

در دورهی شبکههای عصبی با پرسپترون و چگونگیِ کارکردِ آن در طبقهبندها آشنا شدید. درسِ جاری بیشتر مروری از عملکردِ پرسپترون است تا ترتیب دوره جاری (الگوریتمهای یادگیریماشین بر روی دادههای حجیم) کاملتر شود.
همانطور که در درس پرسپترون یاد گرفتیم، پرسپترون در واقع یک طبقهبند خطی (linear classifier) است که میتواند تفاوت بین دو طبقه را تشخیص دهد. مثالِ درس پرسپترون به صورت زیر بود (میخواستیم تفاوت میان پراید و اتوبوس را با توجه به ویژگیهای آنها که همان طول و ارتفاع ماشین بود، به دست بیاوریم). دو شکلِ زیر برای کسانی که درس پرسپترون را خوانده باشند آشنا است:
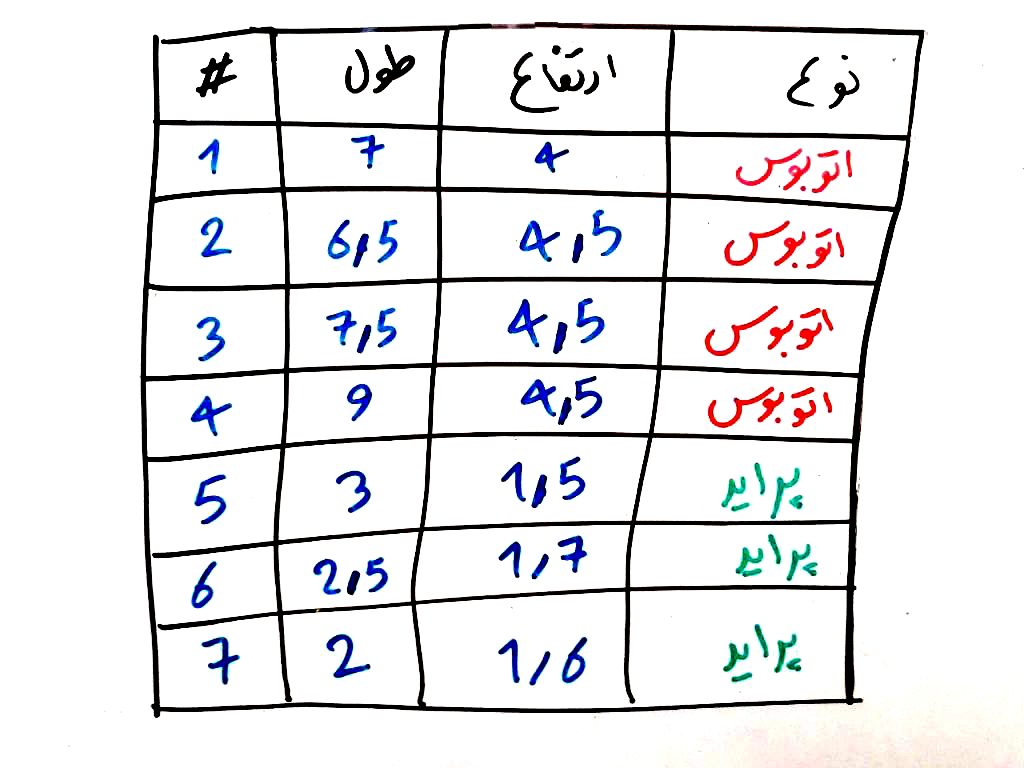
تصویر بالا بر روی دو بُعد (طول ماشین-محور افقی و ارتفاع ماشین-محور عمودی) نگاشت شده است:
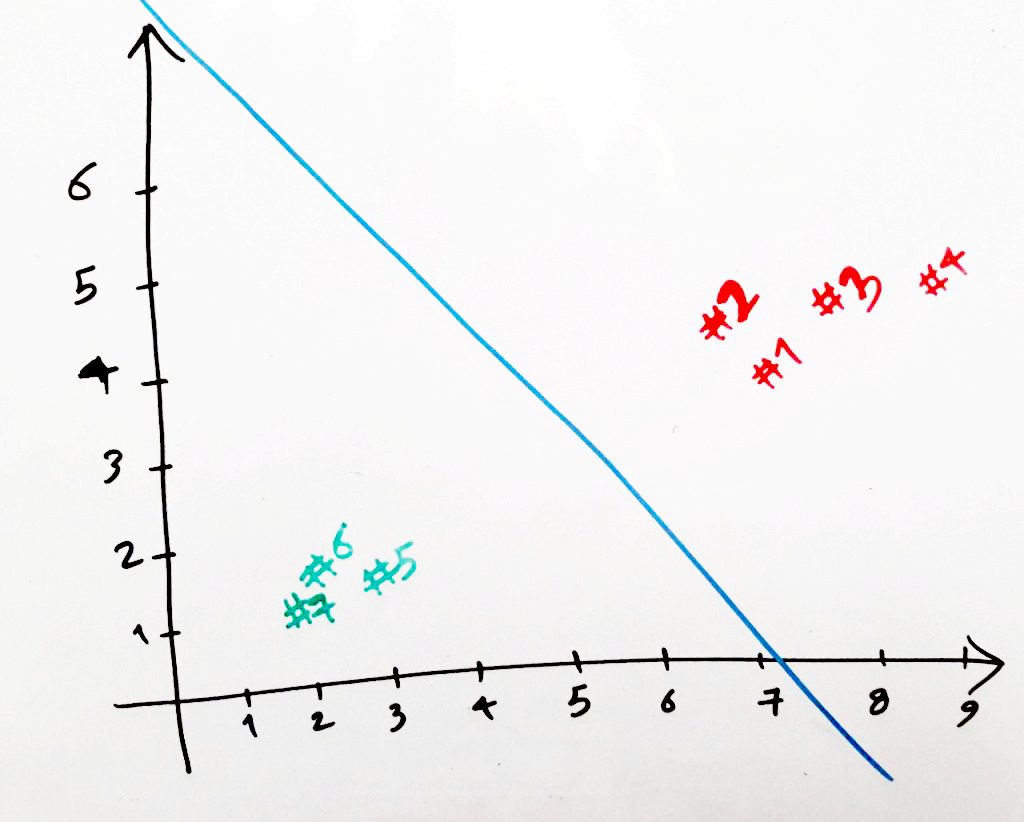
