

اکثرِ الگوریتمهای دادهکاوی، نیاز دارند تا دادههای عددی را دریافت کنند و ساختارِ یادگیریِ آنها بر اساسِ یادگیری از ماتریسهای عددی است. در درسِ طبقهبندی دیدید که چگونه میتوان یک سری ویژگی را به صورت ماتریس ساخت و به الگوریتمِ طبقهبندی داد. اما یادمان باشد که همیشه دادهها به صورتِ عددی آماده نیستند و بعضاً نیاز دارند تا به فرمتِ دلخواهِ الگوریتم (یعنی همان فرمتِ ماتریسِ عددی) تبدیل شوند. این دست از دادهها بایستی قبل از تزریق به الگوریتم، به فُرمتِ مناسب تبدیل (transform) شوند. روشهای تبدیل داده بسیار گسترده و متنوع است و در این درس، یکی از آنها را با هم مرور میکنیم.
اجازه بدهید نگاهی به جدولِ زیر بیندازیم:
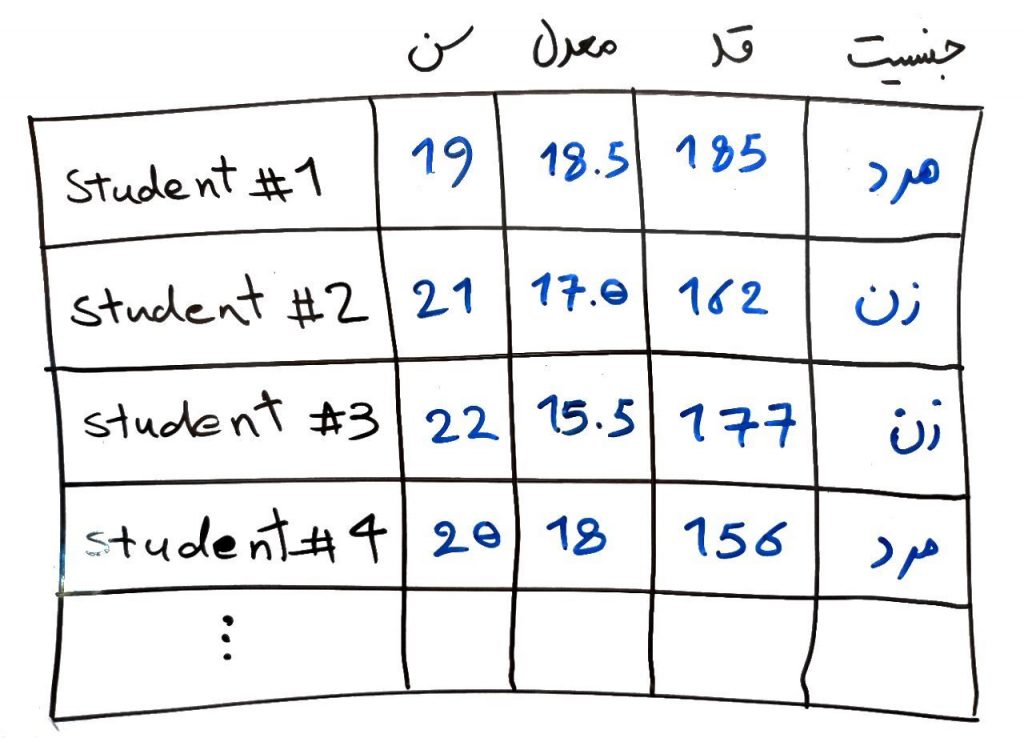
فرض کنید در اینجا تعدادی دانشآموز داریم که هر کدام ویژگیهای مختلفی دارند. سن، معدل، قد و جنسیت ۴ویژگیِ دانشآموزان هستند که میخواهیم بر روی آنها عملیاتی مانند عملیاتِ خوشهبندی را انجام دهیم. همانطور که میبینیدِ، ۳ ویژگیِ اولْ عددی هستند و ویژگیِ آخر یعنی جنسیت ۲ مقدار دارد، مرد و زن. در اصطلاح، ویژگیِ جنسیت یک ویژگیِ categorical است، به این معنی که یک مقدارِ عددی نیست که بتوان بزرگی یا کوچکی را با آن مشخص کرد. مثلا زن از مرد بزرگتر نیست و یا برعکس. این دستْ از ویژگیها برای بسیاری از الگوریتمهای دادهکاوی نامفهوم هستند. بنابراین بایستی به ویژگیهای عددی تبدیل شوند. در مثالِ بالا اگر بخواهیم جنسیت را به ویژگیِ عددی تبدیل کنیم، شکلِ بالا به شکلِ زیر تبدیل میشود:
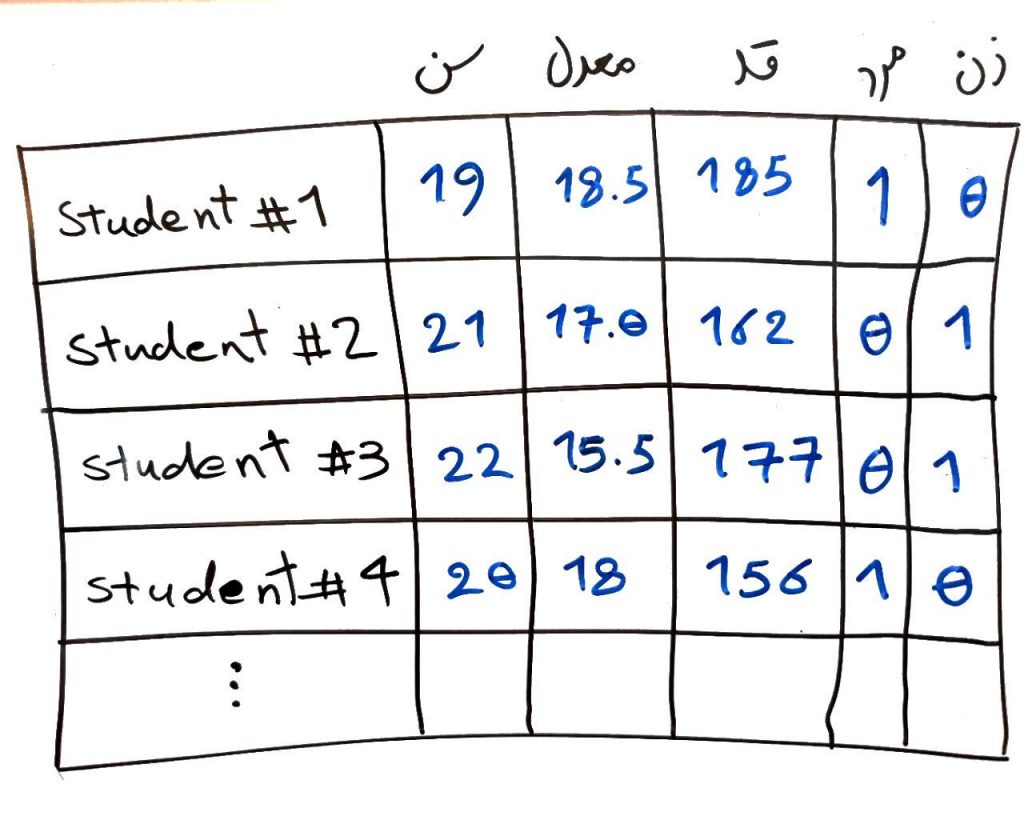
