

یک بچه بیشتر به دنبال کنجکاوی و جستجو است و یک آدمِ مسن و پیر، بیشتر به دنبالِ استفاده از تجربیات گذشتهی خود هست. الگوریتمِ شبیهسازی تبرید نیز دقیقاً از همین روند استفاده میکند و با این کار به دنبالِ یافتن حالت بهینه در مسئله میگردد. الگوریتم وقتی شروع میکند بچه است و بیشتر جستجو میکند، سپس آرام آرام مسنتر میشود و کمتر تجربهی جدید کرده و بیشتر به تجربههای قبلیِ خود پابند است.
در دروس اولیهی دورهی جاری با حالت بهینه (Optimal) و بهینههای سراسری و محلی آشنا شدید و مشاهده کردید که الگوریتمهای فراابتکاری، به دنبال پیدا کردن بهینهترین حالتِ ممکن در زمان معقول هستند.
الگوریتمهای فراابتکاری میخواهند بدون جستجوی زیاد و امتحان کردنِ تمامیِ حالاتِ یک مسئله، بتوانند بهترین حالت یا چیزی نزدیک به آن را پیدا کنند. مانندِ یک انسان که به دنبال یک شغلِ خوب برای کسبِ درآمد است و طبیعتاً نمیتواند تمامیِ شغلها را در مدت زمانِ محدودِ عمر خود آزمایش کند. پس با استفاده از سعی و خطا و جستجو و استفاده از تجربهی خود یا دیگران، به دنبال پیدا کردنِ شغلِ خوب و مناسب در زمان کم است. قطعاً هیچ انسانی نمیتواند ادعا کند بهترین شغل را پیدا کرده است ولی به هر حال هر شخص با توجه به وضعیت مالی و شادابیِ حاصل از شغل میتواند بفهمد که این شغل، شغلی به نسبت مناسب هست یا خیر؟
الگوریتم شبیه سازی تبرید یا همان Simulated Annealing یا به اختصار SA نیز یک الگوریتمِ فراابتکاری است که از یک پدیدهی طبیعی الهام گرفته شده است. در علمِ مواد، برای تبریدِ یک فلز به منظورِ تغییر در حالتِ آن به صورت پایدار، آن فلز را در یک حمامِ حرارتی قرار میدهند و آن را تا دمای ذوب حرارت داده، سپس آرام آرام دمای حمام را کم میکنند. با این کار، ذراتِ موجود در فلز به کمترین (یا نزدیک به کمترین) انرژی خود رسیده و پایدار میشوند. در واقع حالت داخلیِ فلزات با این کار عوض شده و این حالتِ جدید پایدار میماند.
