

اگر درسهای دورهی جاری (الگوریتمهای فراابتکاری) را خوانده باشید، متوجه شدهاید که این الگوریتمها به دنبال پیدا کردن راه حل در یک زمان معقول هستند. یعنی به جای اینکه تمامی مسئله را جستجو کنند، به دنبال جستجو در قسمتهایی از مسئله میگردند تا بتوانند به یک بهینهی سراسری یا یک بهینهی محلیِ خوب دست پیدا کنند. در درسِ بهینهی سراسری و بهینهی محلی، گفتیم که هدفِ الگوریتم فرار کردن از بهینهی محلی و رسیدن به بهینهی سراسری یا چیزی نزدیک به آن است. در همین راستا در این درس میخواهیم یکی دیگر از الگوریتمهای فراابتکاری به نام جستجوی ممنوعه یا همان Tabu Search را با یکدیگر مرور کنیم.
الگوریتمِ جستجوی ممنوعه یک ایدهی اصلی دارد. این الگوریتم یک لیست از حرکات یا نقاطِ ممنوعه درست میکند تا در جستجوهای بعدی، دیگر آن حرکات را انجام ندهد. با این کار این الگوریتم امید دارد که از بهینهی محلی خارج شده و بتواند به سمت بهینهی سراسری حرکت کند.
برای درک بهتر، فرض کنید شما یک فروشندهی موبایل هستید که میخواهید حداکثرِ سود را از فروش موبایل انجام دهید. برای اینکار بایستی راههای مختلفِ فروش را امتحان کنید. اجازه بدهید مسئله را ساده کنیم. شما به عنوان فروشنده با خود قرار میگذارید تا اگر یک شخص جوان به سراغ مغازهی شما آمد، موبایل با یکی از رنگها را به او پیشنهاد دهید. حال فرض کنید یک شخص جوان به فروشگاهِ شما وارد شد. شما موبایل با رنگ قرمز را به او پیشنهاد میدهید. با این کار پیشنهادِ موبایل با رنگ قرمز در لیست ممنوعه (Tabu list) قرار میگیرد و شما تا یک زمان مشخص (مثلاً تا ۳مشتریِ دیگر) به هیچ شخصی موبایل قرمز پیشنهاد نمیدهید، چون پیشنهاد موبایل قرمز از حالا به بعد در لیستِ ممنوعه قرار دارد. این کار باعث میشود که شما پیشنهادِ رنگهای دیگر را نیز به مشتریان امتحان کنید. با این کار شما میتوانید رنگهای مختلف را به مشتریانِ متفاوت پیشنهاد بدهید و در واقع از یک بهینهی محلی خارج شوید و راههای دیگر کسبِ درآمد را امتحان کنید (ایدهی اصلی در الگوریتمهای فراابتکاری همین است). البته این کار یک نکته دارد. فرض کنید پیشنهادِ رنگ قرمز همچنان در لیست ممنوعه باشد (یعنی نباید به مشتریِ بعدی رنگ قرمز را پیشنهاد دهید) ولی یک مشتری با کیفِ قرمز و ماشینِ قرمز و ساعتِ قرمز رنگ وارد مغازه میشود. شما میدانید که بر اساس تکنیکهای فروش، بایستی موبایل با رنگ قرمز را به او پیشنهاد بدهید و با این کار احتمالِ خریدِ او بالاتر میرود. پس با وجود اینکه رنگِ قرمز در لیست ممنوعه قرار دارد، به خاطرِ احتمالِ خریدِ بسیار بالاتر، شما قانونِ لیستِ ممنوعه را نقض میکنید و موبایل با رنگ قرمز را به او پیشنهاد میدهید. به این شرایط در اصطلاح در الگوریتم جستجوی ممنوعه، شرایط تنفس (Aspiration Criterion) میگویند، یعنی شرایطی که به خاطرِ خوب بودنِ زیاد، شما قانونِ لیست ممنوعه را نقض میکنید.
از مثال بالا متوجه شدید که جستجوی ممنوعه، دو عنصر اصلی دارد. لیست ممنوعه (Tabu List) و شرایط تنفس (Aspiration Criterion) که تحقیقات نشانداده است با استفاده از این دو قاعدهی ساده، میتواند به نتایج خوبی دست پیدا کند.