در اینجا به ازای هر نوع جنسیت، یک ستون اضافه کردیم (ستون جنسیت نیز حذف شد). همانطور که مشاهده میکنید چون ۲ نوع جنسیت (مرد و زن) داشتیم، پس دو ستون یعنی دو ویژگی اضافه کردیم و با توجه به هر دانشآموز، مقدارِ مرد بودن و یا زن بودن را در سطرِ مربوطه برابرِ ۱ قرار دادیم و دیگری را برابرِ ۰. مثلا دانشآموزِ اول (student#1) یک مرد است. پس ستون مرد، برای این دانشآموز برابرِ ۱ و ستون زن برای این دانشآموز برابر ۰ قرار میگیرد، و به همین ترتیب برای بقیهی سطرها همینکار را تکرار میکنیم. مثلاً اگر این ستون مقدار دیگری مانندِ جنسیت نامشخص داشت، آنگاه بایستی این ویژگی به سه ستون شکسته شود. مرد، زن و نامشخص و در هر سطر، یکی از این ویژگیها ۱ و بقیه ۰ میشدند
در اصطلاح به این فرآیند one hot encoding نیز گفته میشود، چون در هر سطر فقط یکی از ستونهای آن نوع (مثلاً جنسیت) ۱ و بقیه صفر هستند.

- ۱ » پیش پردازش دادهها (Data Preprocessing) چیست؟
- ۲ » بررسی یکپارچگی دادهها (Data Integrity)
- ۳ » نرمال کردن دادهها (Data Normalization) و انواع آن
- ۴ » تبدیل دادهها (Data Transformation) به فُرمت قالب فهم برای الگوریتم دادهکاوی
- ۵ » دادههای گمشده (Missing Values) و راهکارهای مقابله با آنها
- ۶ » تشخیص دادههای پرت و دارای نویز (Noise) و راهکار مقابله با آنها
- ۷ » انتخاب ویژگی (Feature Section) و کاهش ابعاد
- ۸ » انتخاب نمونه (Instance Selection) در پیش پردازش دادهها
سلام. برای الگوریتمی مثل آنالیز تفکیک خطی (linear discriminant analysis ) که نیاز هست تمام ویژگی ها پیوسته باشن اگر ویژگی categorical (صفر و یکی) داشته باشیم چه تغییری باید انجام داد تا این ویژگی ها قابل استفاده برای این الگوریتم باشن؟
سلام
اگر درست متوجه شده باشم، با روشهایی مانند OneHotEncoding میتوان دادهها را به صورت رقمی درآورد
سلام.
در روش one hot encoding برای n ویژگی باید n-1 ستون تشکیل بشه.
مثلا در این مورد دوستون مرد و زن ، الزامی نیست و میشه یکی رو حذف کرد.
