

فرض کنید در یک سیستم توزیع شده اطلاعات دانشجویان هستید و ۱۰عدد کامپیوتر در اختیار دارید. اطلاعات این دانشجویان سراسر کشور در این ۱۰کامپیوتر قرار داده شده است (که با خاطر اینکه در یک سیستم گنجایش نداشته). حال فرض کنید بخواهید اطلاعات مختلف یک دانشجو (مثلا به اسم جواد ظریف) را پیدا کنید. ساده است که در نگاه اول بایستی از کامپیوتر شماره ۱ شروع کرده و یکی یکی به دنبال این دانشجو بگردید، و یا به صورت موازی به هر ۱۰کامپیوتر درخواستی ارسال کنید.
اگر ۱۰۰۰کامپیوتر داشتید و میخواستید درون هر یک از آن ها به دنبال اسم جواد ظریف بگردید چه؟ آیا این کار از منطقی به نظر میرسید؟ قطعا خیر. ایده آل ما این است که فقط به یک کامپیوتر درخواست را ارسال کنیم. این کامپیوتر در پایگاه داده خود به دنبال اطلاعات ذخیره شده برای جواد ظریف میگردد و می تواند اطلاعات این فرد را نمایش دهد. بقیه ی کامپیوترها نیز کار خود را انجام میدهند (چون میدانیم که آن ها اطلاعات این دانشجو را ندارند).
برای دست یابی به این هدف، میتوانیم از تابع درهم ساز (Hash Functions) استفاده کنیم. مثال بالا را در نظر بگیرید. ۱۰ کامپیوتر داریم و ۲۰میلیون رکورد اطلاعات دانشجو. میخواهیم از یک تابع درهم ساز استفاده کنیم که بتواند به ما بگوید که اطلاعات هر دانشجو در کجا بایستی ذخیره شود. فرض کنید تابع درهم ساز به صورت است که نام یک دانشجو را میگیرد و آن را به یکی از اعداد بین ۰ تا ۱۰ (تعداد کامپیوترها) تبدیل میکند. پس هر کدام از دانشجو ها به یکی از کامپیوترها اختصاص داده می شود و اگر تابع درهم ساز متوازن باشد هر کامپیوتر حدودا ۲میلیون رکورد دانشجو را در خود نگهداری می کند. حال اگر بخواهیم به دنبال دانشجو به اسم جواد ظریف بگردیم، این اسم را به تابع درهم سازی که داریم می دهیم. این تابع به ما میگوید که به مثلا به کامپیوتر شماره ۲ برو (چون اطلاعات این داشنجو در این کامپیوتر قرار دارد). پس ما درخواست واکشی اطلاعات دانشجو را به کامپیوتر شماره ۲ میدهیم و این کامیپوتر بعد از جستجو در پایگاه داده خود میتواند اطلاعات مربوط به جواد ظریف را برای ما برگرداند. میتوانیم این اطلاعات را در یک جدول درهم ساز (Hash Table) قرار دهیم تا نیاز به محاسبه تابع درهم ساز، برای هر خانه نداشته باشیم.
تا اینجای کار همه چیز خوب جلو میرود، مگر اینکه کامپیوتری که دارای اطلاعات جواد ظریف است، به دلیلی از کار بیوفتد. در درس سیستم های توزیع شده یادگرفتیم که یکی از اهداف سیستم توزیع شده شفافیت خرابی است. به این معنی که اگر یکی از سیستم ها به دلیلی خراب شود، سیستم نباید از کار بیوفتد. ولی در مثال بالا، این اتفاق خواهد افتاد. پس به دنبال راهکاری هستیم که بتوانیم اطلاعات یک دانشجوی خاص را در صورت نیاز دریافت کنیم. برای این کار راه حلی ساده به نظر می رسد. اینکه اطلاعات مختلف به جای اینکه فقط در یک کامپیوتر ذخیره شوند، در چندین کامپیوتر ذخیره شوند. مثلا اطلاعات دانشجو جواد ظریف به جای اینکه فقط در کامپیوتر شماره ۲ ذخیره شود، در کامیپوتر ۴ و ۸ نیز ذخیره شود. با این کار اگر درخواست واکشی اطلاعات به کامپیوتر شماره ۲ رد شد، درخواست میداند که باید سراغ کامپیوتر شماره ۴ بروند. اگر کامپیوتر ۴نیز خراب بود و درخواست رد شد، باید به سراغ کامپیوتر شماره ۸ برویم و اطلاعات را واکشی کنیم. میدانیم که احتمال خراب بودن هر سه کامپیوتر در یک زمان خیلی کمتر از حالت قبل است. پس کل سیستم، ثبات بیشتری برای پاسخ دارد.
