

فرض کنید، شما یک فروشگاه بزرگِ موادغذایی دارید و مشتریانِ این فروشگاه که بالغ بر ۱۰۰ هزار نفر هستند ویژگیهای مختلفی دارند. اجازه دهید، سه ویژگیِ زیر را برای یک مشتریِ خاص از مشتریان این فروشگاهِ بزرگ موادغذایی در نظر بگیریم (بقیهی مشتریان نیز این ویژگیها را دارند):
۱. این مشتری آخرین خریدِ خود را چند روز پیش انجام داده است؟ (که با R نام گذاری میکنیم)
۲. این مشتری در یکسالِ گذشته، به طورِ میانگین چند روز یک بار از فروشگاه ما خرید کرده است؟ (که با F نام گذاری میکنیم)
۳. این مشتری در یکسالِ گذشته به طورِ میانگین در هر بار خرید، چه مبلغی از فروشگاه خرید کرده است؟ (که با M نامگذاری میکنیم)
حال به جدول زیر که نوعی ماتریس است نگاهی بیندازید. اینها قسمتی از دادههای ما هستند:
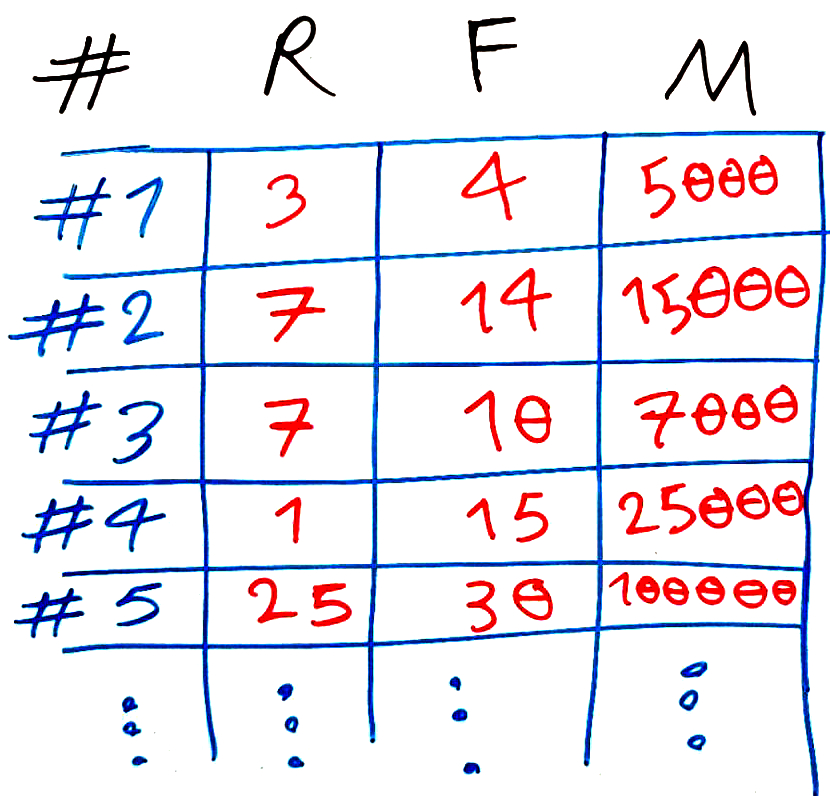
هر سطر در این جدول، یک مشتری را نشان میدهد. ستونهای R و F و M به ترتیب سه ویژگی یا سه بُعدِ مسئله ما را تشکیل میدهند که مطابق با سه ویژگیِ گفته شده در بالا است. اینها ۵ نمونه از ۱۰۰ هزار مشتریِ فروشگاه ما را تشکیل می دهند که در جدول بالا نمایش داده شده است. به فرد شماره ۱ توجه کنید: این فرد ۳ روز گذشته آخرین خرید خود را انجام داده است (ویژگی R). در یکسال گذشته به طور میانگین هر ۴ روز یکبار خرید انجام داده (ویژگی F). و به طورِ میانگین در یکسال گذشته در هر خرید ۵۰۰۰ تومان خرید کرده است. بقیهی مشتریان را هم میتوانید به همین ترتیب تفسیر کنید.