حالا اجازه بدهید، با یک مثالِ دیگر بحث را بیشتر جا بیندازیم. فرض کنید یک پردازنده (CPU) میخواهد یک سری وظیفه (Task) را به ترتیب انجام دهد. این سری وظایف در کنارِ هم، یک زمانبند (Scheduler) را میسازند. هر کدام از ترتیبهای این وظایف با سرعتهای مختلفی انجام میشوند و ترتیبِ آنها در سرعتِ اجرا تاثیرگذار است. برای مثال اگر وظیفهی شماره ۱ بعد از وظیفهی شماره ۳ انجام شود، سرعتِ اجرای آن زمانبند بهتر میشود. در نهایت CPU میخواهد بداند که کدام ترتیبِ وظایف (یعنی کدام زمانبند) با سرعت بیشتری اجرا میشود. شکل زیر را نگاه کنید:
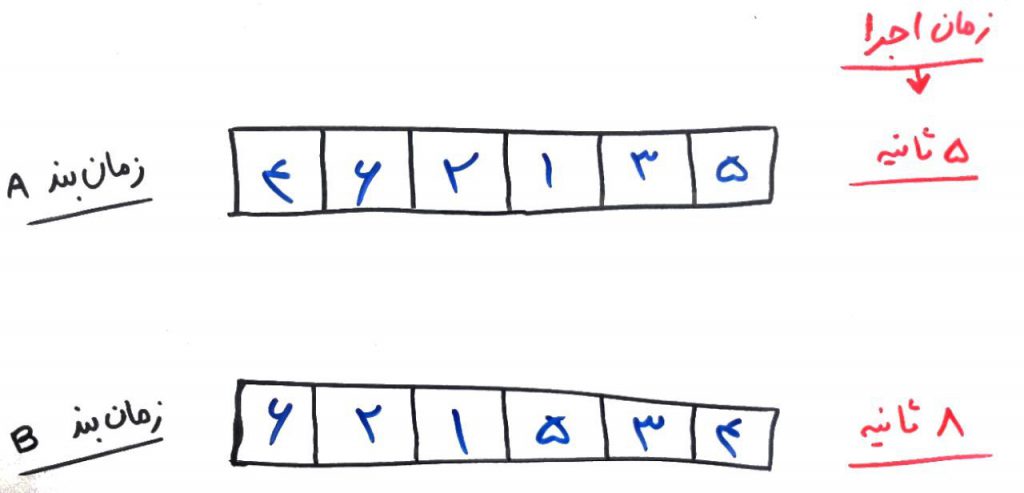
وظایف با شمارههای ۱ تا ۶ نامگذاری شدهاند. هر کدام از خانهها یک وظیفه (Task) است و وظیفههایی که سمت چپتر آمدهاند، زودتر انجام میشوند. برای مثال در جدول A، ابتدا وظیفهی ۴ و بعد وظیفهی ۶ و سپس وظیفهی ۲ و به همین ترتیب تا آخر انجام شده است. هر کدام از این زمانبندیها، باعثِ تغییر در سرعت اجرای مجموعهی وظایف میشود. در شکلِ بالا، زمانبندی مطابق با جدولِ A، در زمان ۵ ثانیه انجام شد و زمانبندی مطابق با جدولِ B در زمان ۸ ثانیه. مسلم است که زمانبندیِ A بهتر از زمانبندیِ B است (زمانبندیِ A بهینهتر است).
در مثالِ بالا، میخواهیم یک زمانبندیِ بهینه (یا نزدیک به بهینه) را در زمانی معقول پیدا کنیم. برای اینکار بایستی تمامیِ حالات و جابهجاییها را انجام داده و سرعتِ هر کدام را اندازه بگیریم. اگر بخواهیم تمامیِ حالات را جستجو کنیم بایستی تمامیِ جایگشتها را برای این ۶ وظیفه پیدا کنیم. یعنی نیاز به !۶ (۶ فاکتوریل) حالت یعنی ۷۲۰ بار محاسبه داریم. فرض کنید CPU برای هر بار محاسبهی زمان، نیاز به ۱ ثانیه زمان داشته باشد. پس بایستی ۷۲۰ ثانیه برای به دست آوردنِ بهترین حالت صبر کند (تا تمامیِ جایگشتها را ایجاد کرده و هر سرعتِ هر کدام را تست کند). در حالیکه در بسیاری از کاربردها (مثلاً برای Queryهای پایگاه داده) این زمان بسیار زیاد است. پس بایستی الگوریتمی توسعه داده شود که بدون جستجو در تمامیِ حالات، بتواند با یک سری جستجوی محدود و یک سری حالاتِ محدود، جواب بهینه (یا نزدیک به بهینه) برسد. این همانکاری است که الگوریتمهای فراابتکاری برای حلِ مسئله انجام میدهند.