اینجاست که جدول درهم ساز توزیع شده (Distributed Hash Table) به کار می آید. جدول درهم ساز توزیع شده مانند همان جدول توزیع شده ساده است. فقط توانایی این را دارد که داده های زیاد را بر روی چندین کامپیوتر (به صورت کپی) رهگیری کند. این جداول کمک میکنند تا در هنگام اضافه و کم کردن کامپیوتر به سیستم، مشکلی در سیستم به وجود نیاید. در مثال بالا، فرض کنید کامپیوتر شماره ۳ برای همیشه از کار افتاد و ما خواستیم ۲کامپیوتر دیگر به شماره های ۱۱ و ۱۲ سیستم اضافه کنیم. واضح است که اگر بخواهیم این کار را انجام دهیم، یک سری اطلاعات باید در سیستم جا به جا شود. یه نحوه ساده از این جا به جایی در شکل زیر قابل مشاهده است:
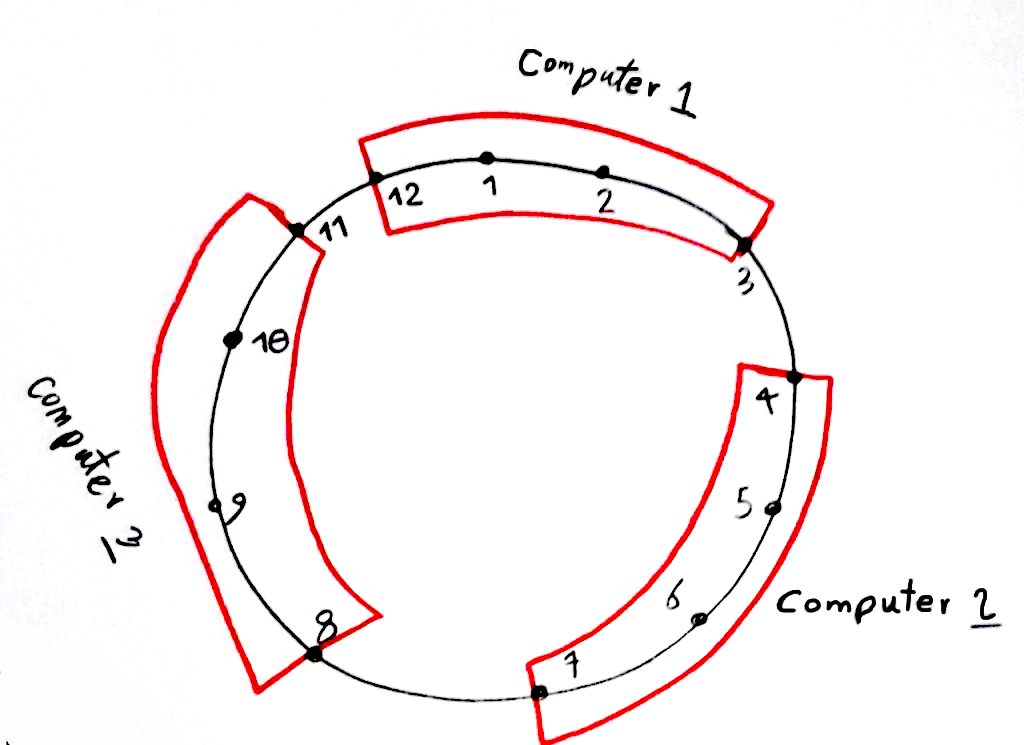
در تصویر بالا فرض کنید که ما ۱۲ نقطه داریم، که هر دانشجو به یک یا چند تا از این ۱۲ نقطه نگاشت می شود (با همان تابع درهم ساز که بالا توضیح داده شد)، مثلا جواد ظریف به نقطه شماره ۲ و ۴ و ۸ نگاشت می شود (به این معنی که اگر اطلاعات مربوط به این دانشجو را خواستیم در یکی از این نقطه ها قابل دستیابی است). سپس همان طور که مشاهد می کنید ۳کامپیوتر داریم که هر کدام از این کامپیوتر ها ۴نقطه را پوشش می دهند. یعنی اگر بخواهیم به نقطه شماره ۲ دسترسی داشته باشیم، بایستی به کامپیوتر شماره ۱ درخواست بدهیم. با این کار، اضافه و حذف یک یا چند کامپیوتر ساده تر می شود. مثلا اگر کامپیوتر ۱ را بخواهیم حذف کنیم، کامپیوترهای شماره ۲ و ۳ باید بازه ی نقاط خود را گسترش داده و نقاط ۱۲، ۱، ۲ و ۳ را پوشش دهند. مثلا در اینجا کامپیوتر شماره ۲، باید نقاط ۲ و ۳ را پوشش دهد و کامپیوتر شماره ۳ باید تقاط ۱۲ و ۱ را پوشش دهد. با این کار عملیات حذف و اضافه کردن کامپیوترها آسان تر انجام می شود. همچنین کپی های مختلفی از داده ها در روی چندین کامپیوتر قرار داده شده است و میتوان این اطمینان را داشت که در صورت خراب شدن یک کامپیوتر، متیوان داده های آن را در سیستم های مختلف پیدا کرد.

افرین چقدر قشنگ توضیح داده
همین کارهای کوچک باعث رشد بزرگ میشود.
اگر ممکنه طریقه پیاده سازیش هم برامون بزارید(اگر ممکنه با زبان جاوا)
سلام وقت شما بخیر ممنونم از مطالب بسیار عالی و مفید
اگه مقدور هست جسنجو درج و حذف رو بصورت فرمولی بیان فرمایید.با سپاس فراوان
بنده هم به اندازه ی خودم از شما تشکر میکنم بابت توضیح عالی تون
مرسی از توضیحات خوبتون
عالی
مهمترین وجه این متن سادگی بیان است که نشان از مهارت کافی نویسنده می دهد
منظورش از کامپیوتر و نقطه چیه؟
ممنون از متن پر محتواتون
اگر ممکن است توضیح بدین || چه کاربردی دارد مثلا وقتی برای رمزنگاری MAC مینویسیم E(x) = (m||h(m) این علامت بنوعی تابع را نشون می دهد یا فشرده سازی بیت ها؟
یه چیزی توی این توضیحات بهم نمیخوره در مثار های بالا تر از شکل هر نود یک کامیپوتر تصور شده اما در مثال پایین هر کامیپوتر متشکل از چند نود هست بدون هیچ توضیح مشخصی. بالاخره هر کامیپوتر یک نود درونش داره یا چند تا…؟!
بعدم توابع درهم ساز نباید یه تغییری توشون بوجود بیاد ک بتونه پشتیبانی کنه از وجود کپی ی دادهمثلا بجای یکخروجی دویا چند تا بده .
مثلا بده ۲ ۴ و ۸ به ازای مثلا دانشجو زهرا زهرایی ؟