حال اجازه بدهید به شبیهسازی تبرید که الگوریتم الهام گرفته شده است تبرید مواد است بپردازیم. درسِ بهینهی محلی و بهینهی سراسری را خوانده بودید. در آن درس یاد گرفتیم که الگوریتم میخواهد به یکی از بهینهها برسد، که ترجیحاً بهینهی سراسری است ولی اگر نشد حداقل به یک بهینهی محلیِ خوب دست پیدا کند پس در واقع الگوریتمِ شبیه سازی تبرید نیز میخواهد همین کار را انجام دهد. شکل زیر را نگاه کنید:
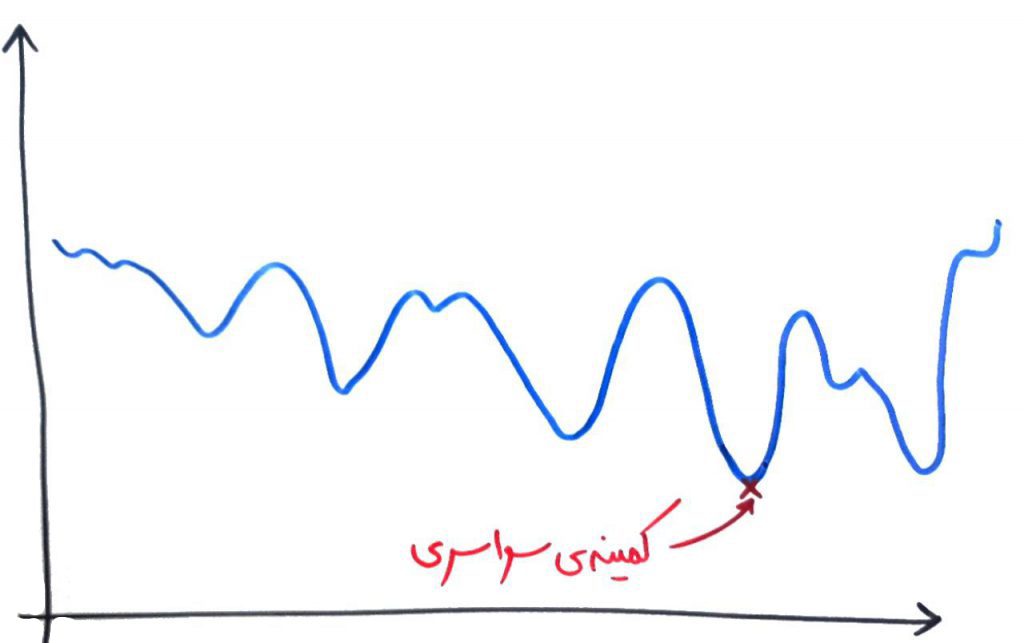
فرض کنید اینبار میخواهیم یک کمینهی بهینه را پیدا کنیم یعنی در شکلِ بالا به دنبال پیدا کردنِ عمیقتر دره هستیم. الگوریتمِ شبیهسازی تبرید، ابتدا یک نقطهی تصادفی را پیدا میکند. مانند نقطهی سبز رنگ در شکل زیر:

بعد از انتخابِ این نقطهی اولیه، یک نقطه در همسایگی آن نقطه پیدا میکند. اگر همسایهی جدید، بهتر (در این مثال عمیقتر) از نقطهی فعلی بود، بدون هیچ شرطی نقطهی جدید را قبول کرده و جایگزین نقطهی فعلی میکند (توجه کنید که هر نقطه یک راهحل است که بر اساس تابع برازش – Fitness Function در نمودار ارزشگذاری میشود). مثلاً در شکل زیر چند بار نقطهی جدید به صورت تصادفی در همسایگی آن نقطه پیدا شده است که بهتر از نقطهی قبلی بوده، پس بدونُ هیچ شرطی نقطهی جدید قبول و جایگزین نقطهی (راه حل) قبلی میشود:

همانطور که میبینید الان، الگوریتم، یک راه حلی را پیدا کرده است که در میان همسایههای خود بهترین است، ولی با توجه به کل فضای حالت، حالتِ خوبی نیست. در واقع الگوریتمِ شبیه سازیِ تبرید نیاز دارد تا از این بهینهی محلی فرار کند تا بتواند به یک بهینهی محلی دیگر برسد. در شکلِ بالا مشخص است که برای فرار از این بهینهی محلی، الگوریتم بایستی کمی هم بدتر شدنِ شرایط را تحمل کند. حالا الگوریتم یک نقطهی دیگر را در همسایگیِ خود انتخاب میکند، چیزی مانند شکل زیر:
در شکلِ بالا مشخص است که این نقطهی جدید از نقطهی فعلی بدتر است. الگوریتمِ شبیهسازی تبرید در این حالت (حالتی که همسایهی پیدا شده از حالتِ فعلی بدتر باشد)، با یک احتمالِ مشخص (یعنی غیر قطعی) این بدتر شدن را میپذیرد تا بلکه بتواند از این بهینهی محلی فرار کند. این احتمال با فرمول زیر محاسبه میشود و به آن فاکتور احتمالی بولتزمن (Boltzman Probability Factor) میگویند:
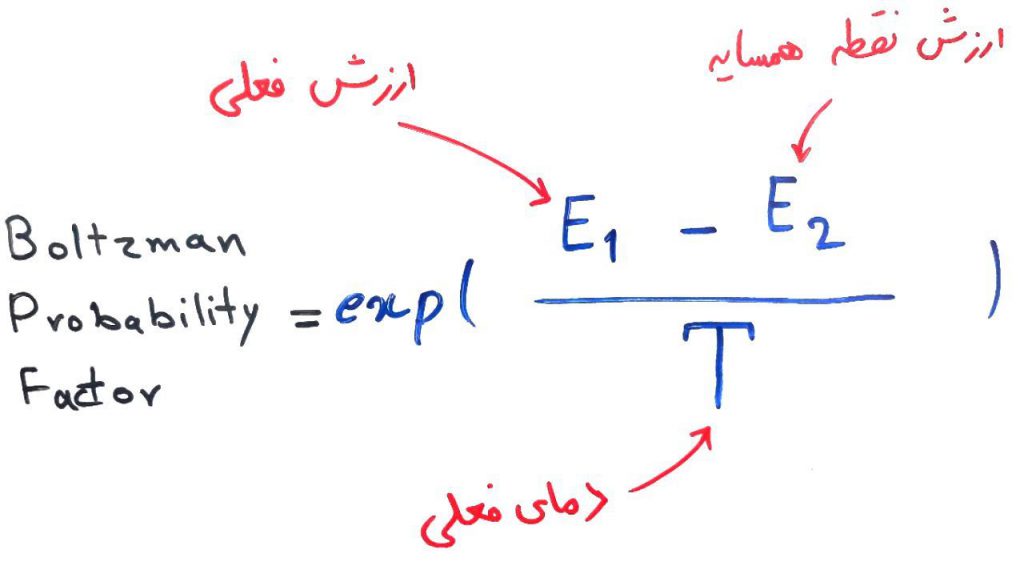
اگر با تابع exp آشنایی ندارید این مقاله از ویکیپدیا میتواند کمک کننده باشد. گفتیم که دما در هر مرحله کمتر میشود. فرمولِ بالا نشان میدهد در دماهای بالا (یعنی وقتی الگوریتم در شروع کار است و هنوز راهحلهای مختلفی را جستجو نکرده است) احتمالِ انتخابِ حالتِ بدتر، بالاتر میرود. از طرفی هم هر چه، اختلافِ نقطهی جدیدِ پیدا شده با نقطهی فعلی کمتر باشد، باز هم احتمالِ قبول کردن این حالتِ بدتر بالاتر میرود. پس هر چه در مراحلِ الگوریتم جلوتر میرویم، احتمالِ اینکه الگوریتم، بدتر شدنِ شرایط را قبول کند، کمتر میشود. مانند یک انسان که در سنین کودکی و نوجوانی آمادهی یادگیری است و چیزهای زیادی را بر خلاف میل خود امتحان میکند، ولی هنگامی که سن او بالاتر رفت، کمتر حاضر به پذیرش چیزهای جدید بر خلافِ تجربهی خود میشود.
در نهایت الگوریتمِ شبیهسازیِ تبرید ممکن است مانند شکل زیر به یک نقطهی بهینهی خوب دست پیدا کند. مشاهده میکنید که الگوریتم چند بار توانست از بهینههای محلیِ نامناسب (با کمک تابع احتمالی) فرار کند:
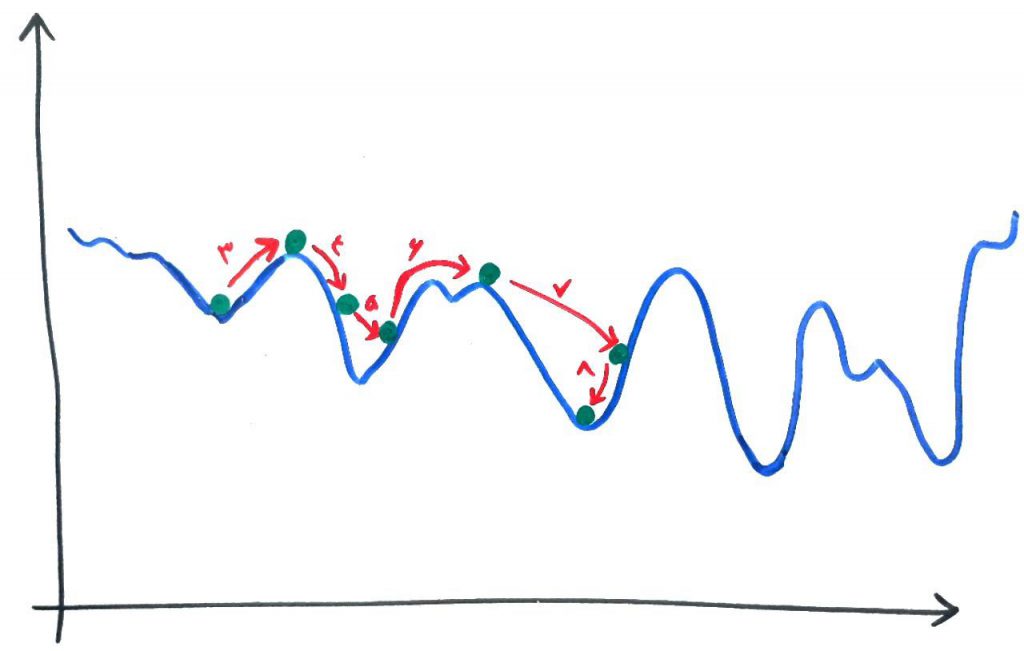
اگر بخواهیم جمعبندی انجام دهیم، الگوریتمِ شبیهسازی تبرید (Simulate Annealing) به صورت زیر کار میکند:
۱. در ابتدا یک دمای اولیه و یک راه حل اولیه تولید میکند
۲. مراحل ۳ تا ۵ را تاهنگامی که پارامترِ دما تا حد کافی کم شد (سرد شد) تکرار میکند:
۳. یک تغییر کم در راهحل فعلی میدهد تا به یک حالتِ دیگر که در همسایگی این حالت هست برسد
۴. اگر حالت جدید بهتر بود که قبول میکند و اگر بهتر نبود با توجه به فاکتور احتمالیِ بولتزمن (Boltman) تصمیم میگیرد این حالتِ جدید را قبول کند یا خیر
۵. در نهایت کمی پارامترِ دما را کاهش میدهد و دوباره از مرحلهی ۳ شروع میکند
این الگوریتمی است که به الگوریتم متروپولیس (Metropolis) معروف شده است.