حالا میخواهیم مسئلهی زمانبندیِ ۶ وظیفهای را با الگوریتمِ جستجوی ممنوعه (Tabu Search) حل کنیم. ابتدا یک راهحل اولیه تولید میکنیم (مثلاً به صورت تصادفی وظایف را در یک زمانبند قرار میدهیم) چیزی مانند شکل زیر:
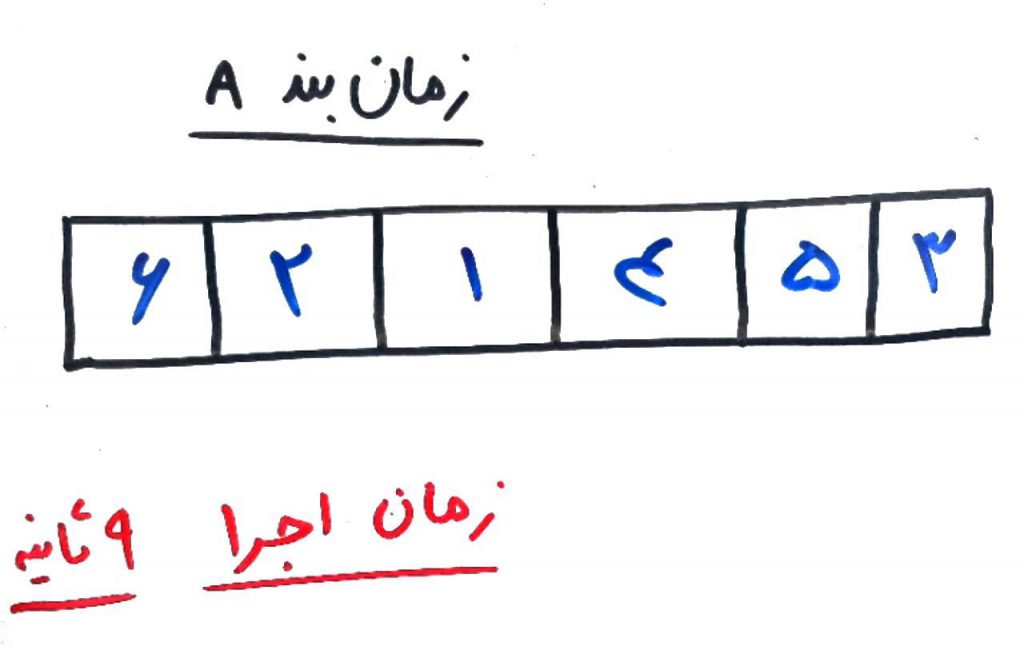
همانطور که میبینید این ترتیب زمانی از اجرای وظیفهها (Tasks) توسط CPU، به اندازهی ۹ثانیه زمان نیاز دارد. یعنی اگر وظیفهی شمارهی ۶ ابتدا انجام شود و بعد وظیفهی ۲ و بعد ۱ و بعد ۴ و ۵ و ۳، همهی این وظایف با هم به ۹ ثانیه زمان برای اجرا نیاز دارند. حال بایستی یک وضعیتِ همسایه را برای این حالت پیدا کنیم. وضعیتِ همسایه به وضعیتی که میگویند که بسیار نزدیک به وضعیتِ فعلی است. با این کار شاید دیگر نیاز نباشد که محاسبات را از اول انجام دهیم. در مثالِ فعلی برای پیدا کردنِ وضعیتهای همسایه، دو وظیفه را در زمانبندِ A با هم عوض میکنیم. به گونهای که شکل زیر حاصل شود:
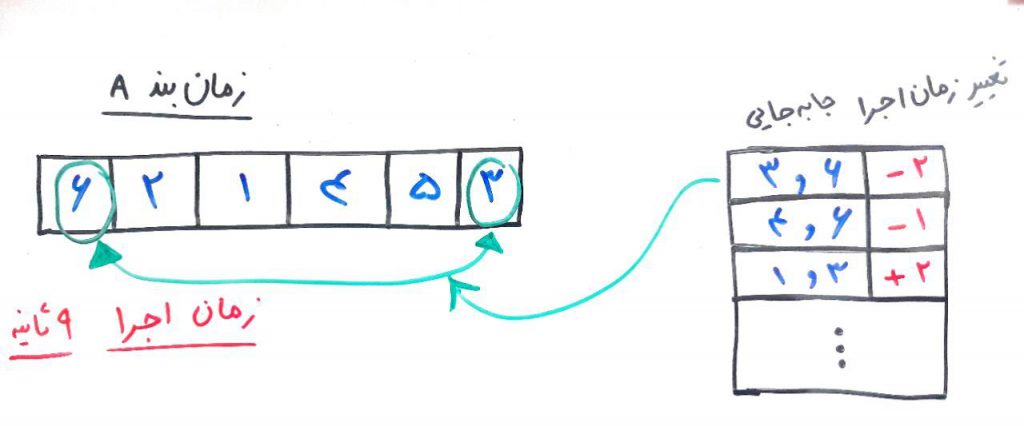
در سمتِ راست تصویر، حالاتِ مختلف را برای جابهجایی در بین ترتیب زمانی برای وظیفهها مشاهده میکنید. برای فهم بهتر، زمانبند A را در نظر بگیرید. در اینجا تمامیِ وظیفهها را با هم دو به دو جابهجا کردهایم. در واقع ۱۵جابهجایی انجام دادهایم. هر کدام از این جابهجاییها منجر به تغییر در زمانِ اجرای زمانبند A توسط CPU میشود. برای مثال با جابهجاییِ ۶ و ۳، دو ثانیه از