

شاید در ابتدا عبارتِ Gaussian Mixture Model خیلی ساده و راحت به نظر نرسد. نمیخواهم شما را ناامید کنم، ولی همین طور هم هست! اما در این درس، میخواهیم تکههای این پازل را با همدیگر یاد گرفته و با به هم چسبداندنِ تکههای این پازل، بتوانیم الگوریتمِ خوشهبندیِ Gaussian Mixture Model یا همان GMM را درک کنیم. این الگوریتم خودْ از روشِ بیشینه سازی انتظار (Expectation Maximization) یا همان EM استفاده میکند که در این درس، به این الگوریتم نیز خواهیم پرداخت.
ترجمهی الگوریتمِ GMM را میتوان مدلِ ترکیبیِ گوسی دانست. برای درک این الگوریتم ابتدا اجازه بدهید ببینیم منظور از گوسی (Gussian) چیست؟
فرض کنید در یک کلاس هستید که تعدادِ ۴۰ نفر دانشجو دارد. میخواهید قد این افراد را اندازه بگیرید و بر روی نموداری مانند نمودار زیر رسم کنید (به این نمودار، نمودارِ توزیعِ قد دانشجویان یا نمودار هیستوگرام میگویند):
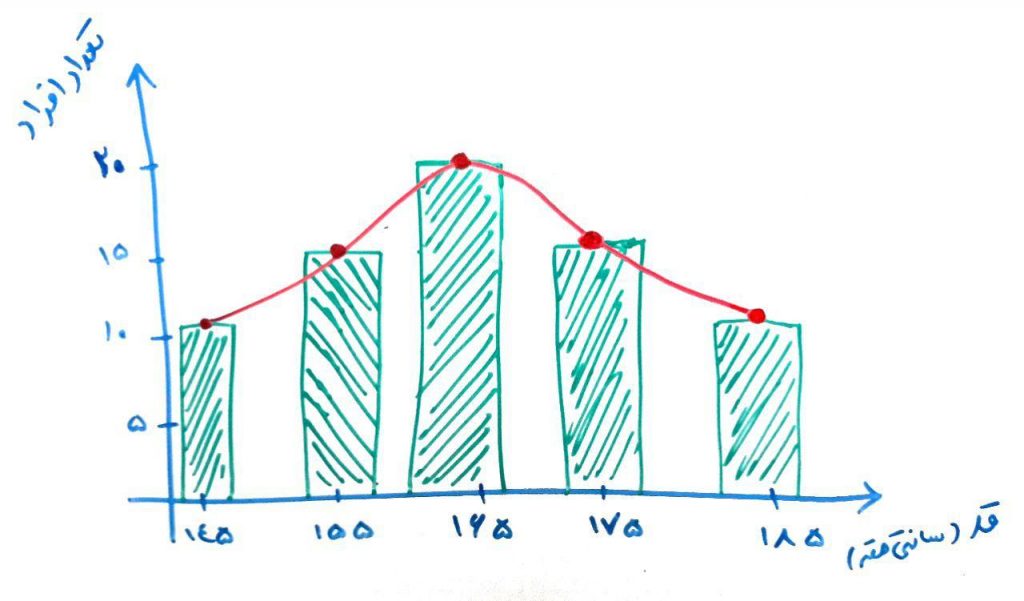
در شکل بالا، یک متغیر داریم، یعنی متغیر قد. هر چقدر تعداد افراد با یک قدِ مشخص بیشتر باشد، ستونِ مربوطه طویلتر است. همانطور که میبینید در شکل بالا تعدادِ ۲۰نفر وجود دارند که قد آنها ۱۶۵سانتیمتر است. تعداد ۱۵ نفر وجود دارند که قدر آن ها ۱۷۵سانتیمتر است و همینطور تعداد ۱۵نفر وجود دارند که قدر آن ها ۱۵۵سانتیمتر و به همین ترتیب برای بقیهی قدها است. همانطور که مشاهده میکنید، یک مقدارِ مشخص (مثلا ۱۶۵سانتیمتر) وجود دارد که تعدادِ زیادی از افراد در این ردهی قدی قرار دارند و هر چه قدر قدها بالاتر یا پایینتر می رود، تعدادِ افرادْ کمتر میشود. به این نمودار، نمودار گوسی میگویند. یعنی یک مقدار وجود دارد که حداکثرِ نمونهها در آن قرار دارند (در اینجا مقدار ۱۶۵) و هر چقدر از این مقدار دورتر میشویم، تعدادِ نمونهها کمتر میشود. به این نوع پخش شدگی نیز، توزیع گوسی میگویند. جالب است بدانید که بسیاری از دادههای جهان از این توزیع پیروی میکنند. البته قرار نیست که همیشه، مانندِ شکل بالا توزیعِ گوسیْ متوازن باشد. یعنی ممکن است یه سمتِ چپ یا راست چولگی (Skew) پیدا کند.