از لحاظِ کسب و کار قطعاً میدانید که نباید با تمامی مشتریان به یک صورت برخورد کنید. پس نیاز دارید تا بینِ گروهِ مشتریانِ مختلفِ خود تمایز قائل شوید. برای این کار میتوانید از الگوریتمهای خوشهبندی (clustering) یا همان یادگیری غیرنظارت شده (unsupervised learning) استفاده کنید. این الگوریتمها میتوانند با استفاده از ویژگیها یا همان ابعادِ مسئله (در اینجا R و F و M) گروههای مختلفی از نمونههایی را که شبیه به هم هستند، پیدا کنند. مثلا فرض کنید از الگوریتم معروف KMeans استفاده میکنیم. این الگوریتم تعداد گروهها (خوشهها) را از شما میخواهد، شما عدد ۸ را به الگوریتم میدهید، به این معنی که میخواهید الگوریتم ۱۰۰ هزار مشتریِ شما را به ۸ گروه یا همان ۸ خوشه تقسیم نماید، به صورتی که مشتریان در یک گروه، به یکدیگر شباهتهای زیادی داشته باشند. مثلاً فرض کنید یکی از این ۸ گروه (که الگوریتم KMeans تقسیم بندی کرده است) حدوده ۱۵ هزار مشتری دارد که معمولاً دارای M و F بالایی هستند. به این معنی که این گروه پول زیادی در هر خرید خرج می کنند (مثلاً هر بار حدود ۱۲۰ هزار تومان – ویژگی M)، ولی دوره برگشتشان به فروشگاه طولانی است (مثلاً هر ۳۰ روز یکبار به فروشگاه مراجعه میکنند – ویژگی F). پس ما از میان دادههایمان توانستیم چندین خوشه یا گروه استخراج کنیم که یکی از این خوشهها ویژگی F و M بالایی داشت. حال میتوان برای این خوشه تصمیمِ مشخصی گرفت. برای مثال احتمالاً این خوشه بیشتر احتیاج به مایع ظرفشویی بزرگ دارد تا یک مایع ظرفشویی کوچک، زیرا معمولاً مشتریانِ این خوشه خریدهایی با مبلغ بالا برای مدت طولانی انجام میدهد، پس میتوان در یک تبلیغ پیامکی، اجناسِ بزرگ (مانند مایعِ ظرفشوییِ چند کیلویی) را برای این گروه از مخاطبان فرستاد. در واقع نوعی هوشمندی در کسب و کار با استفاده از خوشهبندی ارائه شده است.
این یک مثال از خوشهبندی بود. همانطور که در درس طبقهبندی (classification) متوجه شدید، در طبقهبندی یک ستونِ برچسب (lable) داریم در حالی که در خوشهبندی این ستونِ برچسب وجود ندارد. در واقع الگوریتمها و روشهای خوشهبندی، میتوانند به صورتِ غیرِنظارتشده و بدونِ استفاده از برچسب، عملیاتِ خوشهبندی را با استفاده از ویژگیهای مختلفِ مسئله انجام دهند. به عبارت سادهتر خوشهبندی یک نوع تقسیمبندیِ دادهها با توجه به الگوها یا همان patterns ذاتیِ دادهها است.
الگوریتمهای مختلف خوشهبندی مانند KMeans، DB Scan، OPTICS و… وجود دارند که در دورهی خوشهبندی به آنها خواهیم پرداخت.