زمان اجرا کم میشود (یعنی دو ثانیه بهبود نسبت به وضعیت فعلی حاصل میشود). با جابهجاییِ ۶ و ۴، یک ثانیه از زمانِ اجرا کم میشود و به همین ترتیب برای تمامیِ حالاتِ جابهجایی، زمانها را محاسبه میکنیم و نتایج را در جدول سمت راست رسم میکنیم. در واقع اینجا برای تمامیِ وضعیتهای همسایه، تابع برازش (که در اینجا همان زمانِ اجرای وظیفهها توسط CPU هست) را محاسبه میکنیم. در شکلِ بالا سمت راست، سه جابهجاییِ برتر را نمایش دادهایم یعنی سه جابهیی که به نسبت بهتر از بقیهی جابهجاییها هستند. در اینجا مشاهده میکنید که با جابهجاییِ وظیفهی ۶ با ۳، به یک وضعیتِ جدید (یک نقطهی جدید در فضای حالت) رسیدیم. این، بهترین جابهجایی در میان ۱۵جابهجاییِ موجود با توجه به وضعیتِ جاری بود. بعد از جابهجایی وظایفِ ۶ و ۳ زمانِ اجرا برای این زمانبند برابر ۷ثانیه شده است (که بهرین زمان تا به حال است). حال به شکل زیر نگاه کنید:
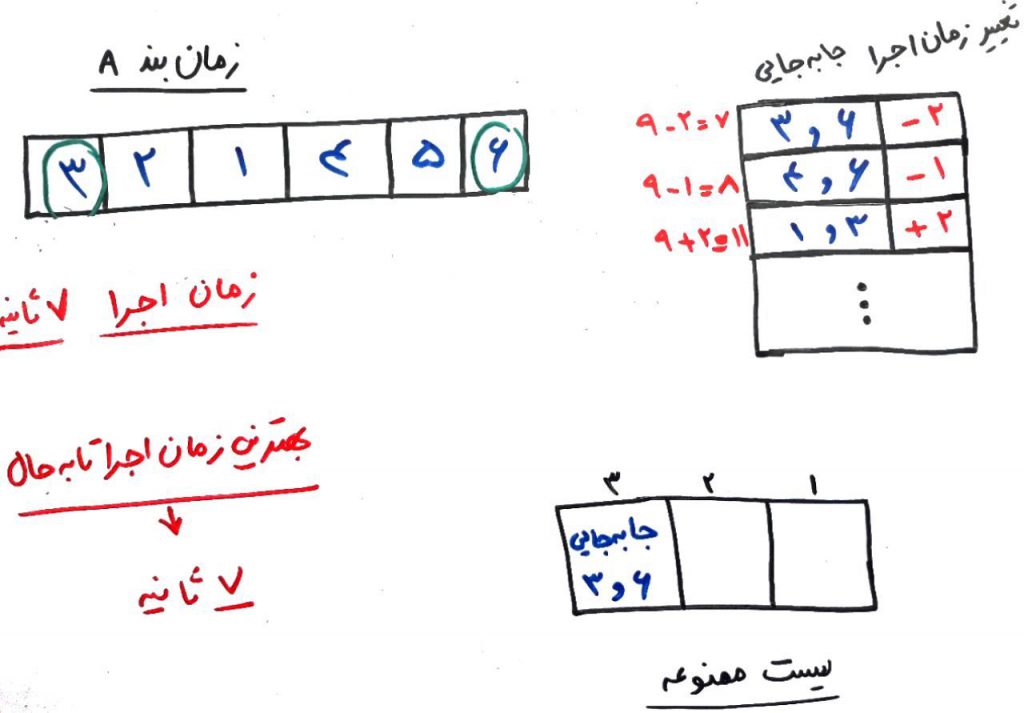
ما عددِ ۶ و ۳ را با هم جابهجا کردیم (زیرا بهترین جابهجایی بود و به کمترین زمانِ اجرا منجر میشد). مشاهده میکنید که در لیست ممنوعه (در سمت راست) این تغییر را در خانهی سومِ لیست ممنوعه ذخیره میکنیم. یعنی تا ۳ دور (iteration) دیگر، الگوریتم نمیتواند اعداد ۶ و ۳ را با هم جابهجا کند (البته مگر اینکه این جابهجایی باعث بهبودِ چشمگیری شود که به آن هم در همین مثال خواهیم رسید).