اگر درس «ویژگی در دادهکاوی» را خوانده باشید، میدانید که فضای ما میتواند با توجه به ویژگیهای مسئله بسیار زیاد باشد (مثلا ۱۰۰۰متغیر یا همان ویژگی داشته باشیم)
حال تصویر زیر را نگاه کنید:
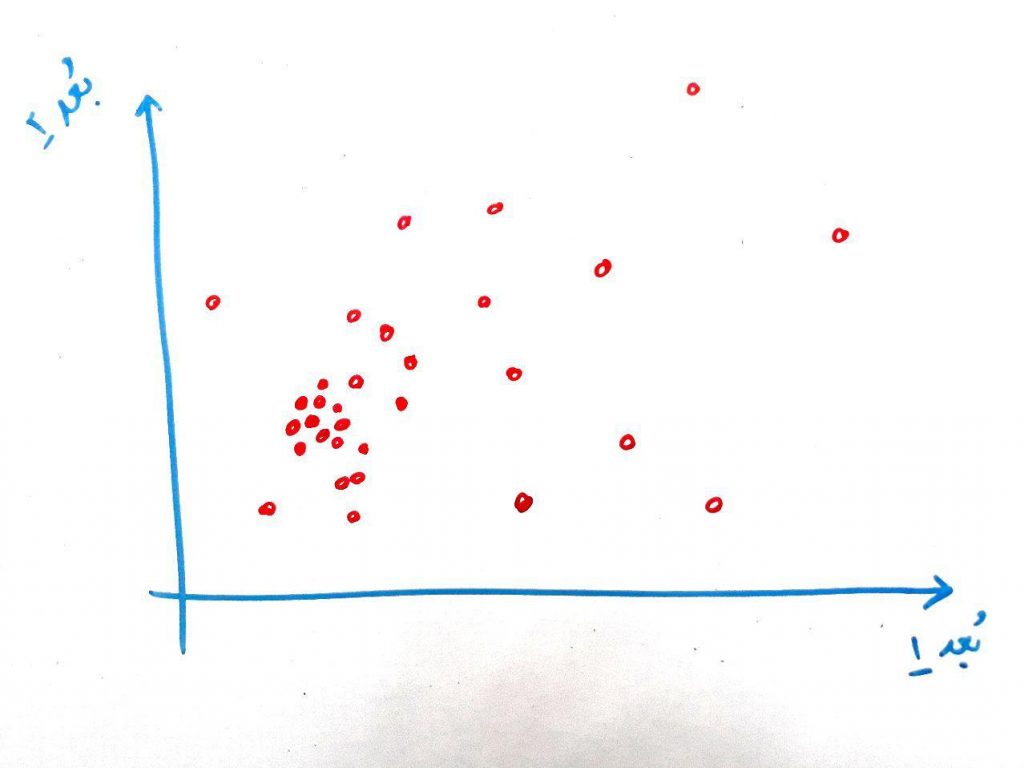
در این تصویر یک منطقه داریم که در این منطقه (که دو بُعدی هست – یعنی دارای دو متغیر هستیم) توزیع گوسی وجود دارد. یعنی غلظت در جایی زیاد است و هر چه از آن منطقه دورتر شویم غلظت (و تعداد نمونههای نزدیک به آن نیز) کمتر میشود. اگر بخواهیم توزیعِ گوسی را در این دو بُعد نمایش دهیم مانند شکل زیر است:
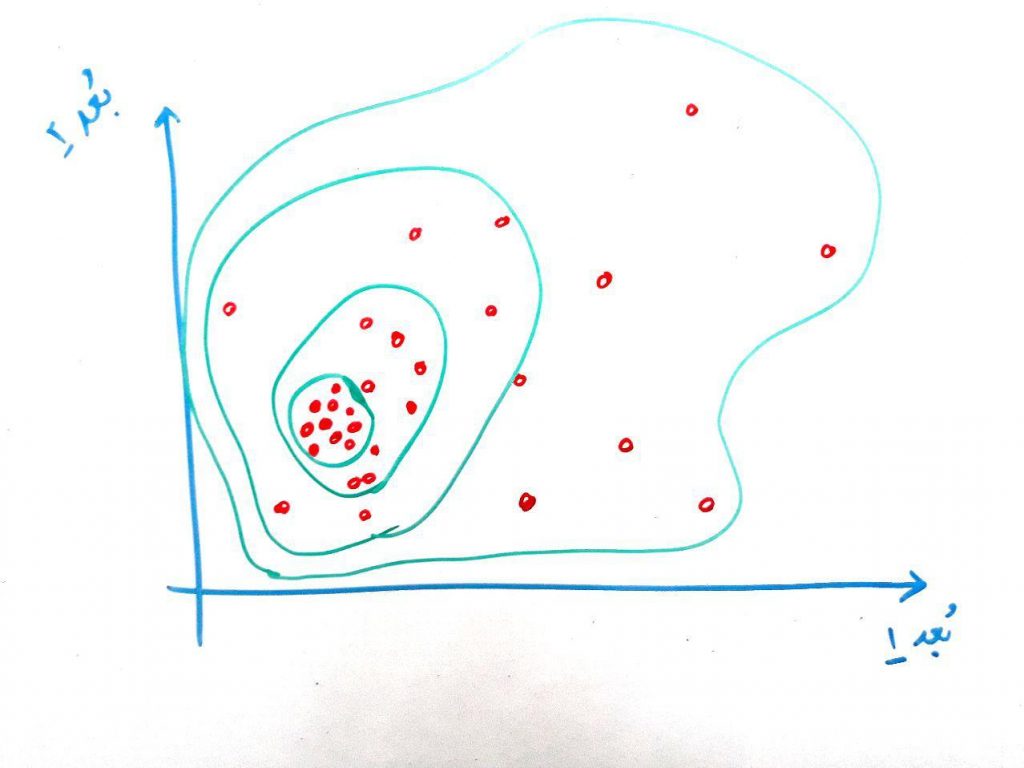
احتمالا این شکل برایتان آشنا باشد. در واقع دایره هایی که بیشتر در داخل قرار دارند، مناطقی هستند که تراکم (غلظت) دادهها در آن ها بیشتر است. مشاهده میکنید که هر چه از دایرههای داخلی دورتر میشویم، تراکمِ دادهها کمتر میشود. در اینجا در واقع یک ناحیه مرکزیت دارد و هر چه از این ناحیه دورتر میشویم غلظتْ کمتر میشود. این یک نوع توزیعِ گوسی در ۲بُعد میباشد. به توزیع گوسی، توزیع نرمال نیز میگویند.
