکل دادهها به صورت تخمینی و حدودی دست پیدا کرد. یعنی به جای اینکه کل دادهها را یکی یکی بررسی کنیم میتوانیم دادهها به صورت خلاصه با این پنج عدد مشخص کنیم.
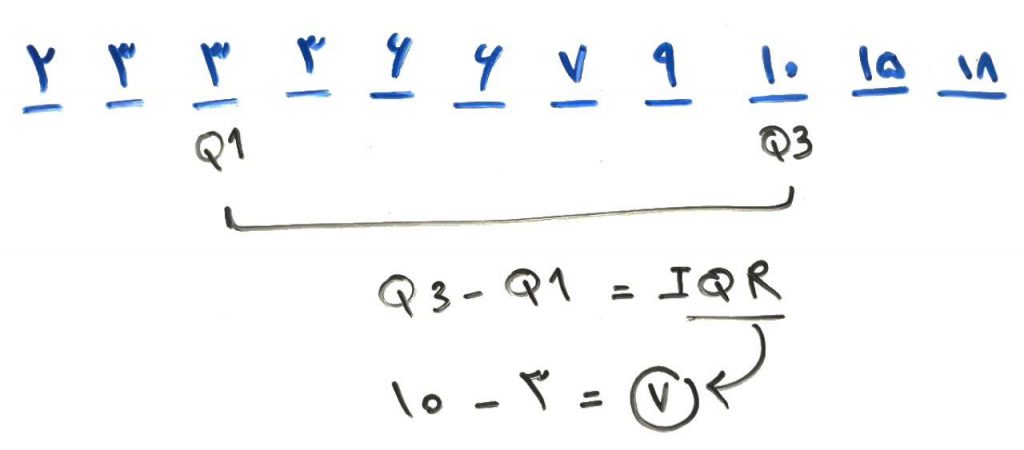
در اینجا تعریفی دیگر هم داریم. IQR (Interquartile Range) یا همان فاصلهی بین چارکی، به فاصلهی بین چارک اول و سوم میگویند. IQR به نوعی پراکندگی دادهها را بدون نویز (دادههای پرت) نشان میدهد. برای مثال در شکل اول همین درس، IQR برابر ۷ میشود. مانند شکل زیر:
در بسیار از موارد، برای تحلیل پراکندگی دادهها میتوانیم از IQR استفاده کنیم. IQR دادههای پرت را حذف میکند و به نوعی پراکندگی را به صورت واقعبینانه (بدون در نظر گرفتن اتفاقاتی که ممکن است باعث ایجاد آن دادهی پرت شده باشند)، بررسی میکند. مثلاً وقتی میخواهید بدانید که مسافران به یک رانندهی تاکسیِ اینترنتی در چه بازهای امتیاز دادهاند، IQR میتواند گزینهی مناسبی باشد چون دادههای پرت (مثلاً یکی از مسافران که به دلیل خاصی نمرهی خیلی پایینتر یا بالاتر نسبت به بقیه را به این راننده داده است)، تاثیری در محاسبهی IQR ندارند. همچنین از چارکها میتوان در تخمین توزیع و شکل و چولگی دادهها نیز استفاده کرد که در جلسات آینده با یکدیگر خواهیم دید.

- ۱ » تحلیل اکتشافی دادهها (Exploratory Data Analysis) چیست؟
- ۲ » انواع مختلف دادهها در دادهکاوی کدامند؟
- ۳ » منظور از دادههای مستطیلی (Rectangular Data) چیست؟
- ۴ » داده پرت (Outlier) در دادهکاوی چیست؟
- ۵ » تخمین مکان دادهها (Estimation Of Location) چیست و انواع مختلف آن کدامند؟
- ۶ » تخمین تنوع و پراکندگی (Estimation Of Variability) و انواع مختلف آن
- ۷ » چارک (Quartile) و IQR در دادهها و کاربردهای آن
- ۸ » چولگی (Skewness) در دادهها
- ۹ » کشیدگی یا برجستگی (kurtosis) در دادهها
- ۱۰ » چگونه با EDA در دادهها اکتشاف کنیم؟
- ۱۱ » نمونهگیری آماری و محاسبهی حداقل تعداد نمونه (Min Sample Size)
- ۱۲ » توزیعهای آماری (Statistical Distributions)
- ۱۳ » فاصلهی آماری (Statistical Distance) و کاربردهای آن
- ۱۴ » واگرایی کولبک-لیبلر (Kullback-Leibler Divergence) و کاربرد آن در فاصلهی آماری
- ۱۵ » فاصلهی جنسون-شنون (Jenson-Shannon) برای مقایسهی توزیعهای آماری
عالی هست مطالبتون.
در مثال دوم، عدد ۴۵ به اشتباه Q1 نوشته شده که فکر میکنم چارک دوم یعنی Q2 باید نوشته میشد.
سلام و وقت بخیر
این فرمولی که گفتین برای بدست آوردن چارک ها به نظر کاملا درست و منطقی میاد و درست داده ها رو به ۲۵ و ۵۰ و۷۵ درصدشون تقسیم میکنه منظورم فرمول q1 = (n+1)/4 q2 = 2 * (n+1)/4 , q3 = 3 * (n+1) /4
ولی برای مثال همان دیتا ستی که بالا تو عکس اول گفتید رو در نظر بگیریم : s = [2,3,3,3,6,6,7,9,10,15,18]
و با دستور زیر چارک ها ش رو محاسبه کنیم به جواب های متفاوتی نسبت به محاسبه با فرمول بالا میرسیم :
import numpy as np
q1 = np.percentile(s, 25)
q2 = np.percentile(s, 50)
q3 = np.percentile(s, 75)
# Printing the quartiles
print(“Q1 (25th percentile):”, q1)
print(“Q2 (50th percentile):”, q2)
print(“Q3 (75th percentile):”, q3)
به نظر این دستور برای محاسبه چارکها از ین فرمول استفاده کرده :
q1 = بیشینه n/4
q2 = بیشینه n/2
q3 = بیشینه n * 2/3
لطفا راهنماییم کنید با تشکر
چه خوب توضیح دادین
ممنونم