

Cassandra یک پایگاه داده توزیع شده است. برای اینکه بدانید توزیع شدگی چیست، بهتر است درس سیستم توزیع شده چیست را مطالعه ای داشته باشید. این پایگاه داده برای مدیریت داده های بزرگ و مه داده (Big Data) کاربرد فراوانی دارد. Cassandra هیچ نقطه خاص خرابی (Single Point Of Failure) ندارد و به راحتی میتواند بر روی چندین کامپیوتر توزیع شود.
این پایگاه داده توسعه پذیر خطی (Linear Scalable) است و دسترس پذیری بالایی (High Availability) دارد. برای درک مفهوم توسعه پذیر خطی میتوانید این درس را مطالعه کنید. Cassandra برای کار با داده های بسیار بزرگ طراحی شده است تا کاربران بتوانند این داده ها را به راحتی و با سرعت بالا دریافت کنند.
در Cassandra از معماری Master/Slave استفاده نشده است. زیرا در این معماری معمولا گره Master (سرپرست) به دلیل کارکرد زیاد به گلوگاه سیستم (Bottleneck) تبدیل می شود. یعنی در صورتی که master از کار بیفتد یا کند شود، کل سیستم از کار می افتد یا کند می شود. برای همین در Cassandra چیزی به نام Master وجود ندارد و تمامی گره ها (کامپیوترها)ی متصل به هم، مانند یکدیگر رفتار می کنند. داده ها در گره های مختلف تکرار (Replicate) می شوند. ساختار تکرار و تکثیر در آپاچی کاساندرا مانند شکل زیر است:
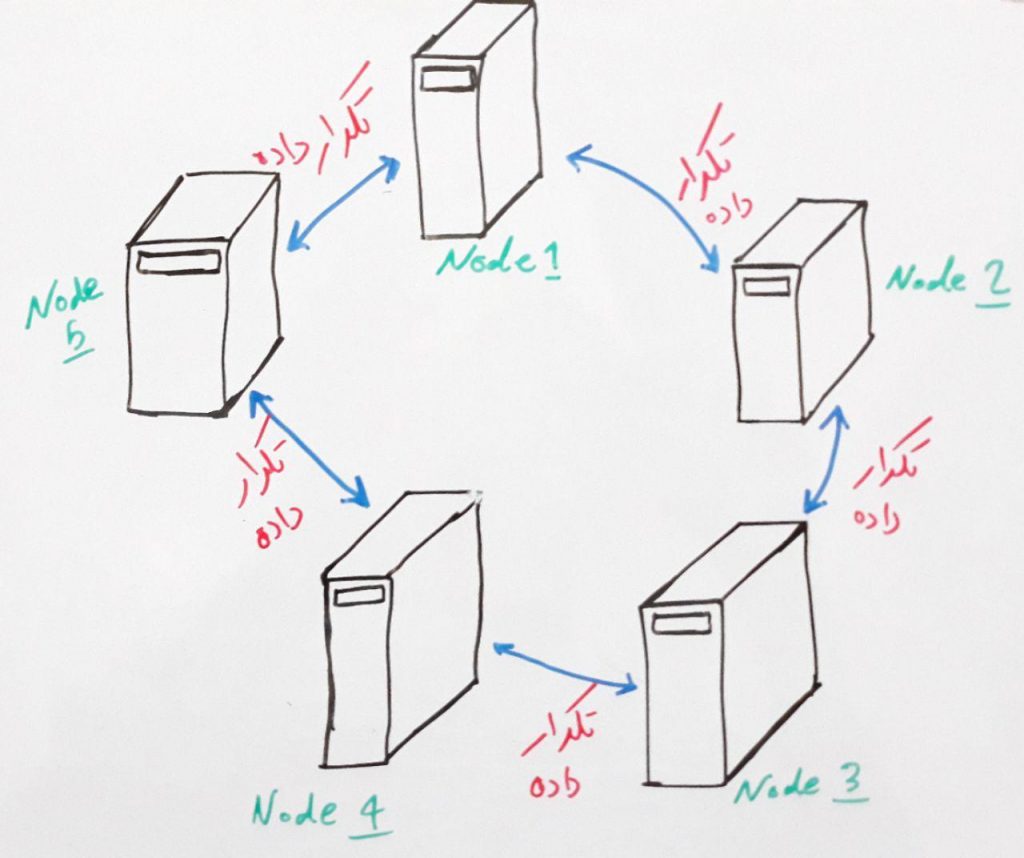
همان طور که میبینید داده ها به صورت P2P (همتا به همتا) بر روی گره های مختلف تکثیر می شوند.
در درس آشنایی انواع با پایگاه داده NoSQL بحث کردیم که Cassandra از دسته Column Family Databaseها است. این پایگاه داده ها که داده ها را به جای اینکه به صورت سطر به سطر مشاهده کنند، به صورت ستون به ستون مشاهده و ذخیره سازی میکنند، مناسب برای کاربردهایی مانند پردازش داده های بزرگ و BigData هستند.
Cassandra از زبان پرس و جویی به نام CQL استفاده میکند که بسیار شبیه SQL است و برنامه نویسانی که میخواهند از SQL به Cassandra مهاجرت کنند، کار زیاد سختی در پیش ندارند.

عالی بود. ممنون
سلام.ممنون .خیلی خوب بود.از دست اندرکاران وبسایت
به این خوبی سپاسگزارم
سلام وقتتون بخیر من کاساندرا رو بصورت آفلاین و با فایل tar نصب میکنم ولی متاسفانه سرویس آن استارت نمیشه و سرویس کاساندرا رو نمیشناسه ولی nodetool status دارای خروجی درستی هستش
امکان داره کمکم کنید
با سپاس