

KMeans شاید سادهترین الگوریتمِ خوشهبندی باشد که در بسیاری از مواقع جزوِ بهترین الگوریتمهای خوشهبندی نیز هست. این الگوریتم از دسته الگوریتمهایی است که بایستی تعداد خوشهها (گروهها) را از قبل به او گفته باشیم. فرض کنید مانندِ درسِ شبکه های عصبی دو دسته داده داریم (پراید و اتوبوس) با این تفاوت که در یک مسئلهی خوشهبندی، نمیدانیم که کدام پراید است کدام اتوبوس؟ و فقط یک سری داده با دو ویژگی (طول ماشین و ارتفاع ماشین) در اختیار داریم. اجازه دهید اینبار این دو دسته را بدون دانستنِ برچسبِ آن ها بر روی نمودار رسم کنیم (برای اینکه بدانید چگونه این نمودار رسم می شود و بُعدهای مختلف آن چگونه ساخته میشود، درسِ شبکهی عصبی را خوانده باشید) به صورت ساده، ما یک تعداد ماشین (اتومبیل) داریم که هر کدام ارتفاع و طولِ مشخصی را دارند. آنها را به این گونه در دو بُعد در شکلِ زیر نمایش میدهیم):
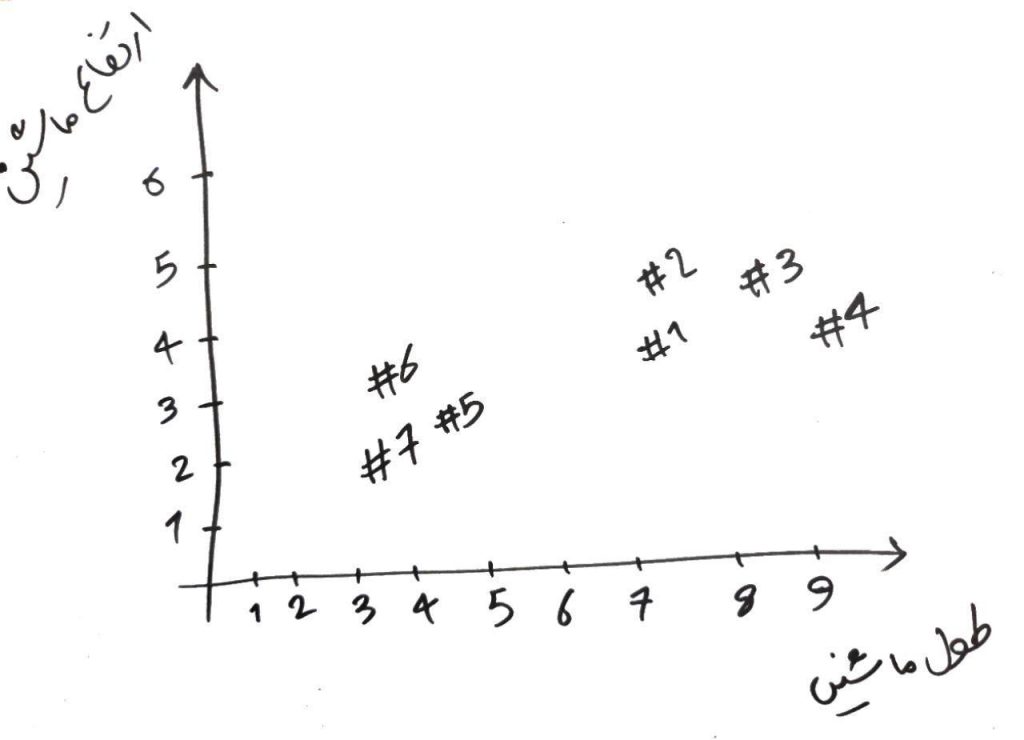