خطِ آبی که در تصویر بالا مشاهده میکنید، در واقع خطی است که پرسپترون (با توجه به پارامترهای W-شیب خط و b-انحراف خط) رسم کرده است. پرسپترون با استفاده از این خط میتواند بفهمد نقاطی که پایینتر از این خط هستند، نقاط پراید و نقاطی که بالاتر از این خط هستند نقاط اتوبوس هستند.
حال فرض کنید که خطِ آبیِ بالا به صورتی دیگر کشیده میشد. مثلاً مانند شکل زیر:
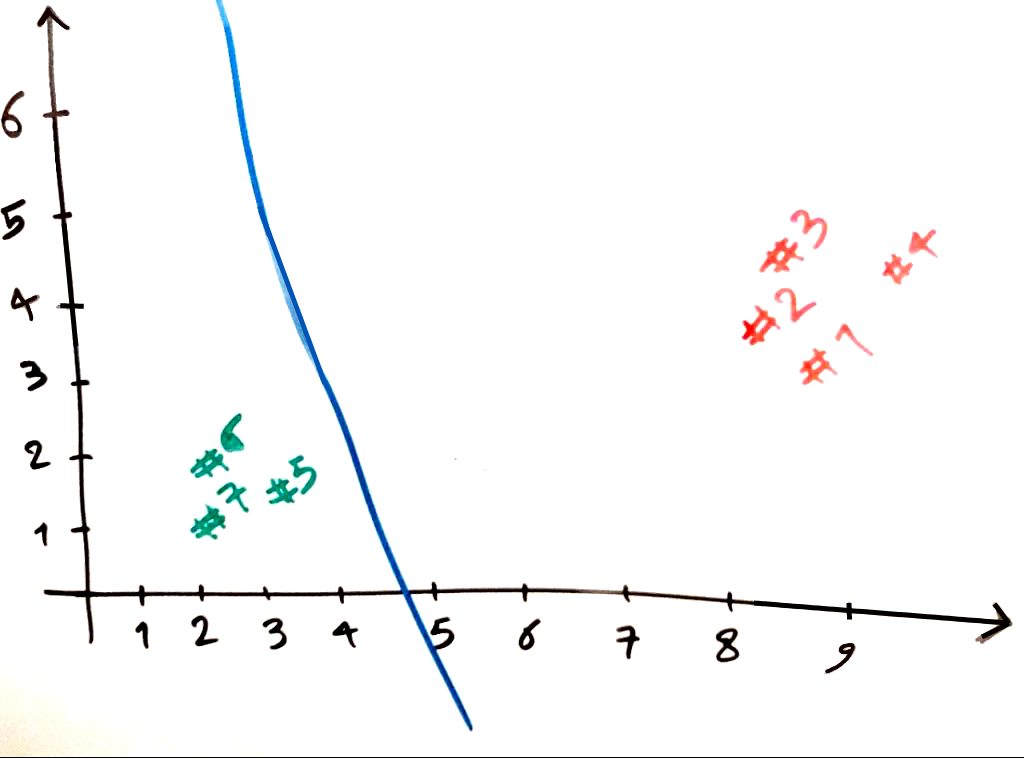
در واقع این خطی است که باز هم به صورت کامل پراید و اتوبوس را از هم دیگر جدا کرده است. حال فرض کنید یک نمونه جدیدِ ماشین میآید و الگوریتم نمیداند که این ماشین چیست. پس باید با توجه به خط جدا کنندهای که توسط دادههای آموزشی (همان داههای جدل بالا) یادگرفته است، این ماشین جدید را طبقهبندی کند. مانند new# در شکل زیر:
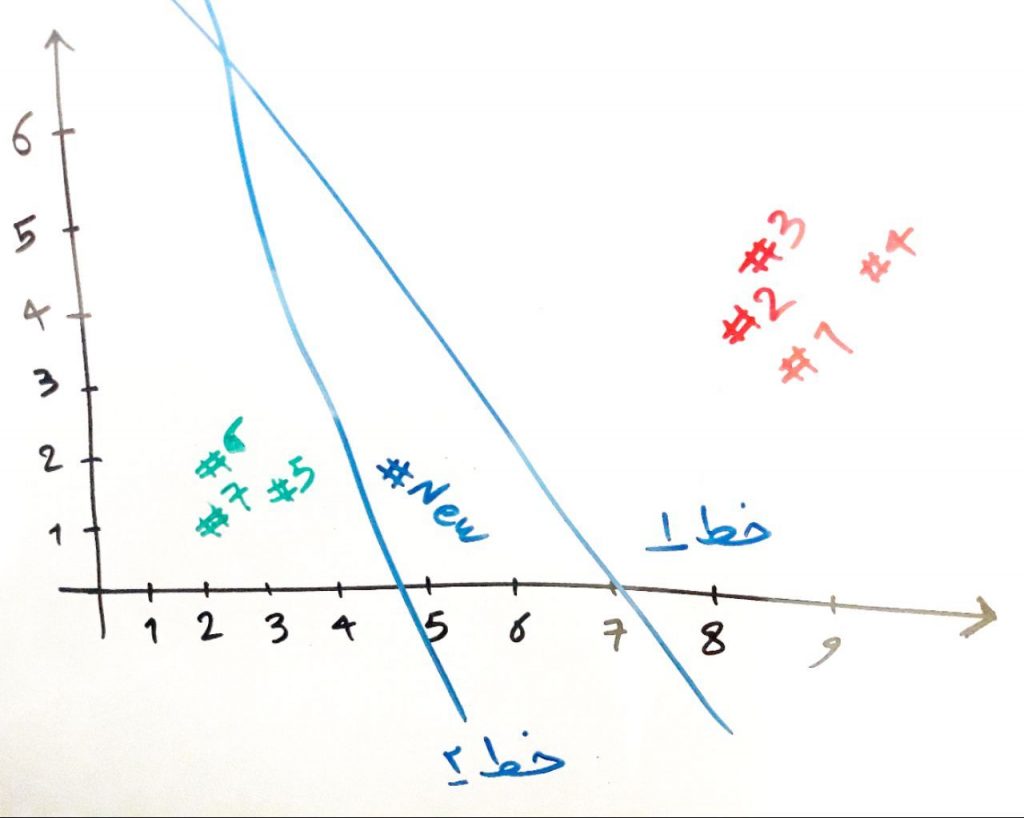
اگر خطِ آبی یعنی همان خطِ جداکننده، خط ۱ باشد، این اتومبیلِ جدید (new#) به دسته پرایدها میرود، این در حالی است که اگر خطِ آبی مانند خط ۲ باشد، این اتومبیل به دستهی اتوبوسها میرود. البته ما به عنوانِ یک انسان میتوانیم بفهیم که این اتومبیل بیشتر به پرایدها شبیه است چون نزدیکِ نمونههای پرایدهاست. ولی الگوریتم با توجه به خطی که از دادههای آموزشی یاد گرفته است، این تمایز و طبقهبندی را انجام میدهد. در واقع مشکلِ اصلیِ پرسپترون همینجاست که خطی که رسم میکند، خط بهینهای نیست و ممکن است خطا ایجاد کند. در درس بعد به روشِ به مراتب پیشرفتهتری به اسمِ ماشینِ بردار پشتیبان میرسیم که این مشکل را برطرف خواهد کرد.

با سلام،
جناب آقای کاویانی واقعا از شما متشکرم بابت سایت بسیار آموزنده چیستیو. همه مسائل با دقت و به روش بسیار خوبی بیان شده است. موفق باشید.