چون معلومه که اگر مقدار یک سطر در ستون مرد ۰ باشه ، یعنی زن هست و نیازی نیست که باز در ستونی مجزا به زن بودنش اشاره کرد.
ممنون 🙂
سلام و ممنون از دقت نظرتون
بله، منتهی به دلیل اینکه عدد ۱ بزرگتر از عدد ۰ هست، میخواستیم اصل منصف بودن را برای دو رعایت کرده باشیم
تشکر از مطالب خوبتون.
سلام در مورد ویژگی هایی که بیش از دو حالت دارد مانند شهر محل زندگی چه باید کرد؟
سلام
الگوریتم one hot encoding، به ازای هر کدام از شهرها یک ستون میسازد. مثلا اگر ۳۰ شهر داشته باشید، ۳۰ ستون میسازد و در هر سطر، آن ستونی را که مقدار متناظر آن شهر را دارد برابر ۱ و بقیه را برابر صفر قرار میدهد
با سلام، در این حالت اگر بیایم تعداد ستون ها را زیاد نکنیم و در همون ستون برای هر شهر یک کد (مانند ۰ و ۱ و ۲ و … ) در نظر بگیریم، چه مشکلی پیش میاد؟
به نظر یک روش درست هست،
مثل ویژگی هایی که مقادیر مختلف عددی دارند ولی ارتباطی بین اعداد وجود نداره (مثل سن و قد نباشند)
سلام
شدنی هست، ولی بسیاری از کتابخانهها این ستون را عددی شناسایی کرده و مانند یک ویژگیِ عددی با آن برخورد میکنند
سلام استاد گرامی.
از شما بابت مطالب علمی، ارزشمند و فنی که نوشتید سپاسگذارم.
ممنون میشم منو راهنمایی بفرمایید.
سوالم در رابطه با اسم و یا عنوان دسته بندی الگوریتم هاست.
من در حال نوشتن مقاله ای در خصوص تعمیرات و نگهداری با استفاده از پایگاه داده UCI هستم.
در این پایگاه داده ۱۶ ویژگی و ۲ ویژگی کلاس یا لیبل وجود داره.
من برای تحلیل بیشتر ویژگی کلاس رو تقسیم بندی کردم به چند دسته (سالم، مناسب، متوسط، در حال خرابی و خراب). این دسته بندی ها در دیتاست وجود نداشت و من خودم ایجادش کردم.
در واقع برای ویژگی لیبل گسسته سازی انجام دادم.
برای تحلیل داده های عددی از الگوریتم های (network algorithm, linear regression, k-nearest neighbor, deep learning) و برای داده های گسسته سازی شده از الگوریتم های (neural network algorithm, decision tree, GLM regression, and random tree algorithm) استفاده کردم.
الان موندم عنوان این کار من این میشه؟:
classification algorithm with numeric attributes and discretizing numeric attributes
یا این میشه؟
classification with regression and discretization label
سلام، ممنون از شما
به نظر من دومی بهتره
سلام، مسیله من یک تعداد ویژگی دارد که قرار است مهمترین ویژگی ها بر متغیر پاسخ تشخیص داده شود به عبارتی قراره انتخاب ویژگی کنم ولی روش های انتخاب ویژگی که میشناسم باید همه متغیر ها عددی باشند در صورتی که یک تعداد از ویژگی های مسیله من اسمی هستند. آیا باید همه ویژگی ها را عددی کنم بعد انتخاب ویژگی انجام بدهم؟ اگه اینطوره چه روش هایی برای عددی کردن ویژگی ها میشناسید؟
لطفا جواب را به ایمیلم بفرستید. ممنون
سلام و ممنون از وقتی که میگذارید
میتونید با روشهایی مانند one hot encoding عملیات عددی سازی را انجام داده و بعد انتخاب ویژگی رو داشته باشید
با سلام و وقت بخیر
راجع به موضوع کیفیت و ارزیابی مواد غذایی با استفاده از ماشین بویایی تحقیق می کنم. در این روش با استفاده از حسگر نمودارهایی برحسب زمان در محور افقی و ولتاژ در محور عمودی برای هر نوع بو بدست می یاد یعنی هر نمونه ای که وارد میشه بویی داره و یه نمودار از دستگاه بدست میاد. من میخوام برای این نمودارها ماتریس ویژگی رو بنویسم تا در گام بعد با استفاده از pca کاهش بعد رو انجام بدم و ویژگی های اصلی رو بدست بیارم.مشکل اینجاست که این نمودارها یه منحنی هستن و من نیاز به یک عدد در ماتریس دارم. در واقع به جای هر نمودار باید یه آرایه عددی در ماتریس قرار بگیره. سوالم اینه که چطور میشه این نمودارها رو به عدد تبدیل کرد؟
سلام
می خواستم بدونم ترجمه این عبارت چی میشه؟ معادلی براش هست one-hot encoding?
hot در اینجا چی میتونه معنی بشه :کدگزاری یکسان کننده ، کدگزاری یکسان کننده اهمیت؟
ممنون