برای مثال، ماشین شمارهی ۴#، دارای طولِ ۹ و ارتفاع ۴ است. در الگوریتمِ KMeans بایستی تعدادی نقطه در فضا ایجاد کنیم. تعداد این نقاط باید به تعداد خوشههایی که میخواهیم در نهایت به آن برسیم، باشد (مثلاً فرض کنید میخواهیم دادهها را به ۲ خوشه تقسیمبندی کنیم، پس ۲ نقطه به صورت تصادفی در فضای ۲ بُعدیِ شکلِ بالا رسم میکنیم). شکل زیر را نگاه کنید:
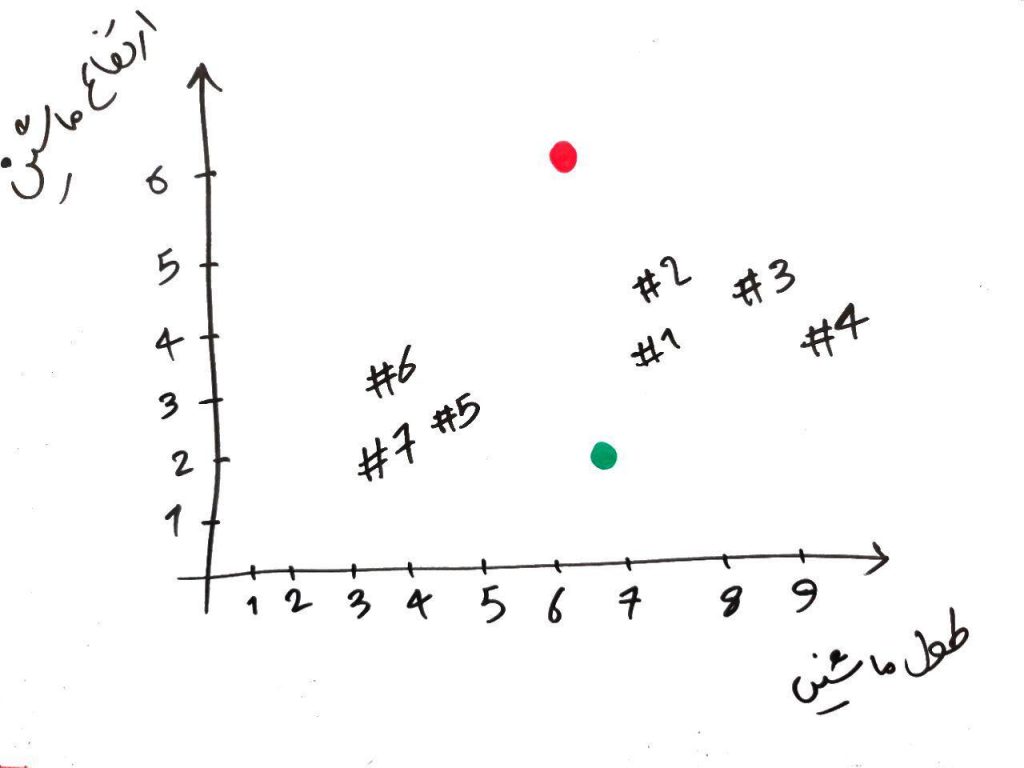
الان ما دو نقطهی سبز و قرمز را انتخاب کردیم و این دو نقطه را جایی در فضا (به صورت تصادفی) قرار دادیم. حال فاصلهی هر کدام از نمونهها را با این دو نقطه حساب میکنیم. برای این کار میتوانیم از فاصله منهتن (manhatan) استفاده کنیم (با فاصله منهتن در درس KNN آشنا شده اید). در واقع برای هر کدام از نمونهها نسبت به دو نقطهی سبز و قرمز در هر بُعد، مقایسه را انجام داده یعنی از هم کم (تفاضل) میکنیم، سپس نتیجهی کم کردنِ هر کدام از بُعدها را با یکدیگر جمع میکنیم.