شاید در مراحل بالا، واژهی پیدا کردن یک راهحل همسایه کمی گیج کننده باشد. اجازه بدهید با یک مثالِ پایانی، بحث پیدا کردن همسایه را بهتر یاد بگیریم. فرض کنید میخواهید از شهر اصفهان به شهر تهران بروید. مسیرهای متعددی را پیشروی خود دارید که میتوانید هر بار از هر کدام از آنها حرکت کنید. ابتدا از یک مسیر مانندِ شکل زیر حرکت میکنید:
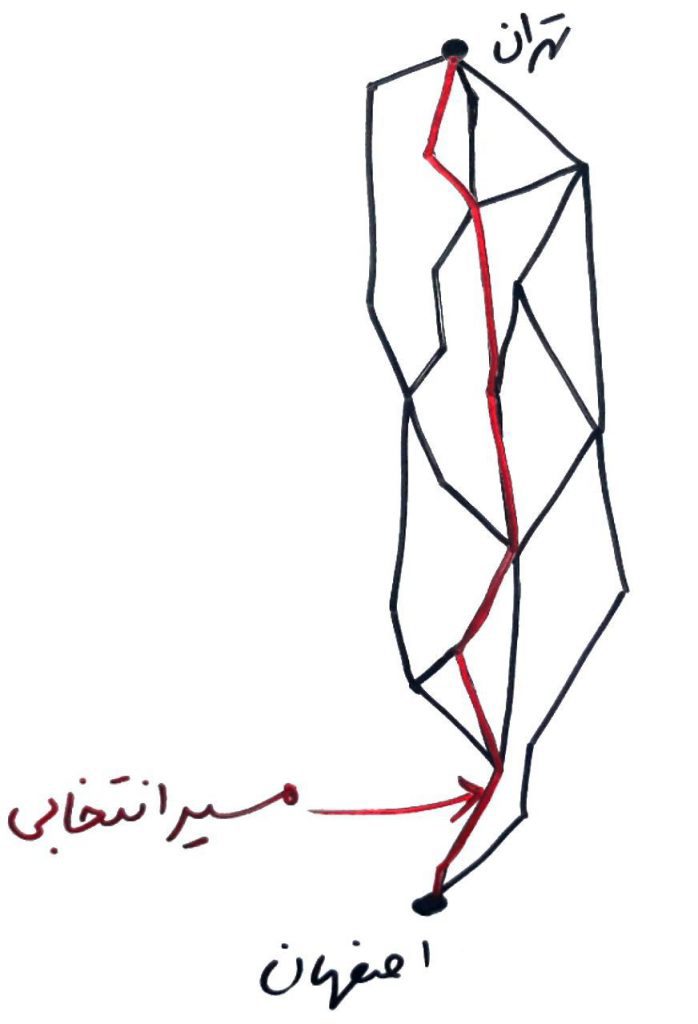
دفعهی بعد، میخواهید یک همسایگی از این مسیرِ فعلی پیدا کنید، بایستی همانمسیر قبلی را با یک تغییر کوچک بروید. مثلاً چیز مانند شکل زیر:
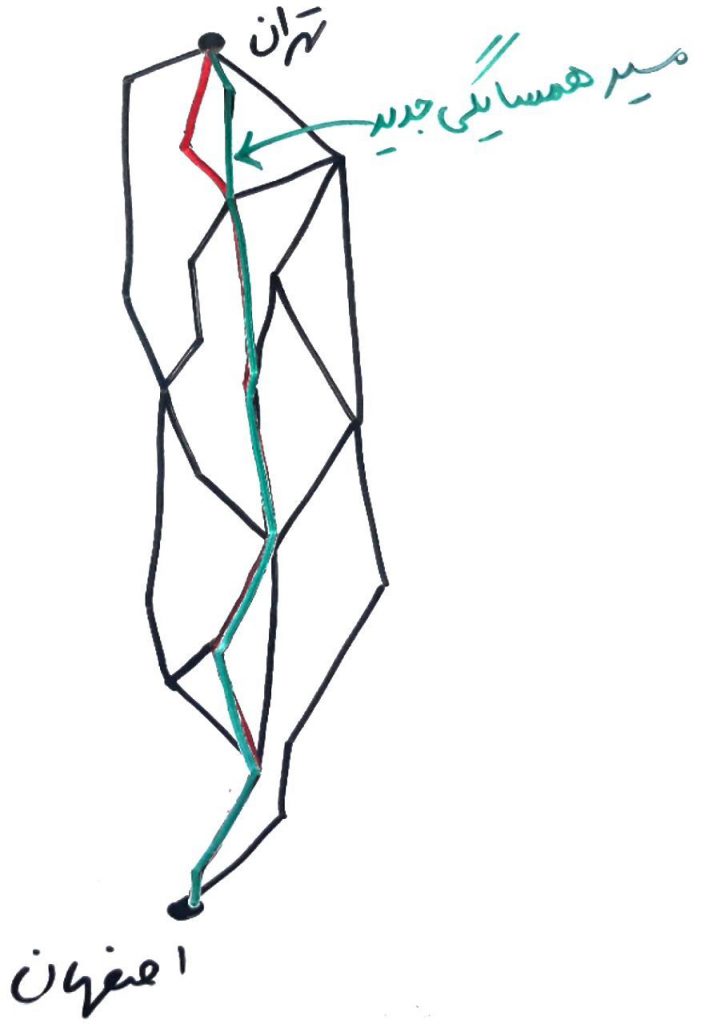
همانطور که مشاهده کردید، ما تقریباً از همان مسیرِ قبلی رفتیم و فقط یک قسمتِ کوچک را تغییر دادیم. منظور از همسایگی در الگوریتمِ شبیهسازی تبرید هم همین است. با این کار دیگر نمیخواهد کلِ مسئله را دوباره بسازید. فقط کافیست یک تغییر کوچک در قسمتی از مسئلهی بهینهسازی انجام دهید.

- ۱ » الگوریتم فراابتکاری (Meta Heuristic) و تفاوت آن با الگوریتمهای عادی
- ۲ » منظور از بهینه محلی (Local Optimum) و بهینه سراسری (Global Optimum) چیست؟
- ۳ » الگوریتمهای فراابتکاری (Meta Heuristic)، تابع برازش (Fitness Function) و چند مثال
- ۴ » ابعاد (Dimension) مسئله و فضای حالت در الگوریتمهای بهینهسازی
