

اگر درسهای قبل، مخصوصاً درسِ کولهی کلمات (BoW) و تحلیل احساسات را خوانده باشید، احتمالاً متوجه یک نکته شدهاید. عموماً در متونِ مختلف، کلماتی وجود دارند که نزدیک به هم هستند ولی به دو یا چند شکل مختلف نوشته میشوند. الگوریتمهای متنکاوی این نوع کلمات را به دو یا چند شکل مختلف شناسایی میکند و نمیتواند رابطهی معنایی بین این این کلمات پیدا کتند. مثلاً فرض کنید دو کلمهی “غذا” و “غذاها” در یک جمله باشند. با استفاده از مدلهایی مانند BoW جهت تبدیل کلمات به ماتریس، کلمهی “غذا” یک ویژگی (بُعد) و کلمهی “غذاها” یک ویژگی (بُعد) دیگر میشود که این یک نقطه ضعف برای مدلهایی مانند BoW یا الگوریتمهای متنکاوی دیگر است.
برای یادآوری، دوباره مثالِ درسِ کولهی کلمات را میآوریم (به هر کلمه یک عدد نسبت داده میشد و هر کلمه به یک ستون ویژگی (بُعد) در ماتریسِ ویژگی نگاشت میشد:
- جملهی ۱: من از غذای این رستوران خوشم آمد
- جملهی ۲: غذای رستوران خیلی خوب بود ولی رفتار پرسنل نه
- جملهی ۳: جای پارک پیدا نمیشد و غذا خیلی دیر به دستمان رسید
من (۱)، از (۲)، غذای (۳)، این (۴)، رستوران (۵)، خوشم (۶)، آمد (۷)، خیلی (۸)، خوب (۹)، بود (۱۰)، ولی (۱۱)، رفتار (۱۲)، پرسنل (۱۳)، نه (۱۴)، جای (۱۵)، پارک (۱۶)، پیدا (۱۷)، نمیشد (۱۸)، و (۱۹)، غذا (۲۰)، دیر (۲۱)، به (۲۲)، دستمان (۲۳)، رسید (۲۴)
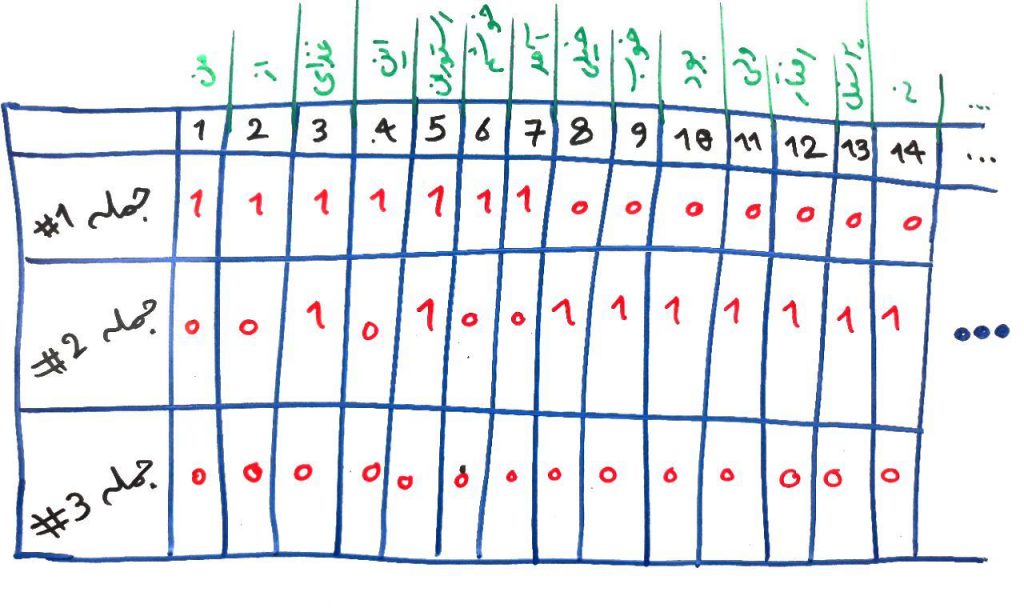
حال فرض کنید در جملهی دوم، به جای “غذای” از “غذاهای” استفاده میشد. آنوقت بایستی یک ستونِ ویژگی (بُعد) دیگر به ماتریس اضافه میکردیم و در تحلیلهای بَعدی (مثلاً طبقهبندی یا تحلیل احساس یا خوشهبندیِ متون)، این دو کلمه مجزا از هم در نظر گرفته میشدند (چون در دو ستون مختلف بودند و الگوریتم، اینها را دو کلمهی کاملاً جدا و بیربط به هم در نظر میگرفت). اما میدانیم که منظور از این کلمه یک چیز بوده و در واقع ریشهی این دو کلمه یکی هستند. ریشهی این دو کلمه “غذا” است.