تا اینجا یک دور (یک iteration) را تمام کردیم. بهترین نتیجهی کسب شده مربوط به ترتیب وظیفهها با ۷ ثانیه زمانِ اجرا بود. حال میخواهیم دورِ بعد را شروع کنیم. توجه کنید که جابهجاییِ ۶ و ۳ در لیست ممنوعه قرار گرفت. حال به سراغ دورِ دوم میرویم. برای اینکار بایستی دوباره جابهجایی را برای تمامیِ عناصر با توجه به دورِ قبل انجام دهیم تا به چند همسایگیِ دیگر برسیم. حال این جابهجایی را برای هر کدام از عناصر انجام میدهیم و بعد از جابهجایی، سرعتِ انجام وظیفهها را در هر کدام از زمانبندیها محاسبه میکنیم. چیزی مانند شکل زیر:
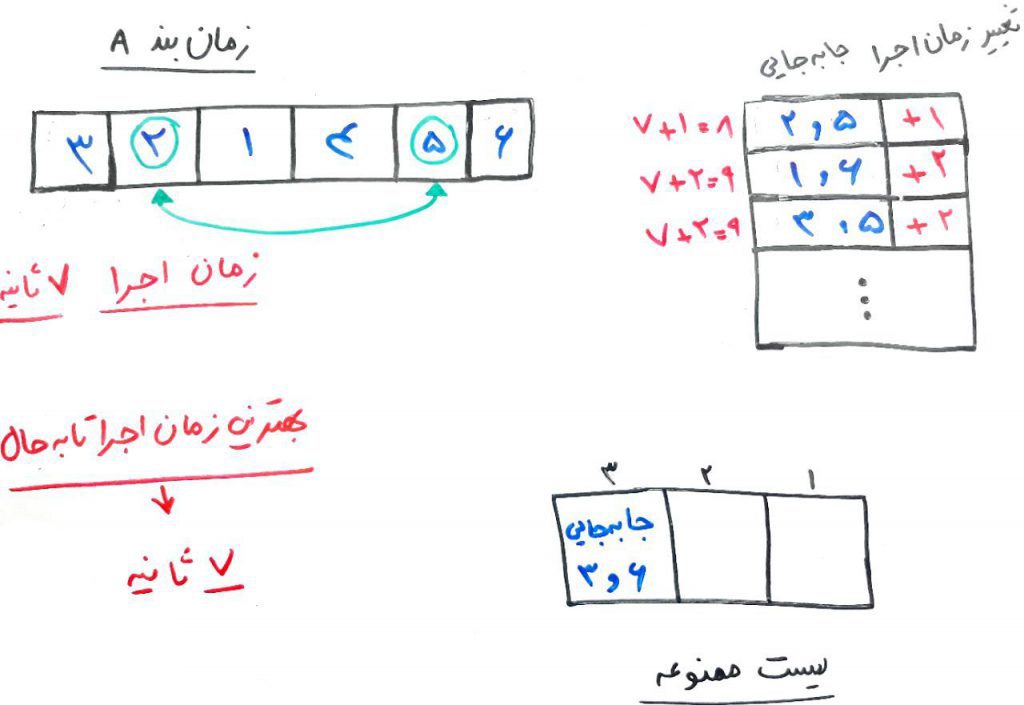
با تغییرِ وظیفههای ۵ و ۲، میتوانیم این زمانبندی را با ۸ ثانیه، یعنی ۱ ثانیه زمانِ بیشتر (بدتر) انجام دهیم. اگر بپرسید که چرا این کار را انجام میدهیم باید بگوییم که به خاطر اینکه امید داریم در آینده و با تغییراتِ بعدی، بتوانیم به زمانبندیِ بهتری دست پیدا کنیم. در واقع کمی تلخی (بدتر شدنِ اوضاع) را تحمل میکنیم تا شاید بعداً اوضاع بهتر شود. همانطور که میبینید، با جابهجاییِ وظیفههای دیگر، زمانها بهبود نیافته است و بیشتر شده است. پس همین جابهجایی وظیفهی ۵ و ۲ را با یکدیگر انجام میدهیم. پس از آن، جابهجایی ۵ و ۲ نیز به لیست ممنوعه اضافه میشوند. البته توجه کنید که جابهجایی ۶ و ۳ که قبلاً در خانهی سومِ لیست ممنوعه قرار داشت، حالا