

از آنجایی که امکان دارد برخی از دانشجویان کمی در درک مفاهیمِ بهینهسازی و کارایی آنها دچار سردرگمی شده باشند، در این درس میخواهیم کمی به این مباحث بپردازیم تا مدل ذهنی دانشجویان عزیز کمی بهتر با مفاهیم اصلی و بنیادین این حوزه آشنا شود.
درس کاهش گرادیان از دورهی شبکهی عصبی را به یاد بیاورید. اگر آن درس را نخواندهاید حتماً یک مرتبه آن را مطالعه کنید. در کاهش گرادیان تطابق بسیار زیادی با درس ابعاد و فضای حالت از دورهی جاری دارد. اجازه بدهید جهت یادآوری تصویر زیر را از درس کاهش گرادیان بیاوریم:
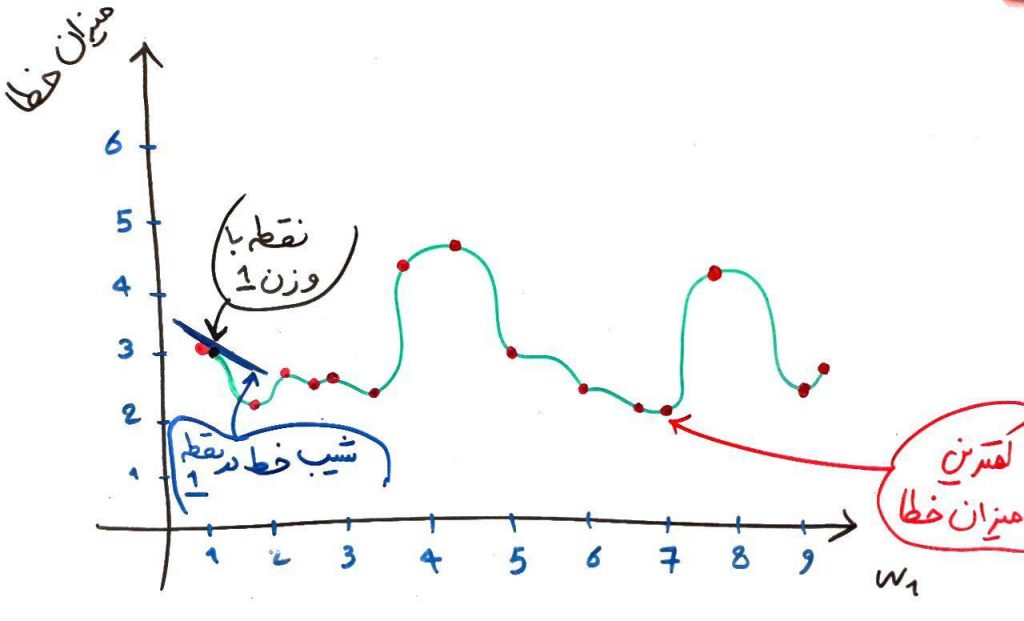
در این تصویر ما به دنبال کم کردن خطا بودیم. در واقع میخواستیم به یک کمترین خطا دست پیدا کنیم. برای اینکار بایستی یا تمامیِ نقاط را میگشتیم و یا با استفاده از عملیات کاهش گرادیان (کاهش مشتق) یک کمینهی محلی را پیدا میکردیم. نشان دادیم که الگوریتمِ کاهش گرادیان در نهایت به یک بهینهی محلی (نقطهی ۱/۷۵) میرسد در حالی که بهینهی سراسری در نقطهی ۷ قرار دارد.
پس نکتهی اصلی در بحث بهینهسازی اینجاست که ما به دنبال بهینهی سراسری هستیم، نه صرفاً یک بهینهی محلی. در واقع الگوریتمهای بهینهسازی فراابتکاری، قادر هستند از بهینهی محلی فرار کنند و به نقاط دیگر از فضای حالت رفته و شانس خود را برای پیدا کردن بهینهی سراسری امتحان کنند.
الگوریتمهای بهینهسازی سراسری یا همان Global Optimizer الگوریتمهایی هستند که میتوانند فضای حالت را به خوبی اکتشاف کرده و در تلهی بهینههای محلی کمتر گرفتار شوند. پس یکی از ویژگیهایی که این الگوریتمها باید داشته باشند، اکتشاف (Exploration) بیشتر در فضای حالت است.

- ۱ » الگوریتم فراابتکاری (Meta Heuristic) و تفاوت آن با الگوریتمهای عادی
- ۲ » منظور از بهینه محلی (Local Optimum) و بهینه سراسری (Global Optimum) چیست؟
- ۳ » الگوریتمهای فراابتکاری (Meta Heuristic)، تابع برازش (Fitness Function) و چند مثال
- ۴ » ابعاد (Dimension) مسئله و فضای حالت در الگوریتمهای بهینهسازی
- ۵ » الگوریتم ژنتیک (Genetic)
- ۶ » شبیه سازی تبرید (Simulated Annealing) و الگوریتم متروپولیس
- ۷ » الگوریتم جستجوی ممنوعه (Tabu Search)
- ۸ » الگوریتم بهینهسازی کلونی مورچگان (Ant Colony Optimization)
- ۹ » جستجوی محلی (Local Search) و الگوریتم تپهنوردی (Hill Climbing)
- ۱۰ » الگوریتم ممتیک (Memetic) بر اساس الگوهای رفتاری
- ۱۱ » الگوریتمهای چند شروعی (Multi Start) در مسائل بهینهسازی
- ۱۲ » بهینهسازی سراسری (Global Optimization) و تفاوت آن با کاهش گرادیان (Gradient Descent)
- ۱۳ » جستجوی محلی تکراری (Iterated Local Search) در بهینهسازی