حال فرض کنید مانند مثال دادههای پراید و اتوبوس، میخواهیم دادههای زیر را در دو خوشه، این بار به شکل زیر نمایش دهیم:
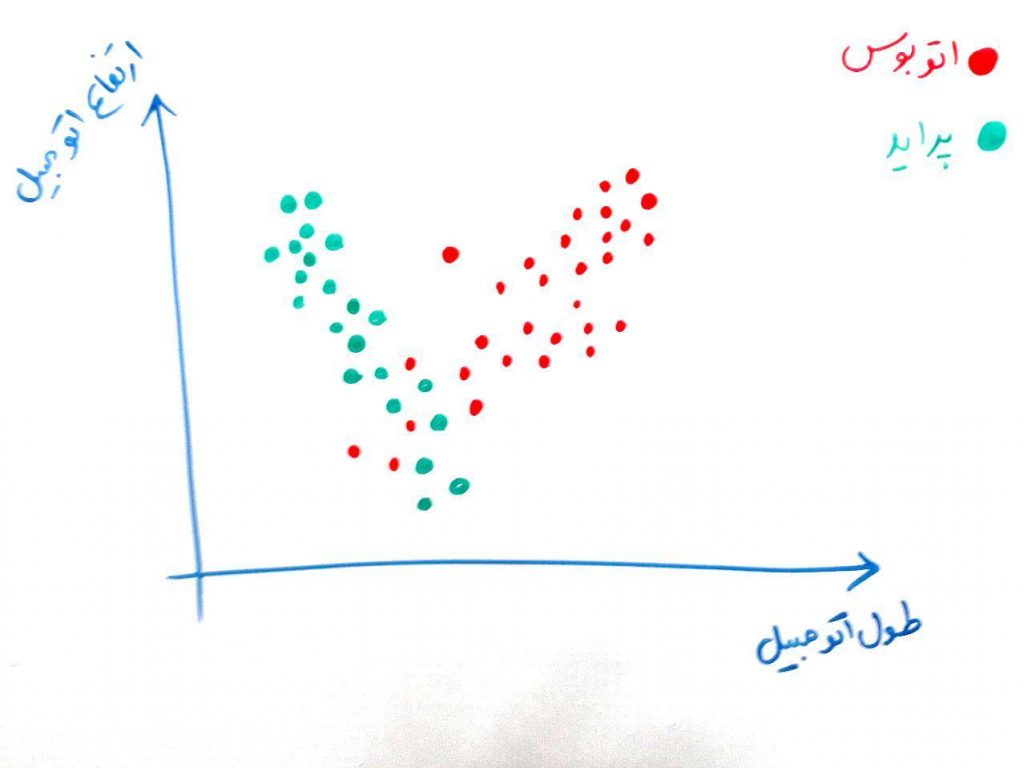
همان طور که میبینید، این دادهها در یکدیگر تنیده شدهاند. (یعنی مرز خیلی مشخصی بین پراید و اتوبوس وجود ندارد) در واقع ممکن است قسمتی از دادههای خوشه اول، کاملا در میان دادههای خوشه دوم باشد. توجه کنید که در خوشهبندی الگوریتم برچسبِ دادهها را نمیداند. مثلا نمیداند که کدام پراید است و کدام اتوبوس (ما برای فهم بهتر مخاطب این شکل را به صورتِ بالا رسم کرده ایم).
الگوریتمهای قبلی مانند KMeans و DBSCAN قادر به فهم این خوشه دادهها نیستند. ولی توسط مدلِ ترکیبیِ گوسی یا همان GMM میتوان این خوشهها را پیدا کرد. در واقع در این الگوریتم ابتدا فرض میکنیم که مثلا ۲خوشه داده داریم که از توزیعِ گوسی پیروی میکنند و با این فرض، به دنبال این دو خوشه میگردیم. مثلا فرض کنید شکل بالا دارای دو توزیع گوسی مانند شکل زیر است:
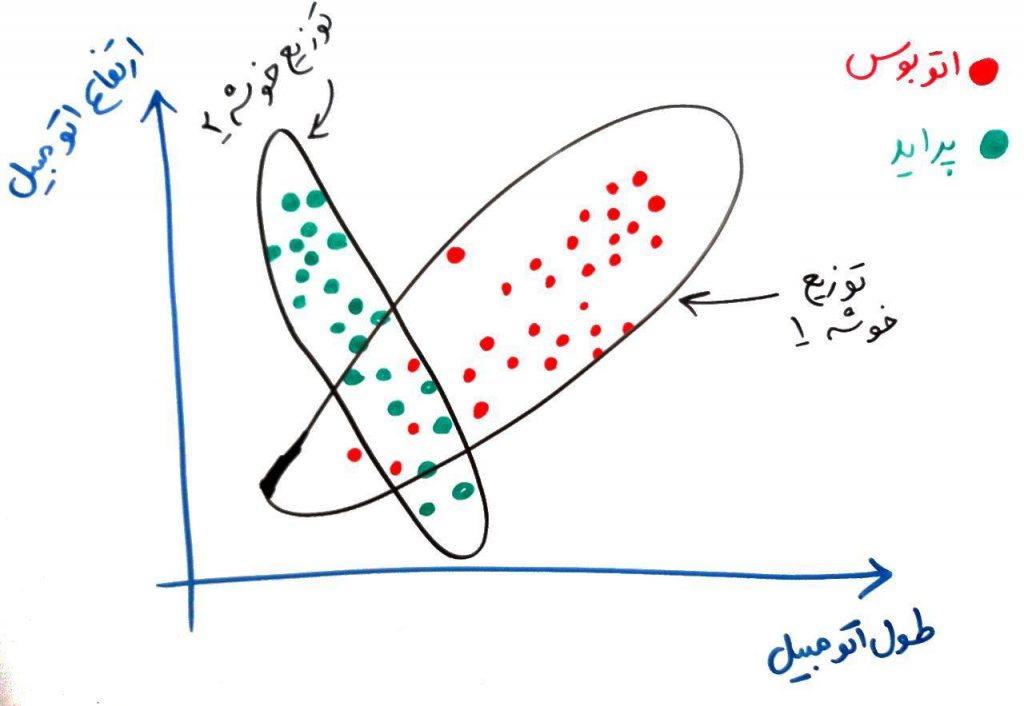
برای پیدا کردن دو خوشه که از توزیع گوسی استفاده میکنند از مدل مُولد (Generating Modeling) استفاده میشود. همان طور که گفته شد، فرض میکنیم هر خوشه از مدل گوسی پیروی میکند و با استفاده از مدلِ مُولد به دنبال پیدا کردنِ پارامترهایی برای برای توصیف گوسیِ دادهها میگردیم و این پارامترها را با استفاده از الگوریتم Expectation Maximization پیدا میکنیم.