یکی به سمت راست میرود و در خانهی دوم قرار میگیرد، و جابهجاییِ ۵ و ۲ (که تازه انجام دادیم)، در خانهی سومِ لیست ممنوعه قرار میگیرد. یعنی جابهجاییِ ۶ و ۳ تا دو دورِ دیگر در لیستِ ممنوعه هست و جابهجایی ۵ و ۲ تا سه دورِ دیگر بایستی در لیست ممنوعه قرار بگیرد. چیزی مانندِ شکل زیر:
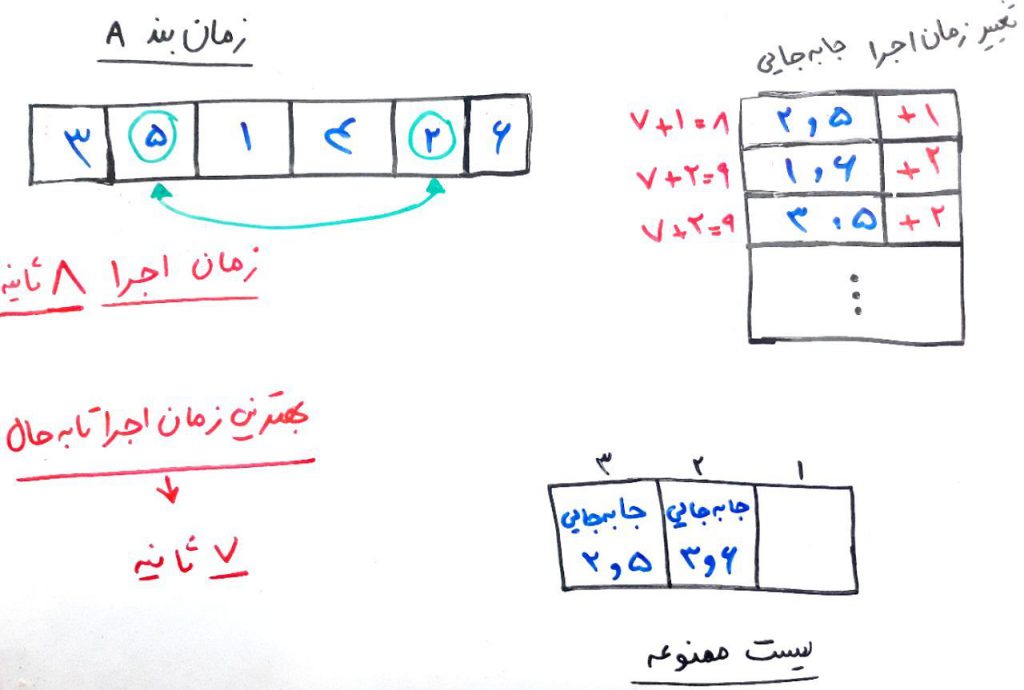
بهترین نتیجهای که تا به حال گرفته شده است زمانبندی با ۷ ثانیه بود. الان دور دوم تمام شد، حالا به سراغ دور سوم میرویم. در این دور نیز باز هم با جابهجایی دو به دو در میان وظیفهها، به ساختن همسایههای جدید از زمانبندیِ دور قبل میپردازیم. بعد از هر کدام از جابهجاییها هم، زمان اجرا را برای زمانبند اندازه میگیریم که چیزی شبیه به شکل زیر میشود:
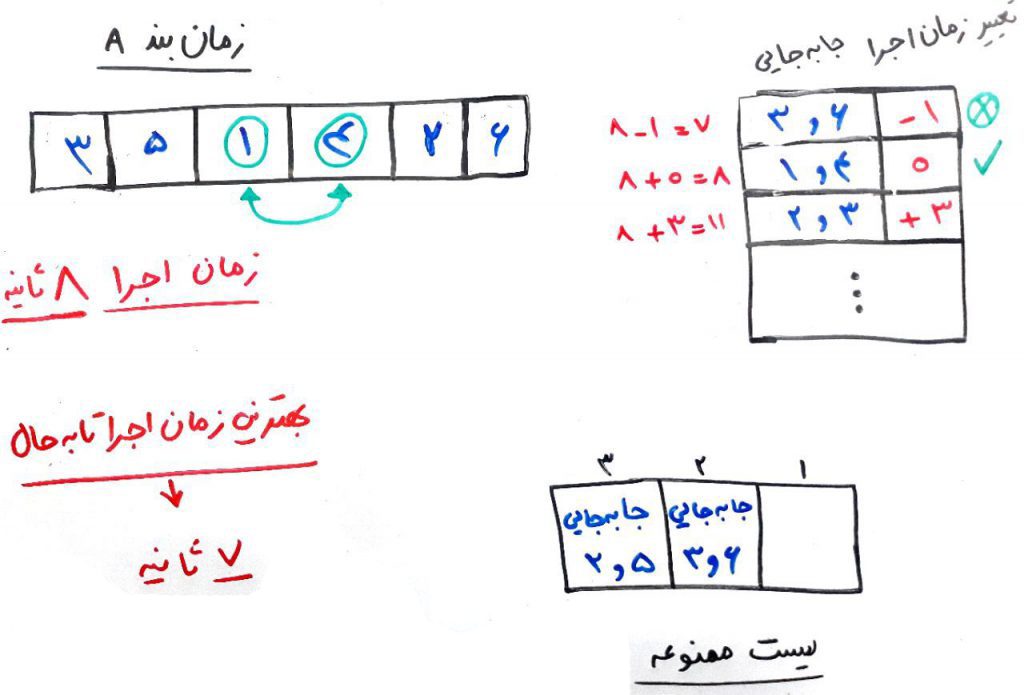
همانطور که میبینید، با تغییر ۶ و ۳، میتوانیم به ۱ ثانیه بهبود برسیم. ولی توجه کنید که جابهجایی ۶ و ۳ در لیستِ ممنوعه قرار دارند و در این دور یا دورِ بعدی، نمیتوانیم از آن استفاده کنیم. پس به جای آن به دنبال جابهجاییِ ۴ و ۱ هستیم، زیرا که بهترین حالتِ بهبود را در میان جابهجاییهای قابلِ انجام، دارند. حال این جابهجایی را انجام میدهیم و آن را به لیستِ ممنوعه اضافه کرده و لیستِ ممنوعه را آپدیت میکنیم. در اینجا فقط وظیفههای ۴ و ۱ بایکدیگر جابهجا میشوند و تغییری در زمان اجرا انجام نمیشود.