- ۵ » الگوریتم ژنتیک (Genetic)
- ۶ » شبیه سازی تبرید (Simulated Annealing) و الگوریتم متروپولیس
- ۷ » الگوریتم جستجوی ممنوعه (Tabu Search)
- ۸ » الگوریتم بهینهسازی کلونی مورچگان (Ant Colony Optimization)
- ۹ » جستجوی محلی (Local Search) و الگوریتم تپهنوردی (Hill Climbing)
- ۱۰ » الگوریتم ممتیک (Memetic) بر اساس الگوهای رفتاری
- ۱۱ » الگوریتمهای چند شروعی (Multi Start) در مسائل بهینهسازی
- ۱۲ » بهینهسازی سراسری (Global Optimization) و تفاوت آن با کاهش گرادیان (Gradient Descent)
- ۱۳ » جستجوی محلی تکراری (Iterated Local Search) در بهینهسازی
مرسی خیلی خوب بود
ممنون عالي بود همين كه با شكل توضيح داده بوديد خيلي جالب و شهودي بود
واقعا عالی بود به خصوص که با نمونه عملی توضیح دادید
بسیار عالی و قابل فهم بود
دست شما درد نکند ، خیلی خوب و مفهومی داده اید ، شما خیلی به درد معلمی می خورید اگر همین الان نباشید !
ممنون از سایت بروز و تخصصی در زمینه دیتا ساینس. پیشنهاد میکنم برای الگوریتم هایی که بخصوص فرا ابتکاری هستند یک مثال کد نویسی شده مثلا با جاوا یا پایتون از مسائل واقعی بیارید تا درک الگوریتم ها بهتر بشن
ممنون
ممنون عالی
عالی توضیح دادین ممنون که به انتشار علم کمک میکنید
ممنون خیلی روان توضیح دادید