حال اجازه بدهید توضیح دهیم که الگوریتمِ Expectation Maximization یا همان EM چگونه کار میکند:
این الگوریتم ۲ بخش دارد. بخش اول Expectation یا همان انتظار است، که در این قسمت، الگوریتم میخواهد ببیند که هر کدام از نمونه ها (نقاط) به کدام توزیعِ گوسی بیشتر نزدیک هستند و در واقع احتمالِ عضویتِ یک نمونه (نقطه) را به تابع گوسی پیدا کند. بحث EM در الگوریتم KMeans نیز وجود دارد. برای درک بهتر، الگوریتم KMeans را به یاد آورید. در هر دور (Iteration) از این الگوریتم، هر کدام از نمونهها (نقاط) به نزدیک ترین مرکز خوشه تعلق پیدا میکردند. این یعنی الگوریتم انتظار دارد که این نمونه (نقطه) به یک خوشهی خاص تعلق داشته باشد. حال در GMM در هر بار تلاش، الگوریتم انتظار دارد تا احتمالِ عضویتِ یک نمونه (نقطه) را به هر کدام از توزیع های گوسی مورد نظر نسبت دهد. این جا بخش اول تمام میشود. بخش دومِ روشِ EM در واقع Maximization یا بیشینهسازی است. در الگوریتمِ KMeans در هر دور نیاز بود که مرکزِ خوشه را تغییر دهیم تا شباهتِ مرکز خوشه با تمامی نمونه ها (نقاط) داخل آن خوشه بیشینه شود. در الگوریتم GMM نیز پارامترها که شامل وزن، میانگین و covariance است در هر دور آپدیت می شود تا در نهایت توزیع گوسی برای هر کدام از خوشه ها تشکیل شود و در واقع شباهت توزیع دادهها به صورت گوسی بیشینه شود. (از آنجایی که ما سعی داریم توضیحات را ساده کنیم، از نوشتن و توضیح فرمول ها گذر میکینم).