بعد از محاسبهی فاصلهی هر کدام از نمونهها با دو نقطهی سبز و قرمز، برای هر نمونه، اگر آن نمونه به نقطهی سبز نزدیکتر بود، سبز میشود (یعنی به خوشهی سبزها تعلق پیدا میکند) و اگر به قرمز نزدیکتر بود به خوشهی قرمزها میرود. مانند شکل زیر برای مثال بالا:
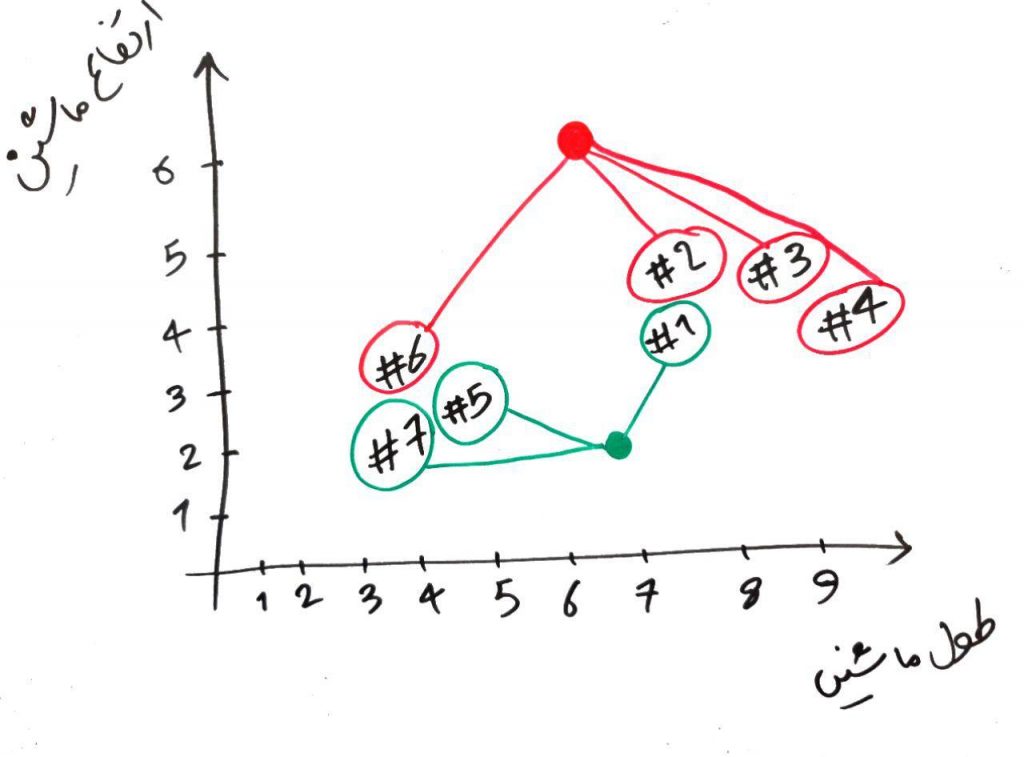
الان یک مرحله از الگوریتم را تمام کردهایم. یعنی یک دور از الگوریتم تمام شد و میتوانیم همین جا هم الگوریتم را تمام کنیم و نقاطی که سبز رنگ شدهاند را در خوشهی سبزها و نقاطی که قرمز رنگ شدهاند را در خوشهی قرمزها قرار دهیم. ولی الگوریتمِ KMeans را بایستی چندین مرتبه تکرار کرد. ما هم همین کار را انجام میدهیم. برای شروعِ مرحلهی بعد، باید نقطهی سبز و قرمز را جابهجا کنیم و به جایی ببریم که میانگینِ نمونههای مختلف در خوشهی مربوط به خودشان قرار دارد. مثلاً برای نقطه قرمز بایستی نقطه را به جایی ببریم که میانگینِ نمونههای قرمزِ دیگر (در مرحلهی قبلی) باشد. برای نقطه سبز هم همین طور. این کار را در شکل زیر انجام دادهایم:
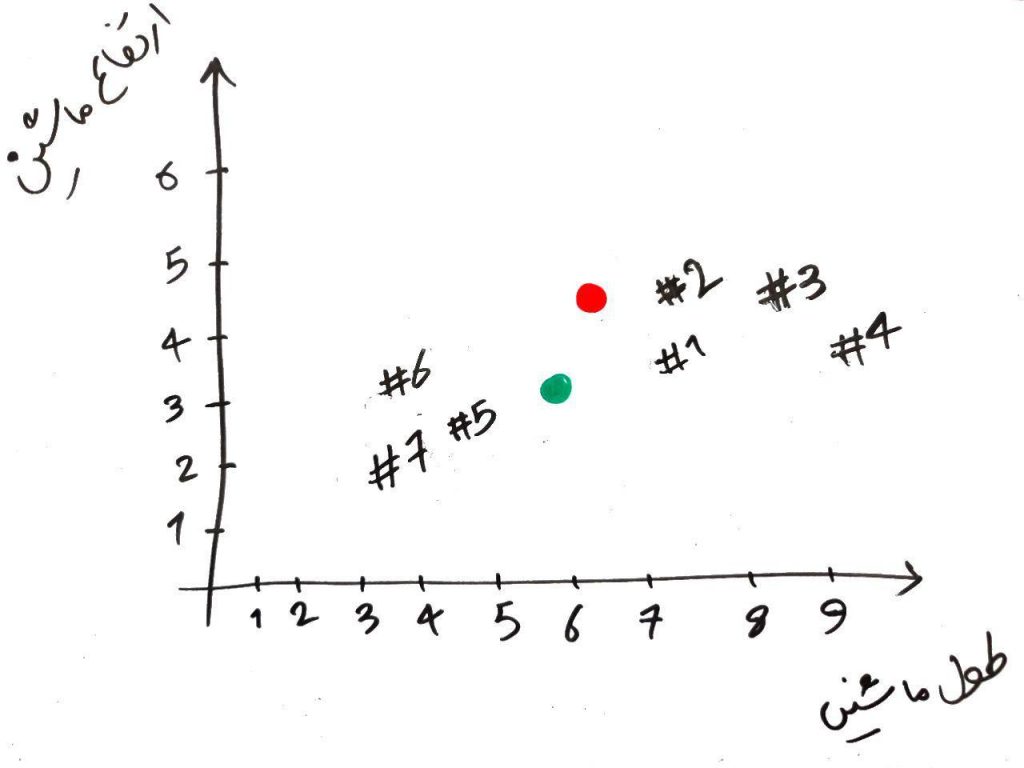
الان دو نقطهی قرمز و سبز جابهجا شدند و به مرکز خوشهی خودشان رفتند. حال بایستی دوباره تمامیِ نمونهها را هر کدام با دو نقطهی سبز و قرمز مقایسه کنیم و مانند دور قبلی، آن نمونههایی که به نقطهی قرمز نزدیکتر هستند، رنگ قرمز و آنهایی که به نقطهی سبز نزدیکتر هستند رنگِ سبز میگیرند. مانند شکل زیر:
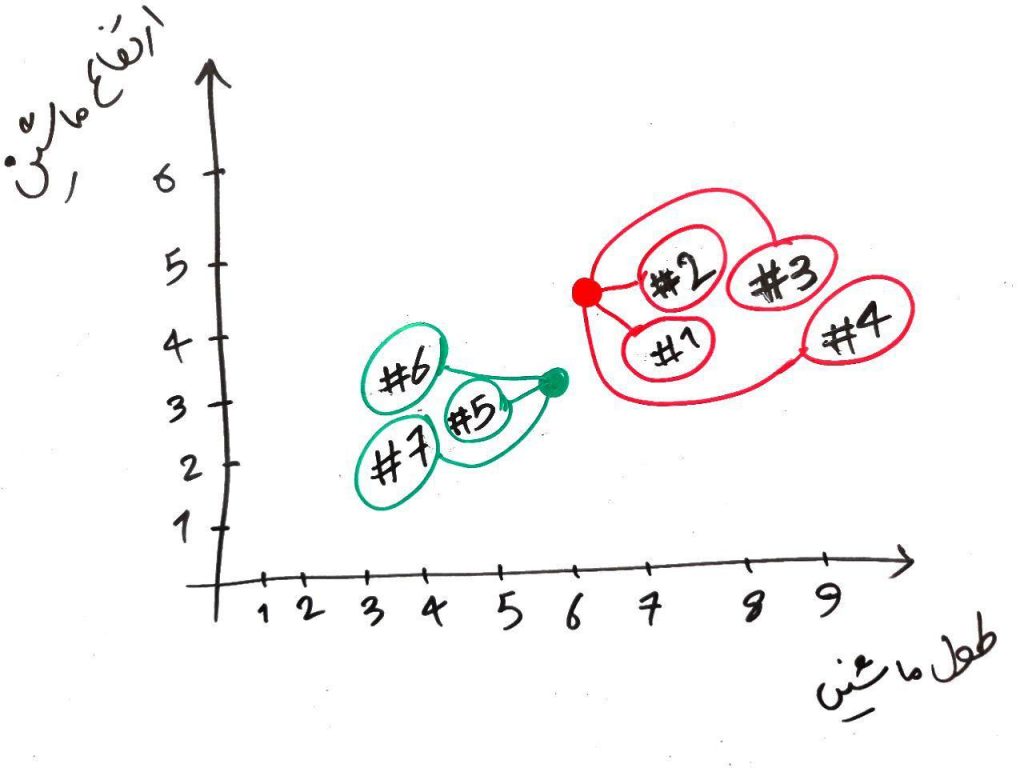
دورِ دوم نیز به اتمام رسید و به نظر الگوریتم خوشههای خوبی را تشخیص داد. ولی اجازه بدهید یک دور دیگر نیز الگوریتم را ادامه دهیم. مانند شکل زیر دور سوم نیز انجام میشود. یعنی نقاطِ قرمز و سبز به مرکز خوشهی خود (در مرحلهی قبلی) میروند و فاصلهی هر کدام از نمونهها دوباره با نقاطِ قرمز و سبز (در محلِ جدید) محاسبه شده و هر کدام همرنگِ نزدیکترین نقطهی قرمز یا سبز میشود:
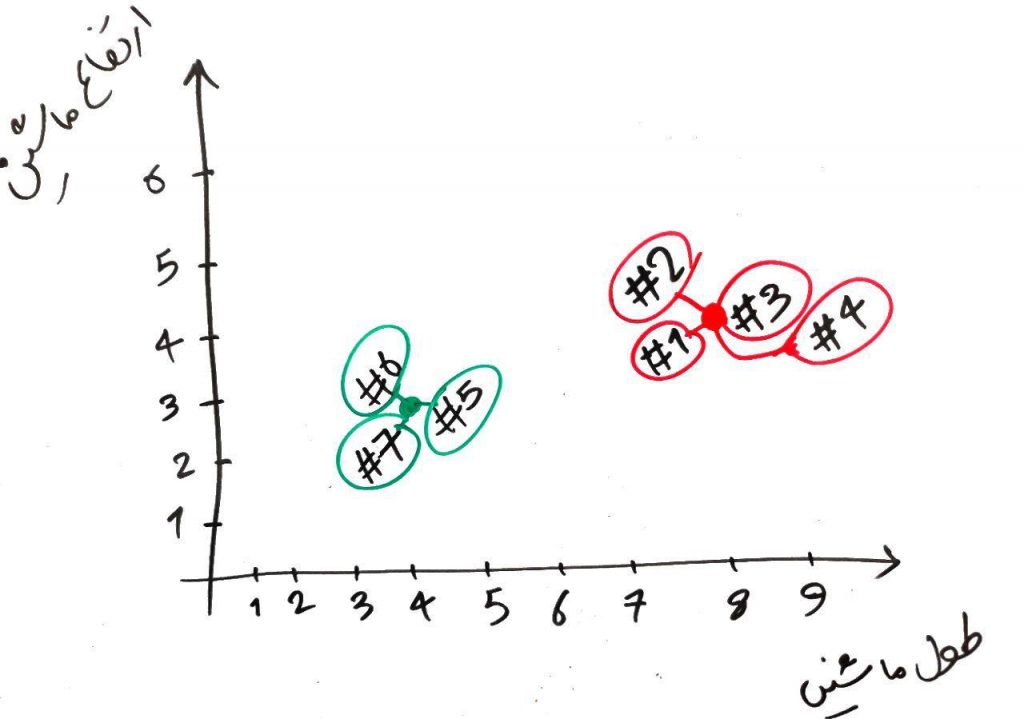
همان طور که میبینید در انتهای دورِ سوم، تغییری در خوشهی هر کدام از نمونهها رخ نداد. یعنی سبزها سبز ماندند و قرمزها، قرمز. این یکی از شروطی است که میتواند الگوریتم را خاتمه دهد. یعنی الگوریتم وقتی به این حالت رسید که در چند دورِ متوالی تغییری در خوشهی نمونهها (در اینجا ماشینها) به وجود نیامد، به ایم معنی است که الگوریتم دیگر نمیتواند زیاد تغییر کند و این حالتِ پایانی برای خوشههاست. البته میتوان شرطی دیگر نیز برای پایان الگوریتم در نظر گرفت. برای مثال الگوریتم حداکثر در ۲۰ دورِ متوالی میتواند عملیات را انجام دهد و دورِ ۲۰ام آخرین دورِ الگوریتم خواهد بود و الگوریتم، دیگر بیشتر از آن پیشروی نخواهد کرد. به طور کل در الگوریتمهای مبتنی بر تکرار (iterative algorithms) میتوان تعدادِ تکرارها را محدود کرد تا الگوریتم بینهایت تکرار نداشته باشد.