اجازه بدهید یک دورِ دیگر الگوریتم را تکرار کنیم. اینبار هم با جابهجاییِ وظیفهها به زمانبندیِ همسایه برای حالتِ قبلی میرسیم و برای هر جابهجایی، زمانِ اجرای زمانبندی (یعنی همان خروجیِ تابعِ ارزش – Fitness Function) را محاسبه میکنیم. فرض کنید چیزی مانند شکل زیر تشکیل میشود:
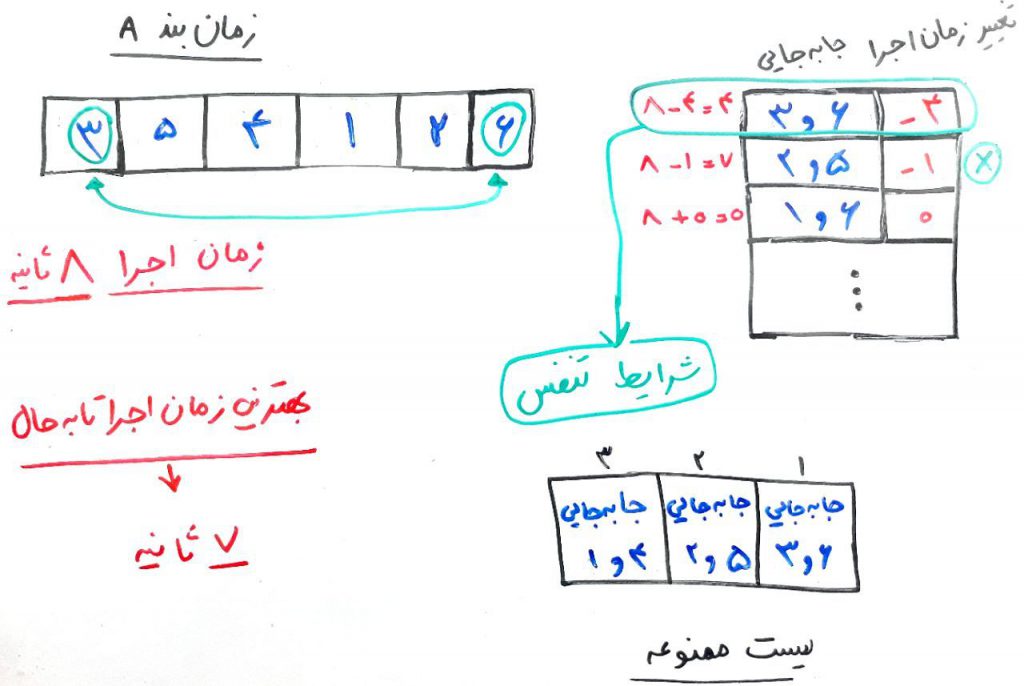
الان بهترین جابهجایی ۶ و ۳ هست، که البته در لیست ممنوعه قرار دارد. بعد از آن ۵ و ۲ هست که آنها هم در لیست ممنوعه قرار میگیرند و بعد از آن جابهجاییِ ۶ و ۱ را داریم. ولی دقت کنید که با تغییر ۶ و ۳، یک بهبودِ بسیار زیاد رخ میدهد و زمان به ۴ ثانیه کاهش مییابد. یعنی ۳ ثانیه از بهترین زمانِ کل بهتر است. اینجاست که شرط تنفس یا همان Aspiration Criteria به کار میآید. میتوان از اولِ الگوریتم این قرار را گذاشت که اگر یک جابهجایی باعث بهبودیِ بیش از ۱ واحد از بهترین زمانِ ممکن تا به حال شده بود، قانون لیست ممنوعه نادیده گرفته شود تا بتوانیم به آن بهبودِ زیاد دست پیدا کنیم. در واقع حیف است که این بهبودِ چشمگیر را به خاطرِ لیست ممنوعه از دست بدهیم. پس این جابهجایی را انجام میدهیم و شکل زیر تشکیل میشود:
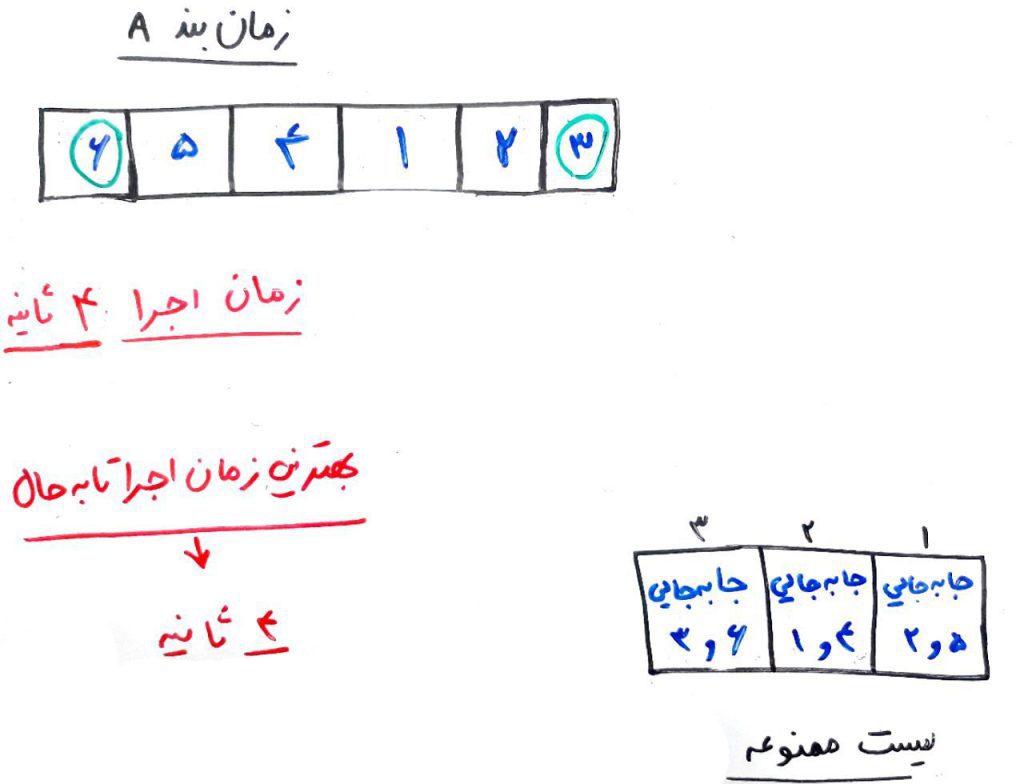
تا به حال ۴ دور را گذراندیم. میتوانیم دورها را ادامه دهیم به امید اینکه به حالتهای بهتری دست پیدا کنیم. مثلا میتوانیم بگوییم تکرار دورها را تا ۳۰ دور انجام میدهیم و بعد از آن، بهترین زمانبندی را با توجه به زمانِ اجرا انتخاب میکنیم. ولی برای این مثال تا همینجا ادامه میدهیم. مشاهده میکنید که بهترین زمانِ اجرا، مربوط به زمانبندِ دور چهارم شده است و همان را انتخاب میکنیم.
در این درس متوجه شدیم که الگوریتم جستجوی ممنوعه که یک الگوریتم فراابتکاری است، میتواند بدونِ گشتن در تمامیِ حالاتِ مسئله، با استفاده از لیست ممنوعه و شرایط تنفس، به یک بهینهی خوب دست پیدا کند.

