

تا اینجا در دورهی آشنایی با شبکههای عصبی، به این نتیجه رسیدیم که شبکهی عصبی به دنبال یک سری وزنها (W) و انحراف (b) هست تا بتواند خطوطی مرزی بین انواع مختلف (مثلا پراید و اتوبوس) رسم کرده و به وسیلهی آنها، تفاوتها را یادگرفته و درک کند. این کار با استفاده از قانونِ ضرب و توابعِ فعالسازی انجام میشد. در این درس آرام آرامْ به سمت آموزش در شبکهی عصبی میرویم. این نکته را بدانیم که پایهی آموزش در شبکههای عصبی بر اساسِ تابع ضرر است.
تابعِ ضرر (loss function) یا تابعِ هزینه (cost function) در واقع میزان خطا در هر بار اجرای شبکهی عصبی را برای دادههای آموزشی نمایش میدهد. بیایید یک بار دیگر به شکلِ زیر نگاه کنیم. این شکل در دروس گذشته بسیار مورد استفاده بود:
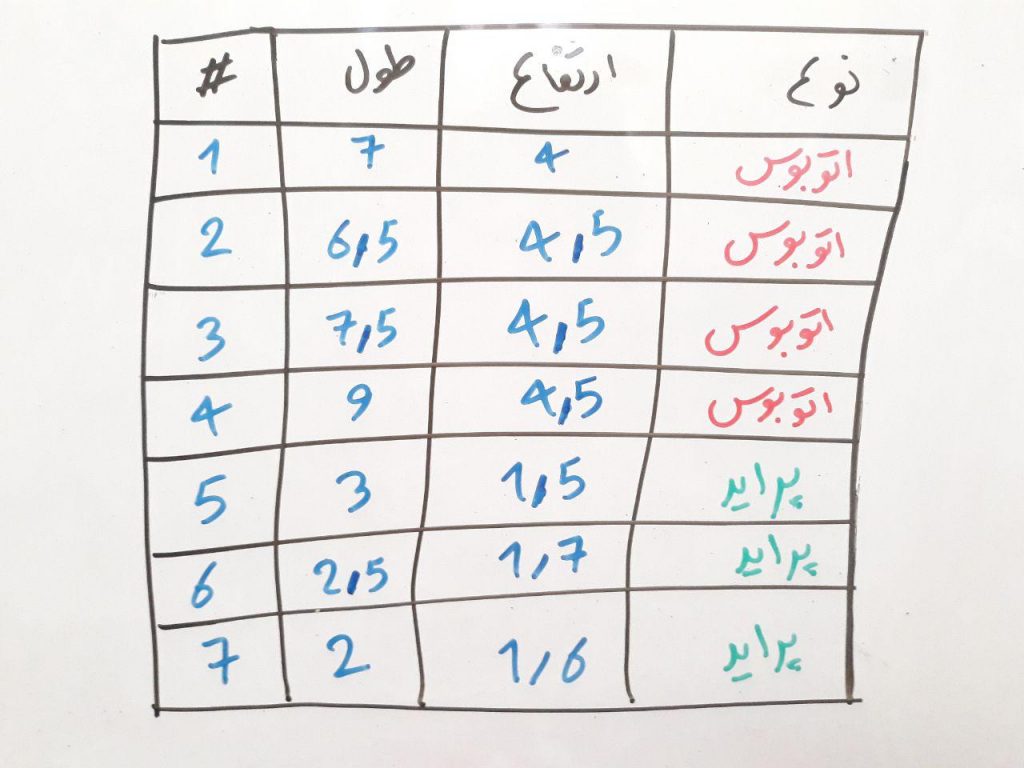
اجازه بدهید این بار به نحوی دیگر به این جدول نگاه کنیم. همانطور که در درسِ طبقهبندی با یکدیگر مرور کردیم، این جدولِ بالا در واقع دادههای آموزشیِ ما است. دادههایی که میخواهیم به طبقهبند (در اینجا شبکهی عصبی) بدهیم و از شبکهی عصبی انتظار داریم که از روی این دادهها، تفاوتِ پراید و اتوبوس را یاد بگیرد. همانطور که در دروسِ قبلیِ دورهی شبکهی عصبی گفتیم، یادگیری در شبکهی عصبی به وسیلهی وزن (W) و انحراف (b) صورت میگیرد. در واقع وظیفهی شبکهی عصبی، یادگیری مقدارِ درستِ وزنها و انحرافات در شبکه است به گونهای که بتواند مثلاً پراید و اتوبوس را از یکدیگر تفکیک کند.