همان طور که دیدیم، این الگوریتم میتواند یک گروهبندیِ ذاتی برای دادهها بسازد، بدون اینکه برچسب دادهها یا نوع آنها را بداند.
کاربردهای خوشهبندی بسیار زیاد است. برای مثال فرض کنید میخواهید مشتریانِ خود را (که هر کدام دارای ویژگیهای مختلفی هستند) به خوشههای متفاوتی تقسیم کنید و هر کدام از خوشهها را به صورتِ جزئی مورد بررسی قرار دهید. ممکن است با مطالعهی خوشههایی از مشتریان به این نتیجه برسید که برخی از آنها (که معمولاً در یک خوشه قرار میگیرند)، علیرغم خرید با توالیِ زیاد، در هر بار خرید پول کمتری خرج میکنند. با این تحلیلهایی که از خوشهبندی به دست میآید یک مدیرِ کسب و کار میتواند به تحلیلدادهها و سپس تصمیمگیریِ درستتری برسد.

سلام وقت بخیر خیلی ممنون از مطلب خوبتون
من دانشجو مدیریت it دوست دارم در زمینه هوش مصنوعی و دیتاماینینگ روی فضای دیجیتال مارکتینگ وبورس کار کنم ومقالاتی در این مورد دیدم .ممکن راهنمایی کنید از کجا مطلب بخونم در موردآشنایی با این مسائل؟
سلام وقت شما بخیر. ممنون از مطالب خوبتون.
ببخشید میشه لطفا توضیحاتی در مورد weighted kmean هم بفرمایید اینکه دقیقا چه فرقی با kmean داره؟ به چه صورت عمل میکنه و اینکه با وزن دار کردن نقاط چه تاثیری روی عملکرد الگوریتم ایجاد میشه؟؟
ممنون میشم اگر در این مورد راهنمایی بفرمایید.
با تشکر.
سلام فقط میخواستم تشکر کنم بسیار عالی توضیح دادید. جوری که کسی که هیچ چیز از این حوزه نمیدونه هم کارش راه بیفته. واقعا ممنون
سلام واقعا عالی بود ولی کاش از مزایا ومعایب این روش هم میگفتین
و اینکه کاش با کد هم حالا به هر زبانی ازش مثال میزدید
سلام
بسیار ساده و روان بیان شده بود.
با سپاس
عااالی واقعا من چی میتونم بگم هر چیزی رو آنقدر واضح توضیح میدید که من تا بحال ندیدم کسی اینطور توضیح بده
سلام عالی بود عالی خیلی ممنونم فقط اگر لطف کنید همگام با همین نراحلی که گفتید کدنویسی در زبان پایتون اس را هم قرار بدید خیلی عالی و کامل تر میشه ممنون
سپاس از توضیحتون🙏🏻🌸
انتقال مفهوم با توضیحات ساده ، نشان از خرد در موضوع مرتبط میباشد.
سپاس از شما
سلام آقای دکتر کاویانی
وقت بخیر
توضیحات خیلی واضح است می توانم خواهش کنم خوشه بندی K-MEANS با فاصله اقلیدسی توضیح بدهید ؟
توضیحات عالی بود و با مثال قابل فهم تر سپاس از شما
با سلام و تشکر از جنابعالی بابت تفهیم مطالب
موضوع پایان نامه بنده در خصوص کشف تلقب با استفادا از داده کاوی است . و از خوشه بندی kmeanse میخوام استفاده کنم. کدوم نرم افزار مناسب هست برای ساخت یک مدل