- ۱ » الگوریتم فراابتکاری (Meta Heuristic) و تفاوت آن با الگوریتمهای عادی
- ۲ » منظور از بهینه محلی (Local Optimum) و بهینه سراسری (Global Optimum) چیست؟
- ۳ » الگوریتمهای فراابتکاری (Meta Heuristic)، تابع برازش (Fitness Function) و چند مثال
- ۴ » ابعاد (Dimension) مسئله و فضای حالت در الگوریتمهای بهینهسازی
- ۵ » الگوریتم ژنتیک (Genetic)
- ۶ » شبیه سازی تبرید (Simulated Annealing) و الگوریتم متروپولیس
- ۷ » الگوریتم جستجوی ممنوعه (Tabu Search)
- ۸ » الگوریتم بهینهسازی کلونی مورچگان (Ant Colony Optimization)
- ۹ » جستجوی محلی (Local Search) و الگوریتم تپهنوردی (Hill Climbing)
- ۱۰ » الگوریتم ممتیک (Memetic) بر اساس الگوهای رفتاری
- ۱۱ » الگوریتمهای چند شروعی (Multi Start) در مسائل بهینهسازی
- ۱۲ » بهینهسازی سراسری (Global Optimization) و تفاوت آن با کاهش گرادیان (Gradient Descent)
- ۱۳ » جستجوی محلی تکراری (Iterated Local Search) در بهینهسازی
با سلام . یعنی بسیار عالی الگوریتم توضیح دادین . من فردا دفاع دارم .این الگوریتم کمی برای من گنگ بوده ولی خیلی روان توضیح دادین . مگه میشه مگه داریم. خیلی ممنونم . عالی عالی …
بسیار عالی. ساده و روان.
متشکر
باعرض سلام و خسته نباشید…ممنون از توضیحات عالی و خوبتون
سلام مرسی که هستید
عالی.عالی.عالی
سلام
ممنون واقعا روان بود
یه انتقاد کوچیک اینکه اگر چنتا منبع انگلیسی که حالا تویه توضیحاتتون یا مثالتون ازشون استفاد کردید رو ذکر کنید واقعا خیلیییی عالی تر میشه
سلام و درود ها
بسیار عالی توضیح دادین، برقرار باشید
واقعا نمیدونم دیگه چی بگم من چندین بار این مطالب را در مقالات و سایر سایتها خونده بودم ولی هیچی نمیفهمیدم خدا رو شکر که تصادفی با این سایت و توضیحات بسیار روان و عالی جناب دکتر کاویانی عزیز آشنا شدم. برقرار باشید