در شبکههای عصبی این کار با تکرار (iterate) انجام میشود. به گونهای که چندین بار دادههایی مانندِ جدول بالا، به الگوریتم داده شده و هر بار الگوریتم باید مقدار وزن و بایاس خود را آپدیت کند. در اولین بار اجرای الگوریتم شبکه عصبی، این الگوریتم یک سری مقدار وزن و انحراف اولیه را به بُردارهای وزنها (W) و انحراف (b) میدهد تا این بُردارها یک سری مقدار اولیه داشته باشند. سپس در هر بار اجرا، شبکهی عصبی خطای خود را محاسبه کرده و توسطِ آن مقادیرِ خطا، وزنها و انحراف را به هنگام (update) میکند. این محاسبهی خطا باید توسطِ تابع هزینه یا تابع ضرر حساب شود. در واقع شبکه با مشاهده مقدارِ ضرری که در هر بار اجرا داشته است، یاد میگیرد که چه مقدار بایستی وزنها و انحراف را به هنگام (update) کند.
اجازه بدهید در قالب همان مثال بالا، تابع ضرر را توضیح دهیم. فرض کنید در ابتدا یک سری اعداد اولیه به صورت تصادفی به وزنها و انحرافها داده شده است. این وزنها و انحراف باعث میشود که شبکهی عصبی یک تصمیم در مورد هر کدام از ماشینهای جدول بالا بگیرد. تصویر زیر را نگاه کنید (فرض کنید در دورِ اول از اجرای شبکهی عصبی، شبکه با توجه به وزنها و انحراف به خروجی زیر میرسد):
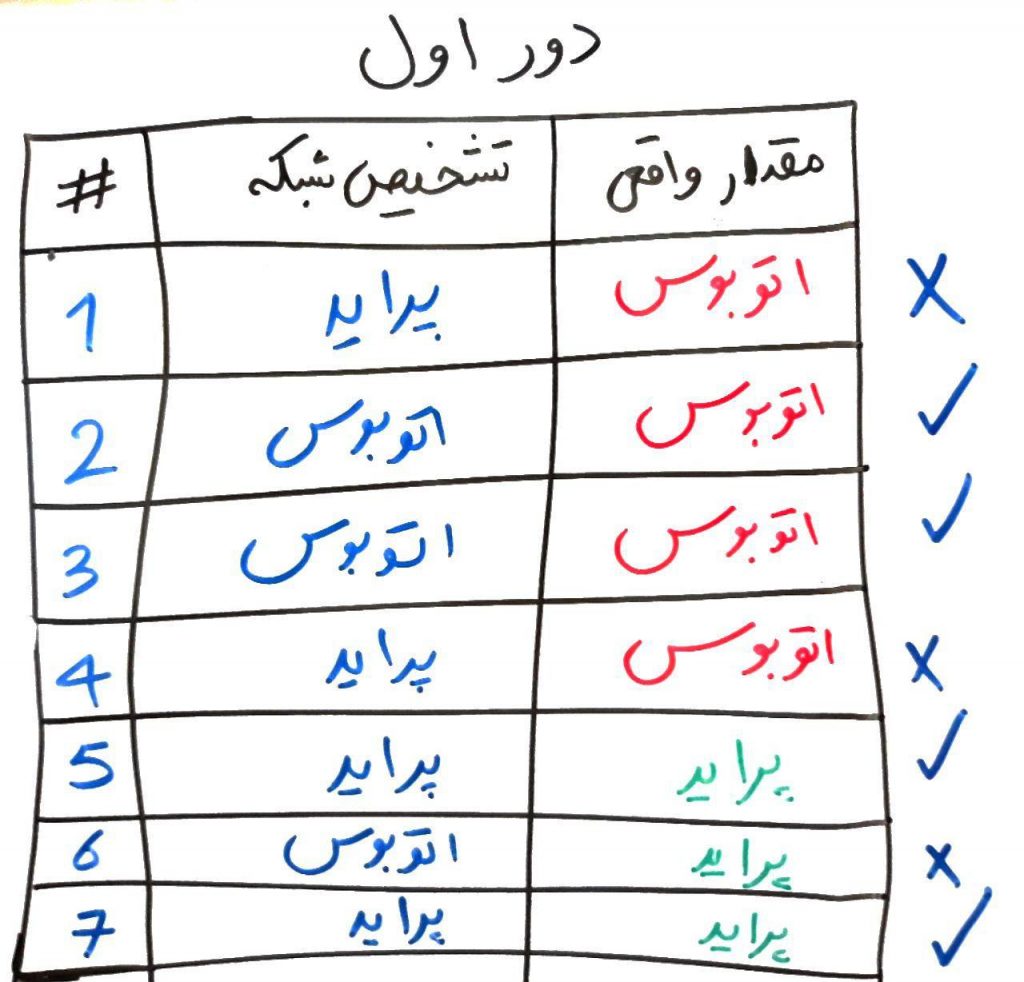
همان طور که میبینید، در دور اول، شبکه توانسته است ۴ تا از ۷ ماشین را درست پیشبینی کند (که میتوان گفت بر اساس شانس بوده است). حال شبکه میتواند بفهد که مقدار خطایش ۳ از ۷ است. یعنی ۳ تا از ۷ ماشین را غلط ارزیابی کرده است. اگر از دروسِ قبل یادتان باشد، گفتیم اگر خروجیِ شبکه ۰ بود پراید و اگر خروجی شبکه ۱ بود یعنی منظور شبکهی عصبی اتوبوس است. حال با یک فرمولِ ساده میتوانیم خطا را حساب کنیم. فرمول مانند شکل زیر است:
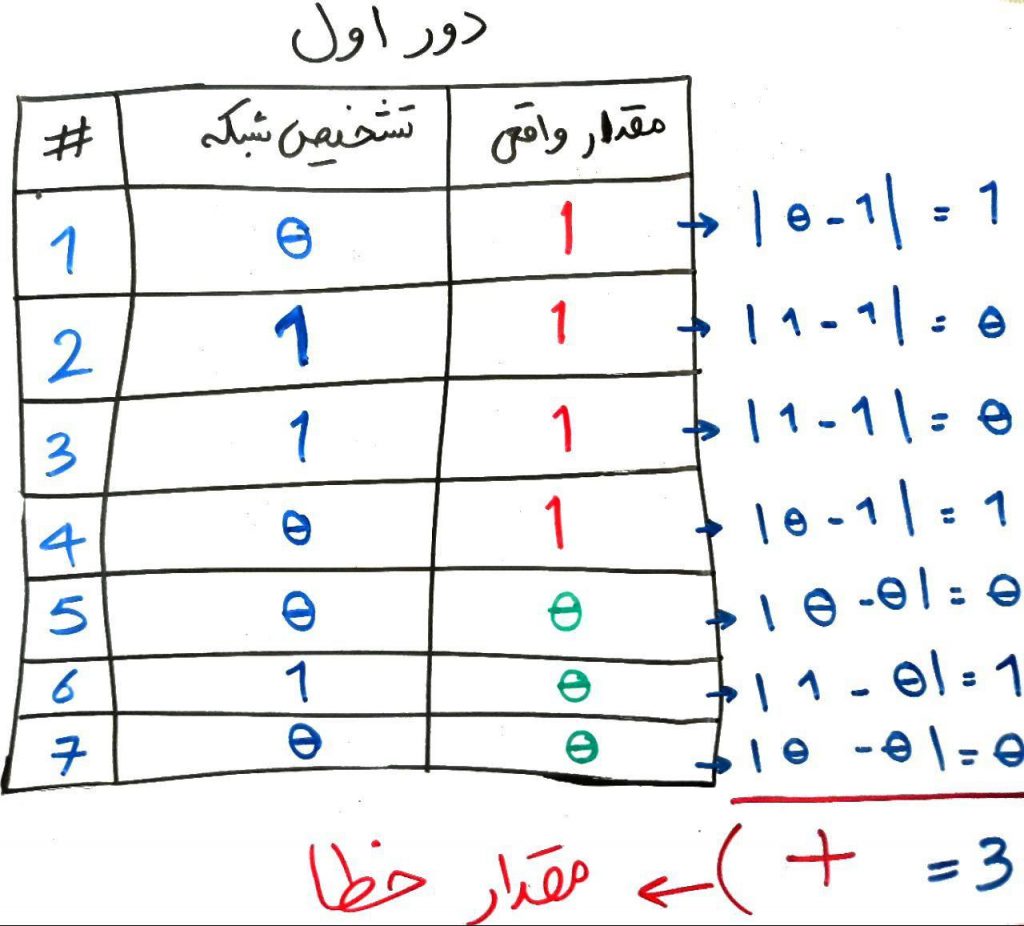
به تصویرِ بالا با دقت نگاه کنید. در بسیاری از مقالات و دروس شبکهی عصبی، مقدارِ واقعی را برابر y، و مقداری که شبکه تشخیص داده است را ´y می نامند. اگر این دو مقدار را برای هر کدام از نمونهها از هم دیگر کم کنیم و قدر مطلق بگیریم، خروجی برای هر کدام از نمونهها مقدارِ اختلاف بین تشخیص شبکه و مقدار واقعی را بیان میکند. حال این مقادیر اختلاف را با یکدیگر جمع میکنیم تا مقدار کلیِ اختلاف به دست بیاید. مثلا در اینجا عدد ۳ به دست آمده است. هر چقدر این عدد نهایی بالاتر باشد به این معنی است که شبکهی عصبی خطای بیشتری در آن دور (iteration) دارد. یعنی باید وزنها و انحراف را به مقداری بیشتری به هنگامسازی (update) کند. با هر بار به هنگامسازیِ وزنها و انحراف، یک دور تمام شده و دورِ بعد شروع میشود. با تغییراتِ مختلفی که شبکهی عصبی در وزنها و انحراف میدهد در واقع به دنبال پیدا کردنِ مقدارِ بهینه برای وزنها و انحراف است تا بتواند مرزهای مختلف را بین طبقههای متفاوت مثل پراید یا اتوبوس پیدا کند. در واقع کارِ اصلیِ شبکهی عصبی کم کردنِ مقدارِ تابعِ ضرر تا حد ممکن است. طبیعتاً ایده آل برای شبکهی عصبی مقدار ۰ است (یعنی بدون خطا) ولی در دروسِ بعدی میبینیم که این کار (به صفر رساندن مقدارِ تابعِ ضرر) در دنیای واقعی، غیر قابلِ اجرا است.

- ۱ » شبکه عصبی (Neural Network) چیست؟
- ۲ » تعریف پرسپترون (Perceptron) در شبکه های عصبی