عمل ریشهیابی این امکان را میدهند که فُرمهای مختلفِ یک کلمه را به یک فُرمِ واحد تبدیل کنیم. با این کار تعداد ویژگیها کمتر میشود (درس کاهش ویژگی را خوانده باشید) و همچنین شکلهای مختلفِ یک کلمه حذف شده و کامپیوتر میتواند شکلهای مختلفِ یک کلمه را یکی در نظر بگیرد.
برای ریشهیابیِ کلمات معمولاً از دو روشِ Stemming و Lemmatization استفاده میشود که هر دو روش قادر هستند ریشهی یک کلمه را به دست بیاورند. برای مثال کلمهای مانندِ “رفتن” را تصور کنید که ممکن است در جملههای مختلف به شکلهای گوناگون ظاهر شود. برای مثال:
- من به خیابان اصلی رفتم
- بیا با هم به مسافرت برویم
- کاش سال پیش سفری میرفتم
- میدانستم اگر با آنها بد صحبت کنند، احتملاً بروند
تمامیِ فعلهای “رفتن” در جملاتِ بالا را میتوان به کلمهی “رفت” نگاشت کرد. با این کار میتوان ۴ویژگی (رفتم، برویم، میرفتم، بروند) را به یک ویژگی (رفت) نگاشت کرد و با این عمل کاهش ویژگی (کاهش ابعاد) نیز انجام میشود.
الگوریتمهای مختلفی جهت انجام عمل Stemming (که یکی از روشهای به دست آوردن ریشهی کلمات است) وجود دارد. در زبان انگلیسی الگوریتم Porter بسیار معروف است. این الگوریتم طبق یک سری قاعدهی منظم (مثلاً حذف حرف s در آخر کلماتِ جمع) میتواند ریشهی کلمات را با دقتِ خوبی به دست آورد. همچنین در زبان فارسی، الگوریتم کاظم تقوی، این کار را با دقت بالایی (برای کلمات فارسی) انجام میدهد.
عمل Lemmatization نیز میتواند توسط روشهایی انجام شود. در این عمل نیاز است که از یک فرهنگ لغت یا چیزی شبیه به آن برای به دست آوردنِ ریشهی لغات استفاده شود، چون عموماً روشهای Lemmatization به صورت با قاعده نیستند.

- ۱ » متن کاوی (Text Mining) و پردازش زبان طبیعی (NLP) چیست؟
- ۲ » ساخت کولهی کلمات (Bag of Words) در پیشپردازش متون
- ۳ » روش TF-IDF برای ساختاردهی به دادههای متنی
- ۴ » تحلیل احساسات (Sentiment Analysis) در متنکاوی
- ۵ » n-gram و کاربرد آن در متنکاوی
- ۶ » مدلسازی موضوعات (Topic Modeling) و کاربرد آن در متنکاوی
- ۷ » یافتن ریشه کلمات با Stemming و Lemmatization
- ۸ » تشخیص شباهت متون (Text Similarity) با استفاده از الگوریتم Jaccard
- ۹ » خوشهبندی متون (Text Clustering) و کاربردهای آن
سلام هیچ جا نتونستم پیاده سازی الگوریتم کاظم تقوی پیدا کنم همه جا مختصری راجع بهش توضیح داده الگوریتمش چه جوری می تونم پیدا کنم؟
سلام
برای متون فارسی این الگوریتم رو در چه پکیج هایی میشه پیدا و استفاده کرد؟
درود بر شما، واقعا لذت بردم از اینکه این مفاهیم را برای ما به صورت مفصل و ساده بیان کردین. خدا از شما راضی باشد.
سلام. تشکر از زحماتتون. ببخشید منظور از. حالت باقاعده چی هست؟
و اینکه اگر بخوایم متن های نظر سنجی رو بررسی کنیم، مثلا کلمات فارسی که با حروف انگلیسی نوشته شدن رو چیکار میکنیم؟ مثلا همون غذا رو کسی اگه با حروف انگلیسی تایپ کنه میشه ghaza