در واقع برای نمونه های بالا بعد از چندین بار تکرار مطلوب است که توابع گوسی مانند شکل زیر ایجاد شود:
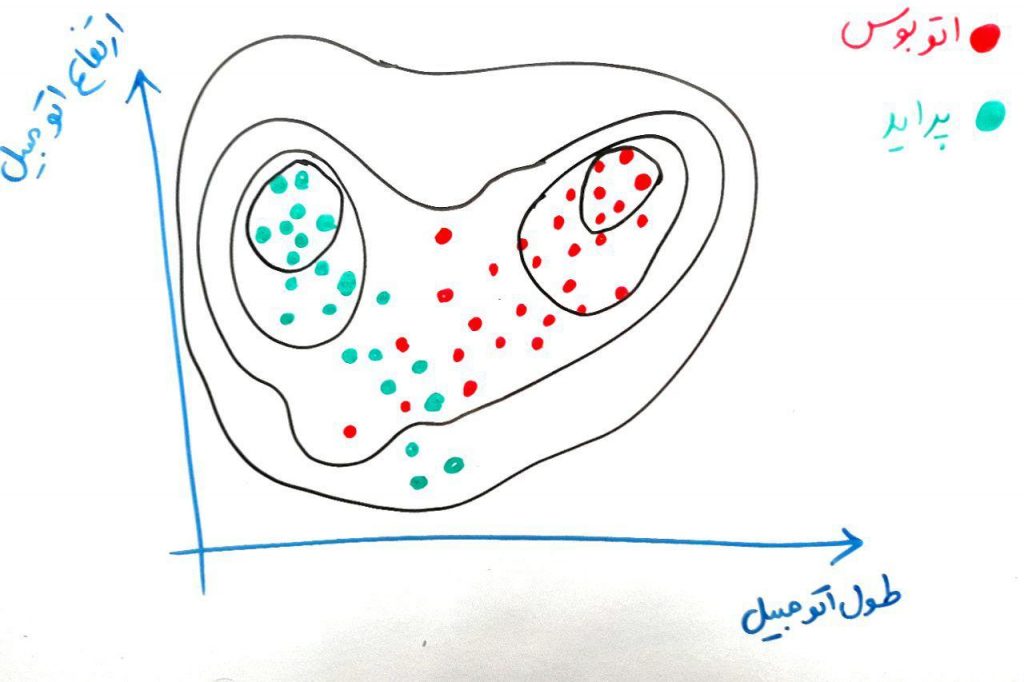
الگوریتم GMM دوخاصیت بسیار مهم نسبت به الگوریتمی مانند KMeans دارد. اول اینکه این الگوریتم میتواند خوشه هایی غیر کروی (دایره ای) را پیدا کند. همان طور که میدانید الگوریتم KMeans میتواند خوشه هایی کروی (دایره ای) را بیابد و این میتواند نقطه ضعف KMeans باشد، ولی در GMM با توجه به ساختار و توزیعِ گوسیْ عملیاتِ خوشهبندی انجام میشود. همچنین در الگوریتم GMM هر نمونه (نقطه) میتواند به چند خوشه تعلق پیدا کند (به نسبت عضویت در ساخت توزیع گوسی آن خوشه). در واقع در GMM ما نوعی خوشهبندی نرم (Soft Clustering) داریم که هر نمونه (نقطه) میتواند به بیش از یک خوشه تعلق داشته باشد. ولی در KMeans خوشهبندی یک خوشهبندیِ سخت است (Hard Clustering)، به این معنی که هر نمونه (نقطه) فقط میتواند به یک خوشه تعلق داشته باشد. مثلا اگر در جایی میخواهید مشتریانِ یک فروشگاه را به خوشههای مختلف تقسیم کنید و یک مشتری میتواند به چند خوشه (گروه) تعلق داشته باشد، میتوانید از این روشها (الگوریتمهای خوشهبندیِ نرم) استفاده کنید.

مطالب شما خیلی مفیده. با توضیحات ساده واقعا درک مطالب راحت تره
خیلی ازتون ممنونم
یه سوال داشتم از شما
smoothing factor دقیقا قضیش چیه ؟ ارتباطی با این GMM که توضیح دادید داره؟
بازم ممنون از شما
واقعا ممنون. خیلی عالی توضیح دادید.
سلام
متشکرم از مطلب مفیدتون
بنده به توضیحات جزیی تر و دقیق تری از این مطلب برای ارایه نیاز دارم.
می تونید به بنده با معرفی منبع یا هر راه دیگه ای کمک کنید؟
همیشه عالی و پر قدرت بی نظیرین شما
واااای خدا خیرتون بده. خیلی خوب توضیح میدین
ممنون بابت توضیحاتتون. عالی بود
خیلی خوب توضیح دادید و به نکات ریز اشاره کردید. (مثل اشاره به منظور دقیق از نمونه و…) کاش روش کار با الگوریتم رو هم توضیح میدادید