- ۳ » پرسپترون در شبکه عصبی چگونه یاد میگیرد؟
- ۴ » پرسپترون چند لایه (Multi Layer Perceptron) چیست؟
- ۵ » درباره توابع فعال سازی پرسپترون و Sigmoid
- ۶ » تابع ضرر (Loss Function) در شبکه عصبی چیست و چه کاربردی دارد؟
- ۷ » نحوه یادگیری پس انتشار خطا (Back Propagation) در شبکه های عصبی
- ۸ » کاهش گرادیان (Gradient Descent) در شبکه های عصبی
- ۹ » حل یک مثال عددی یادگیری ماشین با شبکههای عصبی
همه ی آموزش هاتون عالیه
خدا خیرتون بده
لطفا ادامه بدید
عالی..عالی..عالی..
من کاملا دارم یاد میگیرم.
عالی درود خداوند بر دل پاک شما.موفق باشین همیشه.
سلام
مطالب رو خیلی خوب و کاربردی و ساده میگید. به قول یه دانشمندی کسی که نتونه یه مطلب رو ساده بیان کنه اصلا خودش اونو نفهمیده.
ممنون میشم در مورد ضریب همبستگی داده های آموزشی و داده های تست مطلب بزارید.
و اینکه بفرمایید راهی هست که الگوریتم وزن ها و بایاس اولیه رو بهتر اننتخاب کنه و در نهایت شبکه زودتر همگرا بشه>
سلام، بله شدنی هست
در دروس جدا به این روشها هم خواهیم پرداخت
این واقعا نبوغ رو میرسونه که بتونی مسائل سخت رو راحت توضیح بدی.
کارتون باارزش بود.
فوق الاده!
واقعا آموزش های بی نظیری دارید، من خیلی از آموزش هاتون استفاده کردم برای ارائه های دانشگاهیم. از اونجایی که در کنار درس مدیریت سایتی هم برعهده دارم، میدونم تعریف و نظرگذاشتن چقدر میتونه انرژی مثبت به نویسنده مطلب بده :)))
این کامنتو ارسال میکنم که شاید انگیزه مثبتی بشه و با قدرت بیشتر راهتون رو ادامه بدید. به امید روزی که مباحث رو در قالب ویدیو ارائه بدید.