- ۱ » دادهکاوی (Data mining) چیست؟
- ۲ » یادگیری ماشین (Machine Learning) چیست؟
- ۳ » تفاوت هوش مصنوعی، یادگیری ماشین، دادهکاوی، یادگیری عمیق و علم داده
- ۴ » طبقهبندی (Classification) چیست؟
- ۵ » خوشهبندی (Clustering) چیست؟
- ۶ » تفاوت طبقهبندی (Classification) و خوشهبندی (Clustering)
- ۷ » منظور از دادههای آموزشی (Training Sets) در طبقهبندی چیست؟
- ۸ » سیستم توصیه گر (Recommendation System) چیست؟
- ۹ » کاربرد دادهکاوی و یادگیری ماشین در پردازش متن (Text Processing)
- ۱۰ » معرفی چند نرم افزار کاربردی برای عملیات دادهکاوی
- ۱۱ » ویژگی (Feature) یا همان بُعد (Dimension) در دادهکاوی چیست؟
- ۱۲ » بررسی چند الگوریتم یادگیری ماشین (Machine Learning)
- ۱۳ » یادگیری دستهای (Batch Learning) و یادگیری برخط (Online Learning)
- ۱۴ » یادگیری فعال (Active Learning) در یادگیری ماشین
- ۱۵ » انتخاب ویژگی (Feature Selection) چیست؟
- ۱۶ » تفاوت داده ساختاریافته (Structured) با غیرساختاریافته (Unstructured) چیست؟
- ۱۷ » منظور از متغیر وابسته (Dependent) و مستقل (Independent)
- ۱۸ » مجموعه دادههایی با ابعاد زیاد (High Dimensional)
- ۱۹ » مجموعه دادهی نامتوازن (Imbalance) چیست؟
- ۲۰ » فرآیند کریسپ (CRISP) جهت انجام پروژههای دادهکاوی
- ۲۱ » رانش یا گذار در دادهها (Data Drift)
با سلام
توضیح ساده و بسیار قابل فهمی از مفهوم خوشه بندی اراءه نموده اید در متن که بسیار عالی ایت و برای کاربرانی که از نظر علم داده کاوی مبتدی هستن بسیار مفید وقابل درک است…
سپاس
عالي بود. مرسي
خوب و بسیار واضح بود و ترم رو بخوبی میرسونه….
کاملا موافقم
بسیار عالی بود متشکرم
با سلام و درود
یک سوالی از خدمت شما داشتم.
من یک ست دیتا دارم و قصد دارم جوری آن ها را خوشه بندی کنم که داده هایی که روی خطوط با شیب ۱ قرار می گیرند، در یک خوشه مجزا قرار بگیرند. منظورم این هست که چند خوشه تولید بشه که در هر خوشه، همه داده ها روی خط راست با شیب یک هستند.
آیا روش خوشه بندی خاصی هست؟
امکانش هست منبع یا روشی برای مطالعه معرفی کنید؟
در ضمن رشته من مهندسی نفت هست.
با تشکر
برای این کار به نظر روش Spectral Clusterin و همچنین DBSCAN و یا MeanShift مناسب به نظر میرسد. ولی بایستی الگوریتمهای مختلف را امتحان کرده و با توجه به دادههای خود، بهترین الگوریتم را انتخاب کنید
توضیحات ساده و قابل درک. عالی بود.
خیلی خوب و کاربردی بود..عاالی
خیلی خوب و روان
با سلام
در بازارهای بورس از کدام روش داده کاوی میتوان استفاد کرد؟
سلام
عالی بود…ممنون
سلام.
توضیحات کامل و بسیار ساده و قابل فهم بود
ممنون
با سلام
روی داده های کوچک میتوان از داده کاوی استفاده کرد؟ من یک مجموعه داده در حدود ۱۵۰ رکورد درحوزه سلامت دارم و میخوام اثر تک تک متغیر ها روی بیماری بررسی و درنهایت الگوهای خاصی طراحی کنم که افراد با چه ویژگی ها چه درمانی در آنها جواب می دهد؟
سلام
بله مشکلی نیست
یکی از دیتاستهای مرجع (iris) در این حوزه هم ۱۵۰ رکورد دارد و به خوبی الگوریتمهای مختلف بر روی آن جواب میدهد
سلام. خیلی خوب و همراه با مثال های ملموس… تشکر
خیلی عالی و واضح و مفهوم.خدا خیرتون بده
بسیار عالی و روان بود ، لذت بردیم ممنون
با عرض سلام و خسته نباشید. متن بسیار روان و قابل درک بود. سپاس فراوان بابت زحمات شما
سلام.وبسایت جامعی دارید.دست گلتون درد نکنه
چقدر خوب و روان توصیح دادین. عالی بود. ممنون
استاد مرسی مرسی مرسی..عالی بود..سر کلاس که خود استاد هم فکر نکنم فهمیده باشه چی درس داده
من بعد از کلی گشت زدن توی نت بالاخره یه سایت پیدا کردم که همه چیز درباره ی داده کاوی رو از بیس و روان توضیح بده..خدا قوت .ایشالله باز هم مطالبی به این خوبی و قابل فهمی برای مبتدیان(دانشجویان) قرار بدید.